Spark實踐 | spark2.2.0安裝與部署
安裝之前的準備
下載並解壓spark
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C ~/mv spark-2.2.0-bin-hadoop2.7/ spark-2.2.0安裝scala
sudo tar -zxvf /mnt/hgfs/share/scala-2.12.2.tgz -C /usr/libvim /etc/profileexport SCALA_HOME=/usr/lib/scala-2.12.2
export PATH=$PATH:${SCALA_HOME}/binsource /etc/profile
配置環境變數
Ubuntu並沒有自帶vim,我們需要先安裝,
vim更好用
sudo apt-get install vim然後開始配置
vim /etc/profile末尾插入
export SPARK_HOME=/home/jackherrick/spark-2.2.0
export PATH=$PATH:$SPARK_HOME/bin配置Spark環境
開啟spark-2.2.0資料夾
cd spark-2.2.0此處需要配置的檔案為兩個
spark-env.sh和slaves

首先我們把快取的檔案spark-env.sh.template和·slaves.template
spark-env.sh和slaves
修改spark-env.sh檔案
vim spark-env.sh在結尾引入
export JAVA_HOME=/usr/lib/jdk1.8.0_131
export SCALA_HOME=/usr/lib/scala-2.11.7
export HADOOP_HOME=/home/jackherrick/hadoop-2.7.3
export HADOOP_CONF_DIR=/home/jackherrick/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_IP=SparkMaster
export 變數說明
- JAVA_HOME:Java安裝目錄
- SCALA_HOME:Scala安裝目錄
- HADOOP_HOME:hadoop安裝目錄
- HADOOP_CONF_DIR:hadoop叢集的配置檔案的目錄
- SPARK_MASTER_IP:spark叢集的Master節點的ip地址
- SPARK_WORKER_MEMORY:每個worker節點能夠最大分配給exectors的記憶體大小
- SPARK_WORKER_CORES:每個worker節點所佔有的CPU核數目
- SPARK_WORKER_INSTANCES:每臺機器上開啟的worker節點的數目
vim slavesslave1
slave2同步SparkWorker1和SparkWorker2的配置
在此我們使用rsync命令
rsync -av /home/jackherrick/spark-2.2.0/ slave1:/home/jackherrick/spark-2.2.0/
rsync -av /home/jackherrick/spark-2.2.0/ slave2:/home/jackherrick/spark-2.2.0/ 啟動Spark叢集
因為我們只需要使用hadoop的HDFS檔案系統,所以我們並不用把hadoop全部功能都啟動。
啟動hadoop的HDFS檔案系統
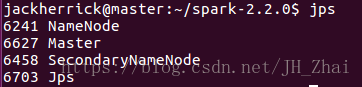
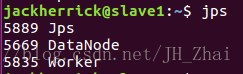
start-dfs.sh檢視叢集中結點對應的datanode namenode
啟動Spark
因為hadoop/sbin以及spark/sbin均配置到了系統的環境中,它們同一個資料夾下存在同樣的start-all.sh檔案。最好是開啟spark-2.2.0,在資料夾下面開啟該檔案。
./sbin/start-all.shMaster結點多了Master slave結點多了Worker
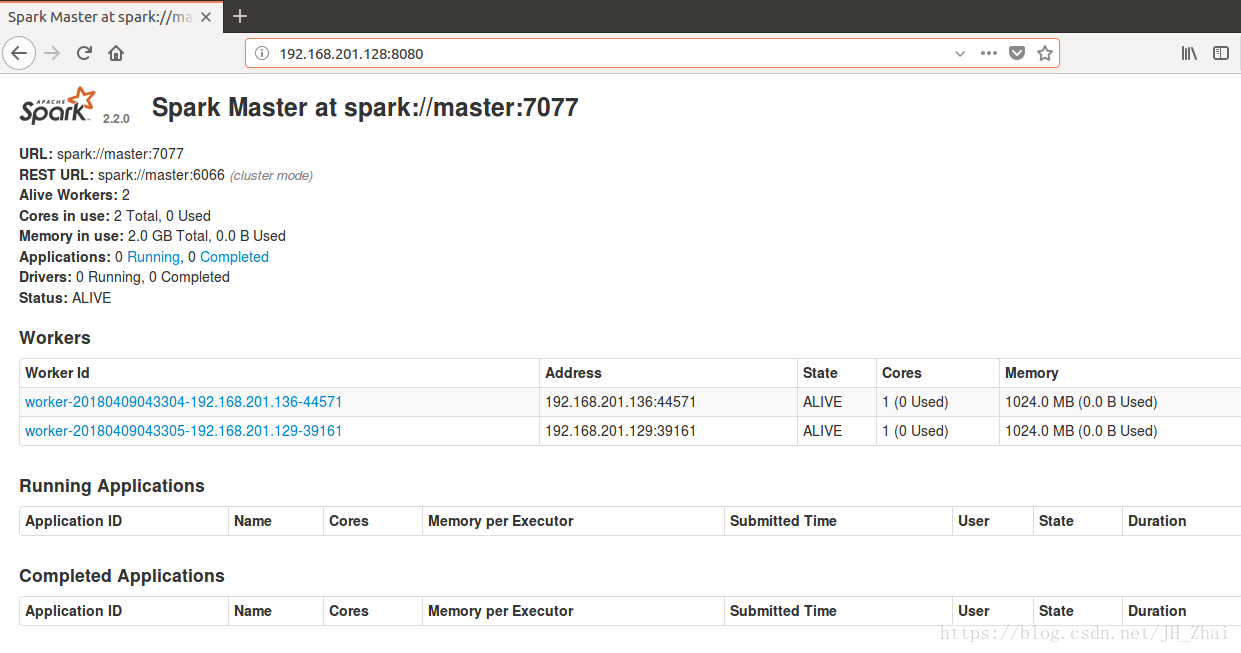
成功開啟Spark叢集之後可以進入Spark的WebUI介面,可以通過
SparkMaster_IP:8080,即
http://192.168.201.128:8080/訪問,可見有兩個正在執行的Worker節點。
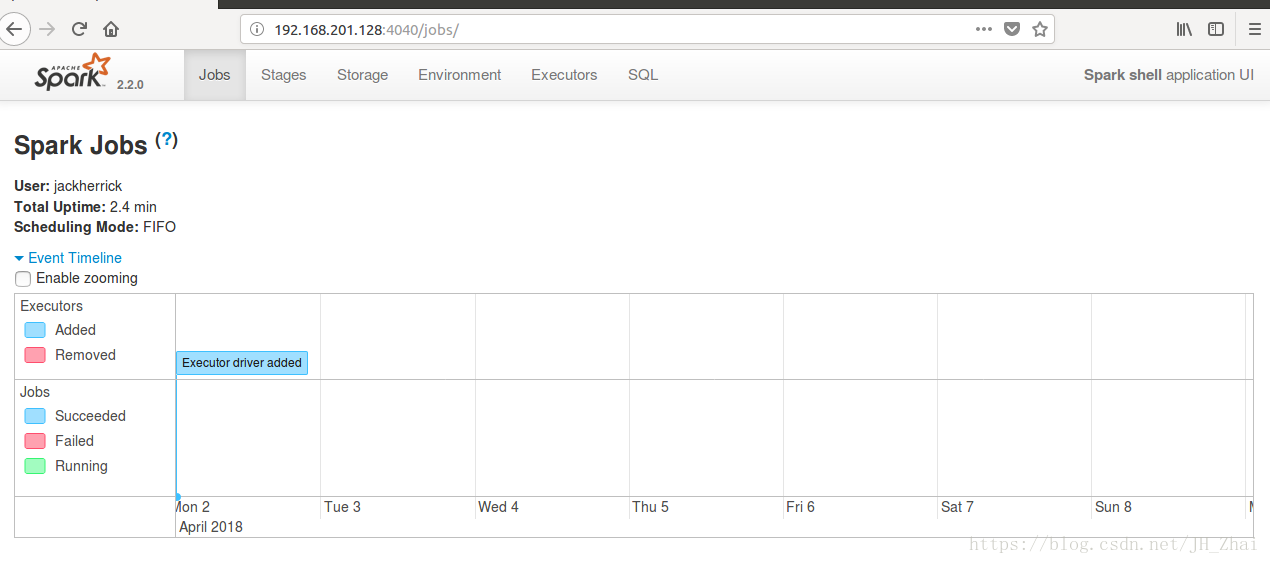
開啟Spark-shell
spark-shell便可開啟Spark的shell
同時,因為shell在執行,我們也可以通過
SparkMaster_IP:4040,即
http://192.168.201.128:4040/訪問WebUI檢視當前執行的任務。