
記一次TcpListenOverflows報警解決過程
問題描述
2015-06-25,晚上21:33收到報警,截圖如下:
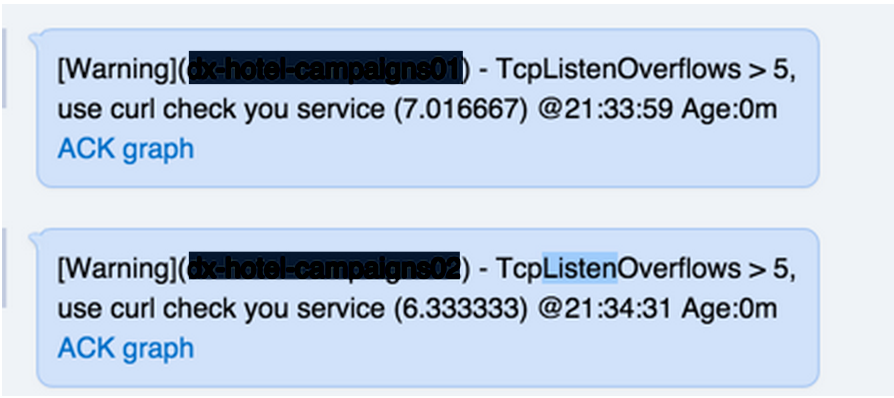
此時,登陸伺服器,用curl檢查,發現服務報500錯誤,不能正常提供服務。
問題處理
tail各種日誌,jstat看GC,不能很快定位問題,於是dump記憶體和執行緒stack後重啟應用。
jps -v,找出Process ID
jstack -l PID > 22-31.log
jmap -dump:format=b,file=22-29.bin PID
TcpListenOverflows
應用處理網路請求的能力,由兩個因素決定:
1、應用的OPS容量(本例中是 就是我們的jetty應用:controller和thrift的處理能力)
2、Socket等待佇列的長度(這個是os級別的,cat /proc/sys/net/core/somaxconn 可以檢視,預設是128,可以調優成了4192,有的公司會搞成32768)
當這兩個容量都滿了的時候,應用就不能正常提供服務了,TcpListenOverflows就開始計數,zabbix監控設定了>5發警報,於是就收到報警簡訊和郵件了。
這個場景下,如果我們到伺服器上看看 listen情況,watch "netstat -s | grep listen",會看到“xxx times the listen queue of a socket overflowed”,並且這個xxx在不斷增加,這個xxx就是我們沒有對網路請求正常處理的次數。
參考文章:
理解了以上,我們已經可以大致認為,問題的根源,就是應用處理能力不足。以下的問題分析步驟,可以繼續對此進行佐證。
問題分析
執行緒棧
首先看執行緒棧,大約12000多個執行緒,大量執行緒被TIME_WAIT/WAIT在不同的地址,偶有多個執行緒被同一個地址WAIT的情況,但是都找不到這個地址執行的是什麼程式,貌似這個執行緒棧意義不大。
關於這點,還請高手進一步幫助分析,能否可以通過這個檔案直接定位問題。
Eclipse Memory Analyzer
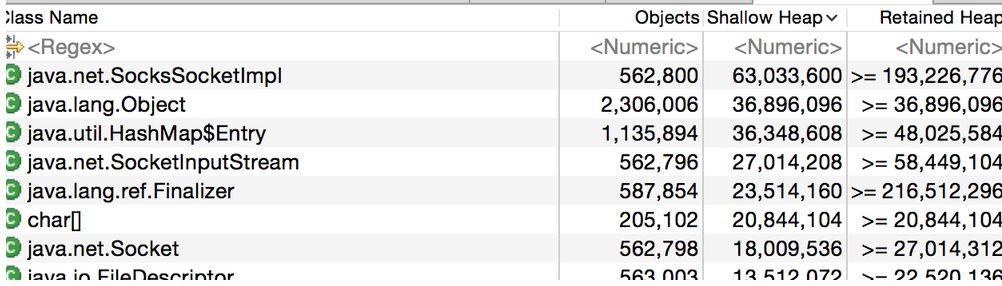
通過分析,我們可以看到,記憶體中最多的類,是socket相關的,截圖如下:
Zabbix監控
問題解決
1、申請兩臺新虛擬機器,掛上負載。
2、Jetty調優,增大執行緒數,maxThreads設定為500。
3、呼叫外部介面Timeout時間,統一調整為3秒,3秒前端就會超時,繼續讓使用者走別的,所以我們的後端程序繼續處理已經毫無意義。
問題完全解決了嗎?
找個時間,請高手幫忙分析日誌,發現一個執行緒數太多的問題,兩類執行緒太多(HttpClientPool、HttpMonitorCheckTimer );看事發時zabbix的截圖,也是JVM執行緒很大,2萬多了,並且不會減小。
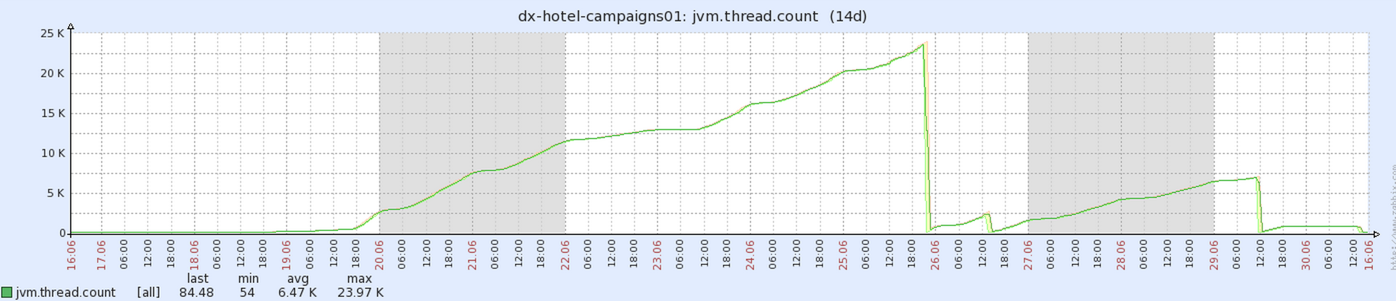
一起定位問題,定位到一個問題,每次都會news一個HttpClientHelper,new的過程中有兩件事:
1、起一個HttpMonitor執行緒,裡面有定時任務,所以這個執行緒是不死的。這個執行緒起名了,“Executors.newScheduledThreadPool(1, new NamedThreadFactory("HttpMonitorCheckTimer"))”,所以我們看多很多叫這個名字的執行緒
2、起一個HttpClientPool$IdleConnectionMonitorThread執行緒,這個執行緒是定時回收池子中過期以及空閒超過一點時間的執行緒,這個執行緒沒起名,所以叫Thread-XXX這樣的名字
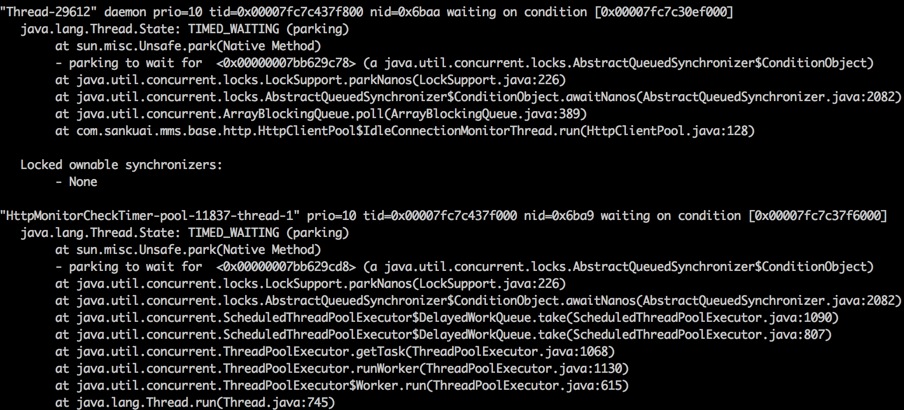
grep HttpClientPool 22-31.log | wc -l 11857
grep HttpMonitorCheckTimer 22-31.log | wc -l 11856
這兩種執行緒一定是1:1的關係,都是不死的。看起來Thread-XXX的多,這是因為其他的執行緒,沒起名字的,也是這樣命名的,所以。。。所以執行Thread,還是起個名字吧。
查閱一些“PoolingHttpClientConnectionManager”執行緒池方式進行http呼叫的例子,根據HttpClientHelper的實現方式,寫個PoolingHttpClientConnectionManagerDemo.java程式碼,執行1個小時,基本確認單例方式能正常執行;
於是修改單例方式呼叫HttpClientHelper,增加一點對呼叫次數的統計,上線。