個人hadoop學習總結:Hadoop叢集+HBase叢集+Zookeeper叢集+chukwa監控(包括單機、偽分佈、完全分佈安裝操作)
環境介紹:
虛擬機器四個:
hadoop-marster
hadoop-salve1
hadoop-salve2
hadoop-salve3
===========================1.Hadoop==========================================================================
=================Linux下建立偽分散式==============================================
1.下載hadoop和jdk
http://mirror.esocc.com/apache/hadoop/common
本例使用:hadoop-1.0.4.tar.gz
2.安裝
2.1安裝jdk
第一種:tar包
1.下載jdk並解壓:(我選的是tar包的檔案)
www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
2.解壓:(tar -zxvf jdk-7u15-linux-x64.tar.gz -C /usr/local)
3.配置jdk環境變數
#vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.7.0_15
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
:wq
#source /etc/profile
4.執行#java -version
5.編寫測試類
第二種:bin包
chmod +x jdk-6u27-linux-x64.bin
./jdk-6u27-linux-x64.bin
mv jdk1.6.0_27/ /usr/local/
配置jdk環境變數
#vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.6.0_27
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
:wq
#source /etc/profile
執行#java -version
3.解壓配置hadoop
tar zxvf hadoop-**.tar.gz
mv hadoop-** /usr/local/
cd /usr/local/hadoop-**/conf
3.1.修改hadoop-env.sh
vi hadoop-env.sh
開啟JAVA_HOME,並指定當前安裝的jdk位置:
export JAVA_HOME=/usr/local/jdk1.6.0_27
3.2.修改conf-site.xml
核心配置檔案,設定hadoop的HDFS的地址及埠
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/dhfs/tmp</value>
</property>
</configuration>
3.3.修改hdfs-site.xml
設定檔案儲存目錄和備份的個數
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/data/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mkidr /data/hadoop/data
3.4.配置mapred-site.xml
MapReduce配置檔案,配置JobTracker的地址及埠
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
</configuration>
3.配置ssh免密碼登陸
cd /root
生成金鑰對可以使用rsa和dsa兩種方式,分別生成兩個檔案。推薦使用rsa
ssh-keygen -t rsa
然後持續回車,生成一對,包含公鑰和私鑰,然後追加或者覆蓋
追加
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
覆蓋
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
完成後進行測試
ssh hadoop-master
第一次會詢問是否繼續連結,輸入yes
然後發現進入了另一個根目錄中,跟剛剛的shell不在一個裡面
4.格式化Hadoop的檔案系統HDFS
/usr/local/hadoop-1.0.4/bin/hadoop namenode -format
5.啟動hadoop
/usr/local/hadoop-1.0.4/bin/start-all.sh
如果有必要,可以分別啟動hdfs和mapreduce
start-dfs.sh和start-mapred.sh
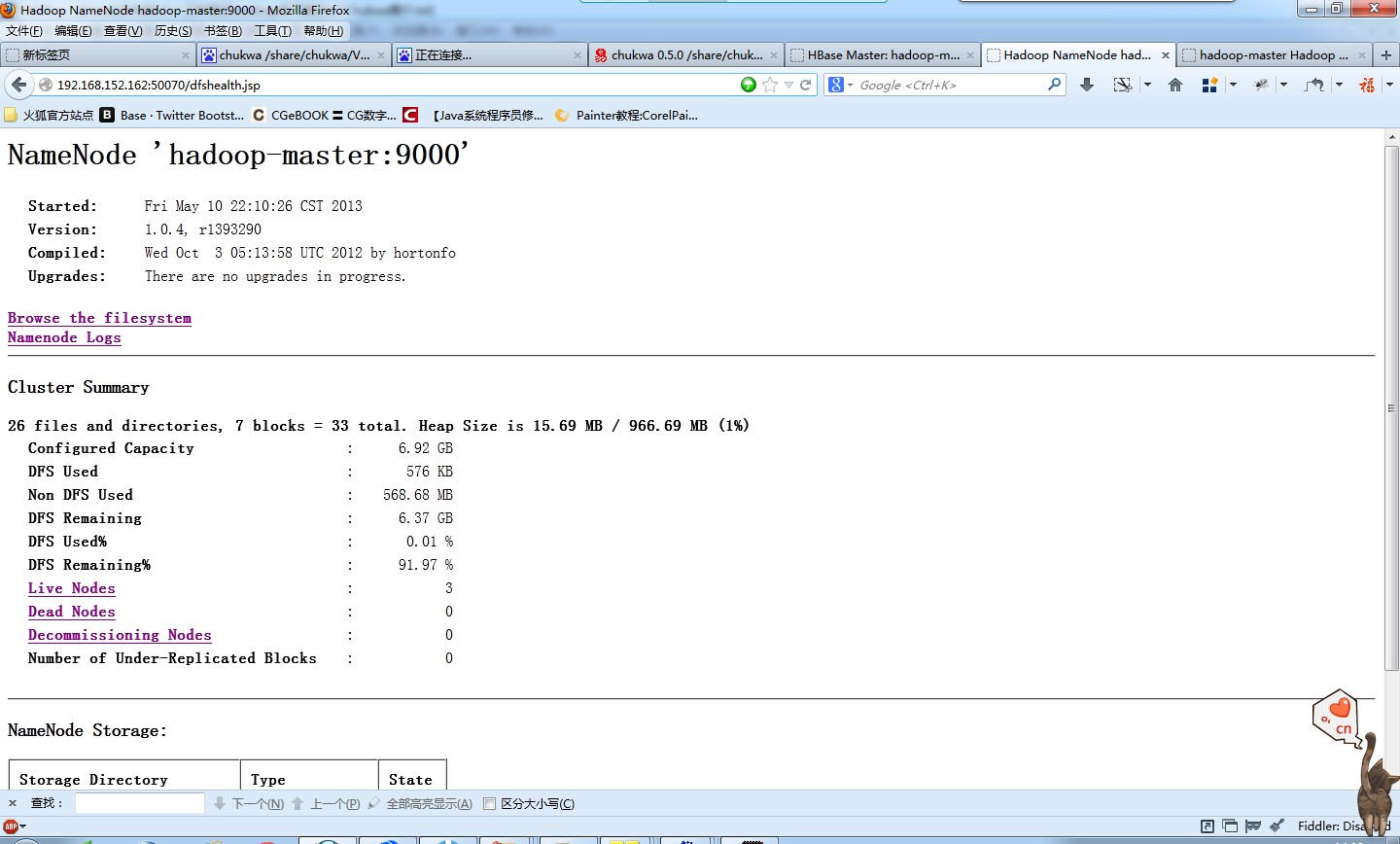
6.驗證
瀏覽器開啟
http://hadoop-master:50030 MapReduce的web頁面
http://hadoop-master:50070 HDFS的web頁面
如果在主機訪問虛擬機器,無法訪問時,注意埠防火牆和host是否設定了與ip對應
============================================================================================
============================================================================================
=================Linux下建立完全分散式==============================================
============================================================================================
============================================================================================
1、2兩步與偽分散式完全一樣
3.所有的節點修改/etc/hosts,新增如下對應:(如果不喜歡使用host也可以使用DNS解析伺服器)
192.168.152.162 hadoop-master
192.168.152.163 hadoop-slave1
192.168.152.164 hadoop-slave2
192.168.152.165 hadoop-slave3
4.建立hadoop使用者
useradd hadoop
passwd hadoop
mkdir /data/hadoop
mkdir /data/hadoop/data
mkdir /home/hadoop/dhfs
mkdir /home/hadoop/dhfs/tmp
5.ssh免密碼配置
首先要以hadoop使用者登入,然後進入hadoop的主目錄,再按照上面的步驟生成金鑰對
su hadoop
cd
ssh-keygen -t rsa
然後自行選擇是追加還是覆蓋
追加
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
覆蓋
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
完成後進行測試
ssh hadoop-master
把每個節點的authorized_keys合併成一個檔案;並替換所有節點的原有authorized_keys
=================以上5步操作需要在每個節點全部執行一遍=================================
6.在master解壓配置hadoop
tar zxvf hadoop-**.tar.gz
mv hadoop-** /usr/local/
cd /usr/local/hadoop-**/conf
6.1.修改hadoop-env.sh
vi hadoop-env.sh
開啟JAVA_HOME,並指定當前安裝的jdk位置:
export JAVA_HOME=/usr/local/jdk1.6.0_27
6.2.修改conf-site.xml
核心配置檔案,設定hadoop的HDFS的地址及埠
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/dhfs/tmp</value>
</property>
</configuration>
6.3.修改hdfs-site.xml
設定檔案儲存目錄和備份的個數
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/data/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
mkidr /data/hadoop/data
6.4.配置mapred-site.xml
MapReduce配置檔案,配置JobTracker的地址及埠
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
</configuration>
6.5修改masters和salves
vi /usr/local/hadoop-**/conf/masters
hadoop-master
vi /usr/local/hadoop-**/conf/salves
hadoop-slave1
hadoop-slave2
hadoop-slave3
6.6向各個節點複製hadoop
執行前先將hadoop資料夾的許可權付給hadoop
chown -R hadoop.hadoop /usr/local/hadoop-1.0.4
並將目標伺服器的資料夾的寫許可權賦予hadoop使用者;或者直接將hadoop資料夾移入到hadoop使用者的目錄中
scp -r hadoop-1.0.4/ hadoop-slave1:/home/hadoop
scp -r hadoop-1.0.4/ hadoop-slave2:/home/hadoop
scp -r hadoop-1.0.4/ hadoop-slave3:/home/hadoop
======以下操作跟偽分散式一樣==================
7.格式化Hadoop的檔案系統HDFS(只在主節點啟動即可)
/home/hadoop/hadoop-1.0.4/bin/hadoop namenode -format
8.啟動hadoop
/home/hadoop/hadoop-1.0.4/bin/start-all.sh
如果有必要,可以分別啟動hdfs和mapreduce
start-dfs.sh和start-mapred.sh
9.驗證
瀏覽器開啟
http://hadoop-master:50030 MapReduce的web頁面
http://hadoop-master:50070 HDFS的web頁面
如果在主機訪問虛擬機器,無法訪問時,注意埠防火牆和host是否設定了與ip對應
10檢查守護程序情況
/usr/local/jdk1.6.0_27/bin/jps
==========hello world測試===========================================
cd
mkdir input
cd input/
echo "hello world" >test1.txt
echo "hello hadoop" >test2.txt
拷貝input到hadoop的hdfs中
/home/hadoop/hadoop-1.0.4/bin/hadoop dfs -put /home/hadoop/input/test1.txt .
/home/hadoop/hadoop-1.0.4/bin/hadoop dfs -put /home/hadoop/input/test2.txt .
檢視是否拷貝成功
/home/hadoop/hadoop-1.0.4/bin/hadoop dfs -ls .
執行計數器
/home/hadoop/hadoop-1.0.4/bin/hadoop jar /home/hadoop/hadoop-1.0.4/
hadoop-examples-1.0.4.jar wordcount . out
檢視目錄、檔案結構、分詞結果
/home/hadoop/hadoop-1.0.4/bin/hadoop dfs -ls .
/home/hadoop/hadoop-1.0.4/bin/hadoop dfs -ls ./out
/home/hadoop/hadoop-1.0.4/bin/hadoop dfs -cat ./out/*
檢視資料寫在作業系統的位置:在datanode節點使用:
ls -lR /data/hadoop/data/
/trash 回收站
===========================================================================
1.org.apache.hadoop.ipc.RemoteException: java.io.IOException: File /user/hadoop/in could only be replicated to 0 nodes, instead of 1
/home/hadoop/hadoop-1.0.4/bin/hadoop dfsadmin -report
檢視是否為節點分配了容量
原因:Configured Capacity也就是datanode 沒用分配容量
修改檔案Hadoop conf/core-site.xml 中hadoop.tmp.dir的值
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/dhfs/tmp</value>
</property>
2.ERROR namenode.NameNode: java.io.IOException: Cannot create directory
chown -R hadoop.hadoop /home/hadoop/dhfs/
chown -R hadoop.hadoop /data/hadoop/
3.org.apache.hadoop.ipc.RPC server
這個問題基本上localhost和hostname同為127.0.0.1所致。
將hostname的ip修改為當前機器的ip地址就好了
遇到問題,多看日誌檔案
4.啟動Permission denied (publickey,gssapi-with-mic,password)
檢查當前使用者是不是ssh中指定的使用者
===========================================================================
====================2.Hbase=================================================================================
本測試的版本是:0.92.2
======2Hbase的基本操作=================================
export HADOOP_HOME=/home/hadoop/hadoop-1.0.4
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export HBASE_HOME=/home/hadoop/hbase-0.92.2/
export HBASE_CONF_DIR=$HBASE_HOME/conf
export PATH=$HBASE_HOME/bin:$HBASE_HOME/conf:$PATH
1.HBase安裝
下載hbase包,並解壓;配置conf/hbase-site.xml
單機:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///tmp/hbase-${user.name}/hbase</value>
</property>
</configuration>
偽分佈:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
完全分佈:
1)配置site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop-master:9000/hbase</value>
<description>HBase資料儲存目錄</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>指定HBase執行的模式:false:單機/偽分佈;true:完全分佈</description>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://hadoop-master:60000</value>
<description>指定Master位置</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop-master,hadoop-slave1,hadoop-slave2,hadoop-slave3</value>
<description>指定ZooKeeper叢集</description>
</property>
</configuration>
2)配置conf/regionservers的配置
hadoop-master
hadoop-slave1
hadoop-slave2
hadoop-slave3
3)ZooKeeper配置
hbase-env.sh中
HBASE_MANAGES_ZK預設為true;表示ZooKeeper會隨著HBase啟動而執行;
設定為false:需要自己手動開啟
4)向各個節點複製,然後配置各個節點的環境變數
scp -r hbase-0.92.2/ hadoop-slave1:/home/hadoop
scp -r hbase-0.92.2/ hadoop-slave2:/home/hadoop
scp -r hbase-0.92.2/ hadoop-slave3:/home/hadoop
5)修改hbase-env.sh檔案中的java_home的環境變數
2.執行HBase
啟動順序:HDFS->ZooKeeper->HBase
單機:start-hbase.sh
偽分佈:start-hbase.sh
完全分佈:start-hbase.sh
========================3.Zookeeper=============================================================================
=======2.ZooKeeper的安裝和配置============================================
2.1安裝ZooKeeper
2.1.1單機下安裝ZooKeeper
1)下載
2)安裝
export ZOOKEEPER_HOME=/$HADOOP_HOME/zookeeper-3.4.5
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
3)在$ZOOKEEPER_HOME/conf下建立一個zoo.cfg檔案,並新增如下內容:
#The number of milliseconds of each tick
tickTime = 2000
#the directory where the snapshot is stored
dataDir = $ZOOKEEPER_HOME/data
#the port at which the clients will connect
clientPort = 2181
2.1.2在叢集下安裝ZooKeeper
在奇數個伺服器上安裝zookeeper並安裝單機模式進行配置,需要修改的是zoo.cfg檔案,如下:
#The number of milliseconds of each tick
tickTime = 2000
#The number of ticks that the initial
#synchronization phase can take
initLimit = 10
#The number of ticks that can pass between
#sending a request and getting an acknowledgement
syncLimit = 5
#the directory where the snapshot is stored
dataDir = /home/sid/Downloads/hadoop-1.0.4/zookeeper-3.4.5/data
#the port at which the clients will connect
clientPort = 2181
#the location of the log file
dataLogDir = /home/sid/Downloads/hadoop-1.0.4/zookeeper-3.4.5/log
server.1 = hadoop-master:2887:3887
server.2 = hadoop-slave1:2888:3888
server.3 = hadoop-slave2:2889:3889
server.4 = hadoop-slave3:2889:3889
然後執行復制命令:
scp -r zookeeper-3.4.5/ hadoop-slave1:/home/hadoop/hadoop-1.0.4
scp -r zookeeper-3.4.5/ hadoop-slave2:/home/hadoop/hadoop-1.0.4
scp -r zookeeper-3.4.5/ hadoop-slave3:/home/hadoop/hadoop-1.0.4
在dataDir下面建立一個檔名為myid的檔案,在這個檔案中加入自身的serverid;如果是主機就加入1,這個serverid在叢集中必須是唯一值
其中的埠號,第一個是從(follower)機器連線到主機(leader)的埠,第二個是用來進行leader選舉的埠。
2.1.3在叢集偽分佈模式下安裝ZooKeeper
安裝叢集模式,在$ZOOKEEPER_HOME/conf下建立三個:zoo1.cfg、zoo2.cfg、zoo3.cfg;並修改
dataDir = /home/sid/Downloads/hadoop-1.0.4/zookeeper-3.4.5/data_num
dataLogDir = /home/sid/Downloads/hadoop-1.0.4/zookeeper-3.4.5/log_num
clientPort = 218num
server.1 = localhost:2887:3889
server.2 = localhost:2888:3888
server.3 = localhost:2889:3889
並在對應的data_num中加入myid,並寫入對應的num
2.2配置ZooKeeper
2.2.1最低配置:
tickTime、dataDir、clientPort
2.2.2高階配置:
dataLogDir:事務日誌寫入位置
maxClientCnxns:限制連線到ZooKeeper的客戶端數量,並限制併發連線數量
minSessionTimeout
maxSessionTimeout
2.2.3叢集配置:
initLimit:允許follower連線並同步到leader的初始化連線時間,它是以ticktime的倍數來表示
syncLimit:表示leader和follower直接傳送訊息時請求和應答的時間長度。
3.執行ZooKeeper
3.1.單機:zkServer.sh start
3.2.叢集模式:在每臺ZooKeeper執行:zkServer.sh start
3.3.叢集偽分佈:
zkServer.sh start zoo1.cnf
zkServer.sh start zoo2.cnf
zkServer.sh start zoo3.cnf.
hadoop、hbase、zookeeper整合
1.安裝hadoop並啟動
2.配置zookeeper並啟動
3.配置hbase(按照完全分散式配置)
配置hbase-site.xml
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop-master,hadoop-slave1,hadoop-slave2,hadoop-slave3</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>60000</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>
</property>
然後啟動start-hbase.sh
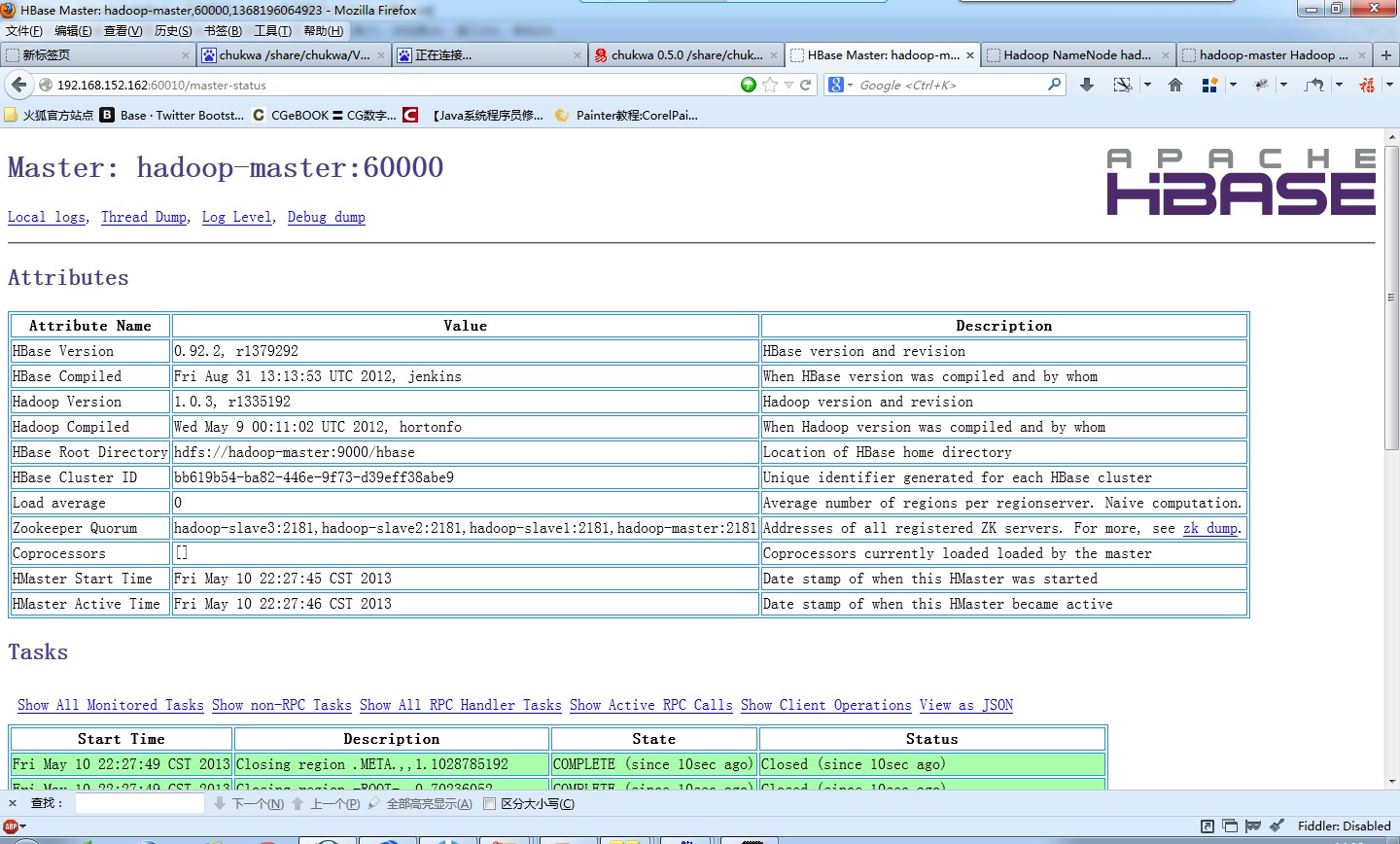
通過瀏覽器:http://localhost:60010/
檢視列表中是否存在Zookeeper Quorum;若存在則整合成功
偽分佈修改
================================
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>60000</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>
</property>
======================4.Chukwa===============================================================================
========4.Chukwa的叢集搭建=========================================
1.安裝:
export CHUKWA_HOME=$HADOOP_HOME/chukwa-incubating-0.5.0
export CHUKWA_CONF_DIR=$CHUKWA_HOME/etc/chukwa
export PATH=$CHUKWA_HOME/bin:$CHUKWA_HOME/sbin:$CHUKWA_CONF_DIR:$PATH
2.Hadoop和HBase叢集配置
hadoop和hbase的安裝看前面的筆記。然後執行下面的操作
首先將Chukwa的檔案複製到hadoop中:
mv $HADOOP_HOME/conf/log4j.properties $HADOOP_HOME/conf/log4j.properties.bak
mv $HADOOP_HOME/conf/hadoop-metrics2.properties $HADOOP_HOME/conf/hadoop-metrics2.properties.bak
cp $CHUKWA_CONF_DIR/hadoop-log4j.properties $HADOOP_HOME/conf/log4j.properties
cp $CHUKWA_CONF_DIR/hadoop-metrics2.properties $HADOOP_HOME/conf/hadoop-metrics2.properties
cp $CHUKWA_HOME/share/chukwa/chukwa-0.5.0-client.jar $HADOOP_HOME/lib
cp $CHUKWA_HOME/share/chukwa/lib/json-simple-1.1.jar $HADOOP_HOME/lib
配置完成後,啟動Hadoop叢集,接著進行Hbase設定,需要在HBase中建立資料儲存所需要的表,表的模式已經建好只需要通過hbase shell匯入即可,如下:
bin/hbase shell < $CHUKWA_CONF_DIR/hbase.schema
3.Collector配置
我們首先要對$CHUKWA_CONF_DIR/chukwa-env.sh進行配置。該檔案為Chukwa的環境變數,大部分的指令碼需要從該檔案中讀取關鍵的全域性Chukwa配置資訊。
設定JAVA_HOME;註釋下面兩個
export JAVA_HOME=/usr/local/jdk1.6.0_27
export HADOOP_CONF_DIR=/home/hadoop/hadoop-1.0.4/conf
export HBASE_CONF_DIR=/home/hadoop/hbase-0.92.2/conf
當需要執行多臺機器作為收集器時,需要修改$CHUKWA_CONF_DIR/collectors檔案,格式與hadoop的slaves一樣
hadoop-master
hadoop-slave1
hadoop-slave2
hadoop-slave3
$CHUKWA_CONF_DIR/initial_Adaptors檔案主要用於設定Chukwa監控哪些日誌,以及什麼方式、什麼頻率來監控等。使用預設配置即可,如下
add sigar.SystemMetrics SystemMetrics 60 0
add SocketAdaptor HadoopMetrics 9095 0
add SocketAdaptor Hadoop 9096 0
add SocketAdaptor ChukwaMetrics 9097 0
add SocketAdaptor JobSummary 9098 0
$CHUKWA_CONF_DIR/chukwa-collector-conf.xml維護了Chukwa的基本配置資訊。我們需要通過該檔案制定HDFS的位置:如下:
<property>
<name>writer.hdfs.filesystem</name>
<value>hdfs://hadoop-master:9000/</value>
<description>HDFS to dump to</description>
</property>
下面的屬性設定用於制定sink data地址,/chukwa/logs/就是它在HDFS中的地址。在預設情況下,Collector監聽8080埠,不過這是可以修改的,各個Agent將會向該埠發訊息。
<property>
<name>chukwaCollector.outputDir</name>
<value>/chukwa/logs/</value>
<description>chukwa data sink directory</description>
</property>
<property>
<name>chukwaCollector.http.port</name>
<value>8080</value>
<description>The HTTP port number the collector will listen on</description>
</property>
4.Agent配置
Agent由$CHUKWA_CONF_DIR/agents檔案進行配置,與collectors相似:
hadoop-master
hadoop-slave1
hadoop-slave2
hadoop-slave3
另外,$CHUKWA_CONF_DIR/chukwa-agent-conf.xml檔案維護了代理的基本配置資訊,其中最重要的屬性是叢集名,用於表示被監控的節點,這個值被儲存在每一個被收集到的塊中,一區分不同的叢集,如設定cluster名稱:cluster="chukwa"
<property>
<name>chukwaAgent.tags</name>
<value>cluster="chukwa"</value>
<description>The cluster's name for this Agent</description>
</property>
另一個可選的節點是chukwaAgent.checkpoint.dir,這個目錄是Chukwa執行的Adapter的定期檢查點,他是不可共享的目錄,並且只能是本地目錄,不能是網路檔案系統目錄。
5.使用Pig進行資料分析
可以使用pig進行資料分析,因此需要額外設定環境變數。要讓pig能夠讀取chukwa收集到的資料,即與HBase和Hadoop進行連結,首先要確保pig已經正確安裝,然後在pig的classpath中引入Hadoop和Hbase:
export PIG_CLASSPATH=$HADOOP_CONF_DIR:$HBASE_CONF_DIR
接下來建立HBASE_CONF_DIR的jar檔案:
jar cf $CHUKWA_HOME/hbase-env.jar $HBASE_CONF_DIR
建立週期性執行的分析指令碼作業:
pig -Dpig.additional.jars=${HBASE_HOME}/hbase-0.90.4.jar:${ZOOKEEPER_HOME}/zookeeper-3.3.2.jar:${PIG_HOME}/pig-0.10.0.jar:${CHUKWA_HOME}/hbase-env.jar${CHUKWA_HOME}/share/chukwa/script/pig/ClusterSummary.pig
7向各個節點複製,然後配置各個節點的環境變數
scp -r chukwa-incubating-0.5.0 hadoop-slave1:/home/hadoop/hadoop-1.0.4
scp -r chukwa-incubating-0.5.0 hadoop-slave2:/home/hadoop/hadoop-1.0.4
scp -r chukwa-incubating-0.5.0 hadoop-slave3:/home/hadoop/hadoop-1.0.4
執行Chukwa
在啟動chukwa之前,先啟動Hadoop和Hbase,然後分別啟動collector和agent
1.collector:
啟動:./bin/chukwa collector
停止:./sbin/stop-collectors.sh
2.agent
啟動:./bin/chukwa agent
sbin/start-agents.sh
3.啟動HICC
啟動:./bin/chukwa hicc
啟動後可以通過瀏覽器進行訪問:http://<Server>:<port>/hicc
port預設是4080;
預設使用者名稱和密碼是:admin
可以根據需要對$CHUKWA_HOME/webapps/hicc.war檔案中的/WEB_INF/下的jetty.xml進行修改
4.啟動Chukwa過程:
1)啟動Hadoop和HBase
2)啟動Chukwa:sbin/start-chukwa.sh
3)啟動HICC:bin/chukwa hicc
=================================================
cat: /root/chukwa/chukwa-incubating-0.5.0/bin/share/chukwa/VERSION: 沒有那個檔案或目錄
/root/chukwa/chukwa-incubating-0.5.0/bin/chukwa: line 170: /root/java/jdk-1.6.0_20/bin/java: 沒有那個檔案或目錄
/root/chukwa/chukwa-incubating-0.5.0/bin/chukwa: line 170: exec: /root/java/jdk-1.6.0_20/bin/java: cannot execute: 沒有那個檔案或目錄
方法1:
將/root/chukwa/chukwa-incubating-0.5.0/下的share資料夾複製到./bin下面,
問題解決
方法2:
用gedit開啟$CHUKWA_HOME/libexec/chukwa-config.sh
修改第30 31行
# the root of the Chukwa installation
export CHUKWA_HOME=`pwd -P ${CHUKWA_LIBEXEC}/..`
為:
# the root of the Chukwa installation
export CHUKWA_HOME=/root/chukwa/chukwa-incubating-0.5.0
其中/root/chukwa/chukwa-incubating-0.5.0為chukwa實際安裝路徑