
微信公眾號開發--普通表情與emoji表情的處理
阿新 • • 發佈:2019-01-30
隨著表情的大量使用,在微信開發中,開發人員不得不考慮對錶情的處理。
微信上的表情大致可以分為三類。
第一類是收藏的表情,像下面這樣的
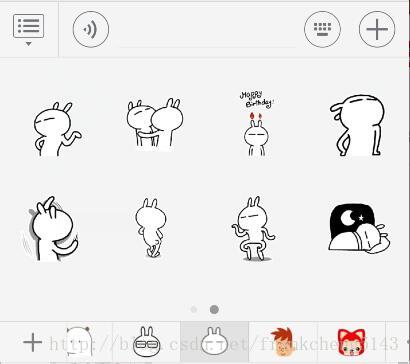

這種表情從微信端發到伺服器是這樣的

這類表情無法處理。
另一類是微信自帶的表情
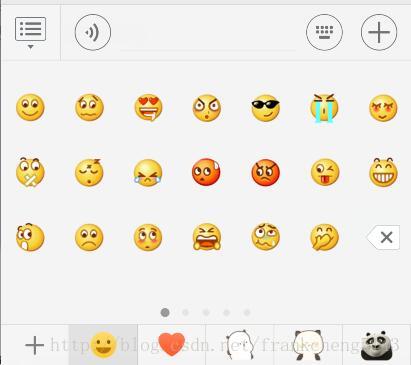
這類表情發過來是符號,比如第一個微笑表情發過來是這個符號/::)
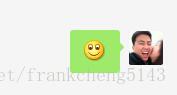
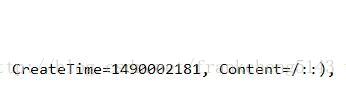
最後一類是emoji表情,emoji表情在java都是不可見編碼,發過看到的是一個像空格一樣的。

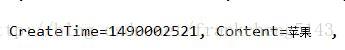
第一類表情無法處理,只能丟棄掉,而且微信發第一類表情的時候是無法同時發文字和表情的,只能發一個表情,所以對業務影響也不大。
第二類表情和第三類表情可以歸為同一類,只不過第三類我們看不到,一旦對其進行編碼,就能看到了。
處理表情的思路就是做一個編碼表。

對於不可見的emoji可以用Unicode區分
emoji的unicode對照表參考
第二類表情已經有人整理好了
參考
缺少幾個表情
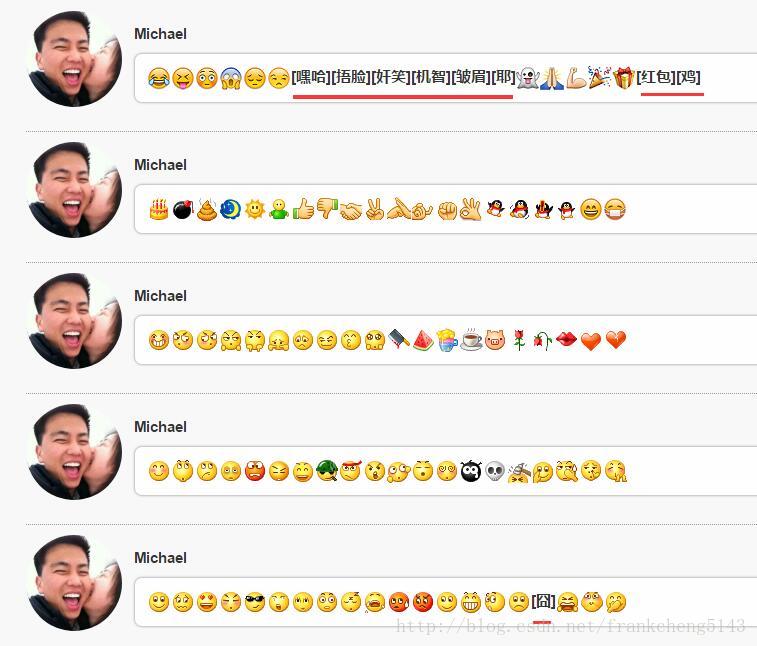
到目前,微信自帶的表情(2017年3月21日)有99個,微信預設表情程式碼和圖片包中還有9個表情沒有。
不過在微信web版裡也沒有那9個表情,我也沒有找到那幾個表情的資原始檔,我通過截圖把剩下的9個自帶表情加了進去,還望知道微信官方表情包下載地址資原始檔的告知一下。
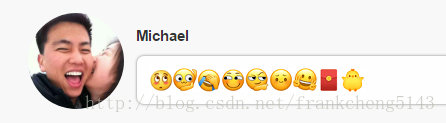
emoji表情微信預設表情程式碼和圖片包已經給了部分emoji表情以及對應關係。完全是體力活,剩下的emoji表情就不一一添加了。
一些emoji表情的截圖,這種像口的不可見字元可以通過Unicode檢視不同。
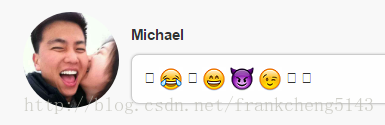
缺失的表情
#缺失的那9張表情
[囧]=<img class="wechat-emoji" src="/jrbac/assets/image/emoji/wechat/jiong.png" alt="囧">
[嘿哈]=<img class="wechat-emoji" src="/jrbac/assets/image/emoji/wechat/heiha.png" alt="嘿哈">
[捂臉]=<img class="wechat-emoji" src="/jrbac/assets/image/emoji/wechat/wulian.png" emoji
如何判斷一句話中哪些是emoji哪些是文字呢?這裡提供一個工具類,工具類中是將emoji轉換為unicode編碼,可以將其替換為圖片,或者用空格過濾掉。
package com.jrbac.util;
import java.util.Formatter;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EmojiUtil {
/**
* 顯示不可見字元的Unicode
*
* @param input
* @return
*/
public static String escapeUnicode(String input) {
StringBuilder sb = new StringBuilder(input.length());
@SuppressWarnings("resource")
Formatter format = new Formatter(sb);
for (char c : input.toCharArray()) {
if (c < 128) {
sb.append(c);
} else {
format.format("\\u%04x", (int) c);
}
}
return sb.toString();
}
/**
* 將emoji替換為unicode
*
* @param source
* @return
*/
public static String filterEmoji(String source) {
if (source != null) {
Pattern emoji = Pattern.compile("[\ue000-\uefff]", Pattern.CASE_INSENSITIVE);
Matcher emojiMatcher = emoji.matcher(source);
Map<String, String> tmpMap = new HashMap<>();
while (emojiMatcher.find()) {
// System.out.println(escapeUnicode(emojiMatcher.group()));
// System.out.println(emojiMatcher.start());
String key = emojiMatcher.group();
String value = escapeUnicode(emojiMatcher.group());
//System.out.println("key:" + key);
//System.out.println("value:" + value);
tmpMap.put(key, value);
// source =
// emojiMatcher.replaceAll(escapeUnicode(emojiMatcher.group()));
}
if (!tmpMap.isEmpty()) {
for (Map.Entry<String, String> entry : tmpMap.entrySet()) {
String key = entry.getKey().toString();
String value = entry.getValue().toString();
source = source.replace(key, value);
}
}
}
return source;
}
}
測試
package com.jrbac.util;
import org.junit.Test;
public class EmojiTest {
@Test
public void testEmoji() {
String source = "基本表情/::)emoji蘋果emoji麵包";
String unicode = EmojiUtil.escapeUnicode(source);
System.out.println("原始字串:"+source);
System.out.println("unicode編碼:"+unicode);
String replace = EmojiUtil.filterEmoji(source);
System.out.println("替換後的字串:"+replace);
}
}
效果
