
淺析JVM之記憶體管理
這是一篇有關JVM記憶體管理的文章。這裡將會簡單的分析一下Java如何使用從實體記憶體上申請下來的記憶體,以及如何來劃分它們,後面還會介紹JVM的核心技術:如何分配和回收記憶體。
在Java中哪些元件需要使用記憶體
Java堆
Java堆用於儲存Java物件的記憶體區域,堆的大小在JVM啟動時就一次向作業系統申請完成,通過 -Xmx和 -Xms兩個選項來控制大小,Xmx來表示堆的最大大小,Xms表示初始大小。一旦分配完成,堆的大小就將固定,不能在記憶體不夠時再向作業系統重新申請,同時當記憶體空閒時也不能將多餘的空間交還給作業系統。
執行緒
JVM執行實際程式的實體是執行緒,當然執行緒是需要記憶體空間來儲存一些必要的資料。每個執行緒建立時JVM都會為它建立一個堆疊,堆疊的大小根據不同的JVM實現而不同,通常在256KB~756KB之間。
執行緒所佔空間相比堆空間來說比較小。但是如果執行緒過多,執行緒堆疊的總記憶體使用量可能也非常大。當前有很多應用程式根據CPU的核數來分配建立的執行緒數,如果執行的應用程式執行緒數量比可用於它們的處理數量都,效率通常很低,並且可能導致比較差的效能和更高的記憶體佔用率。
一般執行緒的最佳數量=(CPU核心數量*2)+1
類和類載入器
在Java中的類和載入類的類載入器本身同樣需要儲存空間。比如在Sun JDK中它們也被儲存在堆中,這個區域叫做永久代(PermGen區)。
需要注意的一點是JVM是按需來載入類的——JVM只會載入jar包中的那些被應用所用到的類。
講道理來說使用的Java類越多,需要佔用的記憶體也會越多,還有一種情況是可能會重複載入同一個類。通常情況下JVM只會載入一個類到記憶體一次,但是如果是自己實現的類載入器會出現重複載入的情況,如果PermGen區不能對已經失效的類做解除安裝,可能會導致PermGen區記憶體洩露。所以需要注意PermGen區的記憶體回收問題。通常一個類能夠被回收
-
在Java堆中沒有對錶示該類載入器的java.lang.ClassLoader物件的引用。
-
Java堆沒有對錶示類載入器載入的類的任何java.lang.Class物件的引用。
-
在Java堆上該類載入器載入的任何類的所有物件都不再存活(被引用)。
另外,JVM建立的3個預設類載入器Bootstrap Classloader、ExtClassLoader和AppClassLoader都不可能滿足這些條件。因為,任何系統類(如java.lang.String)或通過應用程式類載入的任何應用程式類都不能在執行時釋放。
NIO
NIO的簡介請自行百度。在這裡需要知道因為它使用了作業系統的函式os::malloc(),減少了開銷,是被經常使用的。它申請的是直接實體記憶體,因為無視了虛擬機器中堆的限制。
直接ByteBuffer物件會自動清理本地緩衝區,但這個過程只能作為Java堆GC的一部分來執行,因此它們不會自動釋放相應施加在本機堆上的壓力。GC僅在Java堆被填滿,以至於無法為堆分配記憶體請求提供服務時發生,或者在Java應用中顯示請求時發生。當前在很多NIO框架中都會顯式的呼叫System.gc()來釋放NIO持有的記憶體。但是這種方法會影響應用程式的效能,因此會增加GC的次數,一般情況下通過設定-XX:+DisableExpelicitGC來控制System.gc()的影響,但是又會導致NIO direct memory記憶體洩露問題。
JNI
JNI技術使得原生代碼可以呼叫Java方法,也就是通常所說的native memory。實際上Java執行時本身也依賴JNI程式碼來實現類庫功能,如檔案安操作、網路IO操作或者其他系統呼叫。所以JNI也會增加Java執行時的本地記憶體佔用。
JMM ( Java Memory Model )概要
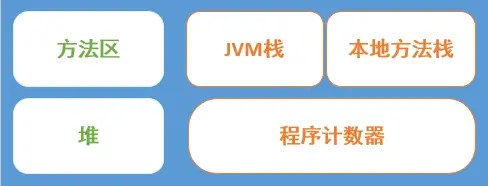
要理解JVM的記憶體管理策略,首先就要熟悉Java的執行時資料區,如上圖所示,在執行Java程式的時候,虛擬機器會把它所管理的記憶體劃分為多個不同的資料區,稱為執行時資料區。在程式執行過程中對記憶體的分配、垃圾的回收都在執行時資料區中進行。對於Java程式設計師來說,其中最重要的就是堆區和JVM棧區了。注意圖中的圖形面積比例並不代表實際的記憶體比例。
-
綠色的區域代表被執行緒所共享
-
黃色的區域代表被執行緒所獨享
下面來簡單的講一下圖中的區塊。
-
方法區:儲存虛擬機器執行時載入的類資訊、常量、靜態變數和即時編譯的程式碼,因此可以把這一部分考慮為一個儲存相對來說資料較為固定的部分,常量和靜態變數在編譯時就確定下來進入這部分記憶體,執行時類資訊會直接載入到這部分記憶體,所以都是相對較早期進入記憶體的。
-
執行時常量池:在JVM規範中是這樣定義執行時常量池這個資料結構的:Runtime Constant Pool代表執行時每個class檔案的常量表。它包含幾種常量:編譯期的數字常量、方法和域的引用(在執行時解析)。它的功能類似於傳統程式語言的符號表,儘管它包含的資料比典型的符號表要豐富得多。每個Runtime Constant Pool都是在JVM的Method area中分配的,每個Class或者Interface的Constant Pool都是在JVM建立class或介面時建立的。它是屬於方法區的一部分,所以它的儲存也受方法區的規範約束,如果常量池無法分配,同樣會丟擲OutOfMemoryError。
-
堆區:是JVM所管理的記憶體中最大的一塊。主要用於存放物件例項,每一個儲存在堆中的Java物件都會是這個物件的類的一個副本,它會複製包括繼承自它父類的所有非靜態屬性。而所謂的垃圾回收也主要是在堆區進行。 根據Java虛擬機器規範的規定,Java堆可以處於物理上不連續的記憶體空間中,只要邏輯是上連續的即可,就像我們的磁碟空間一樣。
-
JVM棧區:則主要存放一些物件的引用和編譯期可知的基本資料型別,這個區域是執行緒私有的,即每個執行緒都有自己的棧。在Java虛擬機器規範中,對這個區域規定了兩種異常情況:
-
如果執行緒請求的棧深度大於虛擬機器鎖所允許的深度,則丟擲
StackOverflowError異常 -
如果虛擬機器棧可以動態擴充套件,擴充套件時無法申請到足夠的記憶體,就會丟擲
OutOfMemoryError異常
-
-
本地方法棧:本地方法在執行時儲存資料產生的棧區。為JVM執行Native方法準備的空間,它和前面介紹的Java棧的作用是類似的,由於很多Native方法都是C語言實現的,所以它通常又叫C棧。和虛擬機器棧一樣,也會丟擲
StackOverflowError和OutOfMemoryError異常。 -
程式計數器:則是用來記錄程式執行到什麼位置的,顯然它應該是執行緒私有的,相信這個學過微機原理與介面課程的同學都應該能夠理解的。
舉個栗子
通常我們定義一個基本資料型別的變數,一個物件的引用,還有就是函式呼叫的現場儲存都使用記憶體中的棧空間;而通過new關鍵字和構造器建立的物件放在堆空間;程式中的字面量(literal)如直接書寫的100、“hello”和常量都是放在靜態儲存區中。棧空間操作最快但是也很小,通常大量的物件都是放在堆空間,整個記憶體包括硬碟上的虛擬記憶體都可以被當成堆空間來使用。
String str = new String(“hello”);-
str 這個引用放在棧上
-
new 創建出來的物件例項放在堆上
-
“hello”這個字面量放在靜態儲存區
JVM記憶體分配策略
在分析JVM記憶體分配策略之前,我們先介紹一下通常情況下作業系統都是採用哪些策略來分配記憶體的。
通常的記憶體分配策略
在作業系統中,將記憶體分配策略分為三種,分別是:
-
靜態記憶體分配
-
棧記憶體分配
-
堆記憶體分配
靜態記憶體分配 是指在程式編譯時鋸能確定每個資料在執行時的儲存空間需求,因此在編譯時就可以給它們分配固定的記憶體空間。這種分配策略不允許在程式程式碼中有可變資料結構(如可變陣列)的存在,也不允許有巢狀或者遞迴的結構出現,因為它們都會導致編譯程式無法計算機準確的儲存空間需求。
棧記憶體分配 也可稱為動態儲存分配,是由一個類似於堆疊的執行棧來實現的。和靜態記憶體分配相反,在棧式記憶體方案執行巨集,程式對資料區的需求在編譯時是完全無知的,只有執行時才能知道,但是規定在執行中進入一個程式模組時,必須知道該程式模組所需資料區大小才能為其分配記憶體。和我們所數值的資料結構中的棧一樣,棧式記憶體分配按照先進後出的原則進行分配。
堆記憶體分配 當程式真正執行到相應程式碼時才會知道空間大小。
Java中的記憶體分配一覽
JVM記憶體分配主要基於兩種:堆和棧。
先來說說 棧 。
Java棧的分配是和執行緒繫結在一起的,當我們建立一個執行緒時,很顯然,JVM就會為這個執行緒建立一個新的Java棧,一個執行緒的方法的呼叫和返回對應這個Java棧的壓棧和出棧。當執行緒啟用一個Java方法時,JVM就會線上程的Java棧裡新壓入一個幀,這個幀自然成了當前幀。在此方法執行期間,這個幀將用來儲存引數、區域性變數、中間計算過程和其他資料。
棧中主要存放一些基本型別的變數資料和物件控制代碼(引用)。存取速度比堆要快,僅次於暫存器,棧資料可以共享。缺點是,存在棧中的資料大小與生存期必須是確定的,這也導致缺乏了其靈活性。
Java的 堆 是一個執行時資料區,它們不需要程式程式碼來顯示地釋放。堆是由垃圾回收來負責的,堆的優勢是可以動態地分配記憶體大小,生存期也不必事先告訴編譯器,因為它是在執行時動態分配記憶體的,Java的垃圾收集器會自動收走這些不再使用的資料。但缺點是,由於要執行時動態分配記憶體,存取速度慢。
從堆和棧的功能和作用通俗地比較,堆主要用來存放物件,棧主要用來執行程式,這種不同主要由堆和棧的特點決定的。
在程式設計中,如C/C++,所有的方法呼叫是通過棧進行的,所有的區域性變數、形式引數都是從棧中分配記憶體空間的。實際上也不是什麼分配,只是從棧向上用就行,就好像工廠中的傳送帶一樣,棧指標會自動指引你到放東西的位置,你所要做的只是把東西放下來就行。在退出函式時,修改棧指標就可以把棧中的內潤銷燬。這樣的模式速度最快,當然要用來執行程式了。需要注意的是,在分配時,如為一個即將要呼叫的程式模組分配資料區時,應事先知道這個資料區的大小,也就是說上雖然分配是在程式執行中進行的,但是分配的大小是確定的、不變的,而這個“大小多少”是在編譯時確定的,而不是在執行時。
堆在應用程式執行時請求作業系統給自己分配記憶體,由於作業系統管理記憶體分配,所以在分配和銷燬時都要佔用時間,因此用堆的效率非常低。但是堆的優點在於,編譯器不必知道從堆裡分配多少儲存空間,也不必知道儲存的資料要在堆裡停留多長時間。因此,用堆儲存資料時會得到更大的靈活性,事實上,由於面向物件的多型性,堆記憶體分配是必不可少的,因為多型變數所需的儲存空間只有在執行時建立了物件之後才能確定。在C++中,要求建立一個物件時,只需用new命令編制相關命令即可。執行這些程式碼時,會在堆裡自動進行資料的儲存。當然,為達到這種靈活性,必然會付出一定的代價——在堆裡分配儲存空間會花掉更長的時間。
JVM記憶體回收策略
基本術語
-
垃圾(Garbage)
-
即需要回收的物件。作為編寫程式的人,是可以做出“這個物件已經不再需要了”這樣的判斷,但計算機是做不到的。因此,如果程式(通過某個變數等等)可能會直接或間接地引用一個物件,那麼這個物件就被視為“存活”;與之相反,已經引用不到的物件被視為“死亡”。將這些“死亡”物件找出來,然後作為垃圾進行回收,這就是GC的本質。
-
-
根(Root)
-
即判斷物件是否可被引用的起始點。至於哪裡才是根,不同的語言和編譯器都有不同的規定,但基本上是將變數和執行棧空間作為根。各位肯定會好奇根物件集合中都是些什麼,下面我們就來簡單的講一講。
-
在方法中區域性變數區的物件的引用
-
在Java操作棧中的物件引用:有些物件是直接在操作棧中持有的,所以操作棧肯定也包含根物件集合。
-
在常量池中的物件引用:每個類都會包含一個常量池,這些常量池中也會包含很多物件引用,如表示類名的字串就儲存在堆中,那麼常量池只會持有這個字串物件的引用。
-
在本地方法中持有的物件引用:有些物件被傳入本地方法中,但是這些物件還沒有被釋放。
-
類Class物件:當每個類被JVM載入時都會建立一個代表這個類的唯一資料型別的Class物件,而這個Class物件也同樣存放在堆中,當這個類不再被使用時,在方法去中類資料和這個Class物件同樣需要被回收。
-
-
JVM在做GC時會檢查堆中所有物件是否都會被這些根物件直接或間接引用,能夠被引用的物件就是活動物件,否則就可以被垃圾收集器回收。
-
-
stop-the-world
-
不管選擇哪種GC演算法,stop-the-world都是不可避免的。Stop-the-world意味著從應用中停下來並進入到GC執行過程中去。一旦Stop-the-world發生,除了GC所需的執行緒外,其他執行緒都將停止工作,中斷了的執行緒直到GC任務結束才繼續它們的任務。不然由於應用程式碼一直在執行中,會不斷建立和修改物件,導致結果腐化。GC調優通常就是為了改善stop-the-world的時間。
-
記憶體的分配方法
-
指標碰撞:在連續剩餘空間中分配記憶體。用一個指標指向記憶體已用區和空閒區的分界點,需要分配新的記憶體時候,只需要將指標向空閒區移動相應的距離即可。
-
空閒列表:在不規整的剩餘空間中分配記憶體。如果剩餘記憶體是不規整的,就需要用一個列表記錄下哪些記憶體塊是可用的,當需要分配記憶體的時候就需要在這個列表中查詢,找到一個足夠大的空間進行分配,然後在更新這個列表。
分配方式的選擇
指標碰撞的分配方式明顯要優於空閒列表的方式,但是使用哪種方式取決於堆記憶體是否規整,而堆記憶體是否規整則由使用的垃圾收集演算法決定。如果堆記憶體是規整的,則採用指標碰撞的方式分配記憶體,而如果堆是不規整的,就會採用空閒列表的方式。
垃圾回收是如何進行的?
尋找垃圾
要對物件進行回收,首先需要找到哪些物件是垃圾,需要回收。有兩種方法可以找到需要回收的物件,第一種叫做引用計數法。
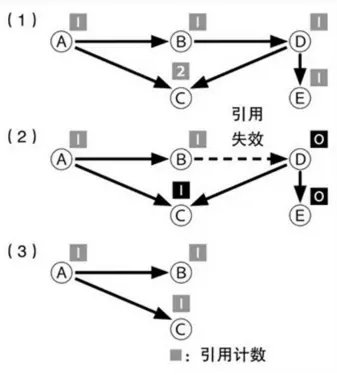
具體方法就是給物件新增一個引用計數器,計數器的值代表著這個物件被引用的次數,當計數器的值為0的時候,就代表沒有引用指向這個物件,那麼這個物件就是不可用的,所以就可以對它進行回收。但是有一個問題就是當物件之間迴圈引用時,比如這樣:
public class Main {
public static void main(String[] args) {
MyObject object1 = new MyObject();
MyObject object2 = new MyObject();
object1.object = object2;
object2.object = object1;
//最後面兩句將object1和object2賦值為null,也就是說object1和object2指向的物件已經不可能再被訪問,
//但是由於它們互相引用對方,導致它們的引用計數都不為0,那麼垃圾收集器就永遠不會回收它們。
object1 = null;
object2 = null;
}
}
class MyObject{
public Object object = null;
}其中每個物件的引用計數器的值都不為0,但是這些物件又是作為一個孤立的整體在記憶體中存在,其他的物件不持有這些物件的引用,這種情況下這些物件就無法被回收,這也是主流的Java虛擬機器沒有選用這種方法的原因。
另一種方法就是把堆中的物件和物件之間的引用分別看作有向圖的頂點和有向邊——即可達性分析法。這樣只需要從一些頂點開始,對有向圖中的每個頂點進行可達性分析(深度優先遍歷是有向圖可達性演算法的基礎),這樣就可以把不可達的物件找出來,這些不可達的物件還要再進行一次篩選,因為如果物件需要執行finalize()方法,那麼它完全可以在finalize()方法中讓自己變的可達。這個方法解決了物件之間迴圈引用的問題。上面提到了“從一些物件開始”進行可達性分析,這些起始物件被稱為GC Roots,可以作為GC Roots的物件有:
-
棧區中引用的物件
-
方法區中靜態屬性或常量引用的物件
上文中提到的引用均是強引用,Java中還存在其他三種引用,分別是,軟引用、弱引用和虛引用,當系統即將發生記憶體溢位時,才會對軟引用所引用的物件進行回收;而被弱引用所引用的物件會在下一次觸發GC時被回收;虛引用則僅僅是為了在物件被回收時能夠收到系統通知。
生存還是死亡
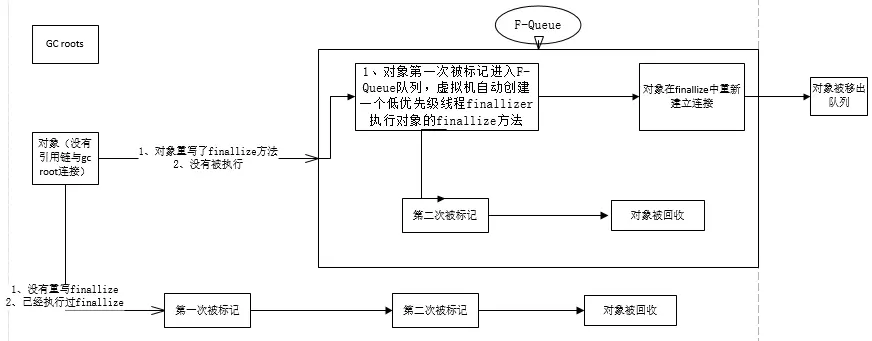
即使在可達性分析演算法中不可達的物件,也並非是“非死不可”的,這時候它們暫時處於“緩刑”階段,要真正宣告一個物件死亡,至少要經歷再次標記過程。
標記的前提是物件在進行可達性分析後發現沒有與GC Roots相連線的引用鏈。
第一次標記並進行一次篩選
-
篩選的條件是此物件是否有必要執行finalize()方法。 當物件沒有覆蓋finalize方法,或者finzlize方法已經被虛擬機器呼叫過,虛擬機器將這兩種情況都視為“沒有必要執行”,物件被回收。
第二次標記
-
如果這個物件被判定為有必要執行finalize()方法,那麼這個物件將會被放置在一個名為:F-Queue的佇列之中,並在稍後由一條虛擬機器自動建立的、低優先順序的Finalizer執行緒去執行。這裡所謂的“執行”是指虛擬機器會觸發這個方法,但並不承諾會等待它執行結束。這樣做的原因是,如果一個物件finalize()方法中執行緩慢,或者發生死迴圈(更極端的情況),將很可能會導致F-Queue佇列中的其他物件永久處於等待狀態,甚至導致整個記憶體回收系統崩潰。
Finalize()方法是物件脫逃死亡命運的最後一次機會,稍後GC將對F-Queue中的物件進行第二次小規模標記,如果物件要在finalize()中成功拯救自己————只要重新與引用鏈上的任何的一個物件建立關聯即可,譬如把自己賦值給某個類變數或物件的成員變數,那在第二次標記時它將移除出“即將回收”的集合。如果物件這時候還沒逃脫,那基本上它就真的被回收了。
/**
* 此程式碼演示了兩點
* 1、物件可以在被GC時自我拯救
* 2、這種自救的機會只有一次,因為一個物件的finalize()方法最多隻能被系統自動呼叫一次。
*/
public class FinalizeEscapeGC {
public static FinalizeEscapeGC SAVE_HOOK = null;
public void isAlive() {
System.out.println("yes, I am still alive");
}
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize method executed!");
FinalizeEscapeGC.SAVE_HOOK = this;
}
public static void main(String[] args) throws InterruptedException {
SAVE_HOOK = new FinalizeEscapeGC();
//物件第一次成功拯救自己
SAVE_HOOK = null;
System.gc();
//因為finalize方法優先順序很低,所有暫停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no ,I am dead QAQ!");
}
//-----------------------
//以上程式碼與上面的完全相同,但這次自救卻失敗了!!!
SAVE_HOOK = null;
System.gc();
//因為finalize方法優先順序很低,所有暫停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no ,I am dead QAQ!");
}
}
}
最後想說的是:請不要使用finalize()方法,使用try-finalize可以做的更好。這是一個歷史遺留的問題——當年為了讓C/C++程式設計師更好的接受它而做出的妥協。
垃圾收集演算法
好了,我們找到了垃圾。來談談如何處理這些垃圾吧。
標記-清除演算法
標記清除(Mark and Sweep)是最早開發出的GC演算法(1960年)。它的原理非常簡單,首先從根開始將可能被引用的物件用遞迴的方式進行標記,然後將沒有標記到的物件作為垃圾進行回收。
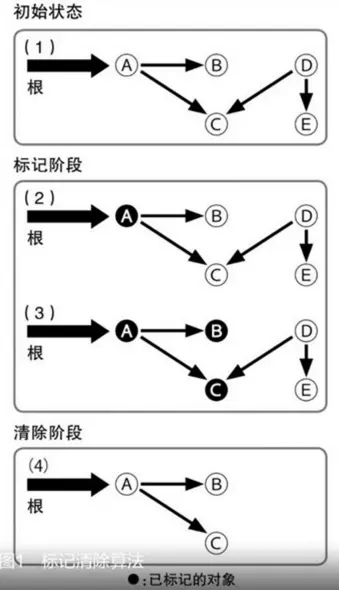
通過可達性分析演算法找到可以回收的物件後,要對這些物件進行標記,代表它可以被回收了。標記完成之後就統一回收所有被標記的物件。這就完成了回收,但是這種方式會產生大量的記憶體碎片,就導致了可用記憶體不規整,於是分配新的記憶體時就需要採用空閒列表的方法,如果沒有找到足夠大的空間,那麼就要提前觸發下一次垃圾收集。
標記-整理演算法
作為標記清除的變形,還有一種叫做標記整理(Mark and Compact)的演算法。

標記的過程和標記-清除演算法一樣,但是標記完成之後,讓所有存活的物件都向堆記憶體的一端移動,最後直接清除掉邊界以外的記憶體。這樣對記憶體進行回收之後,記憶體是規整的,於是可以使用指標碰撞的方式分配新的記憶體。
複製收集演算法
“標記”系列的演算法有一個缺點,就是在分配了大量物件,並且其中只有一小部分存活的情況下,所消耗的時間會大大超過必要的值,這是因為在清除階段還需要對大量死亡物件進行掃描。複製收集(Copy and Collection)則試圖克服這一缺點。在這種演算法中,會將從根開始被引用的物件複製到另外的空間中,然後,再將複製的物件所能夠引用的物件用遞迴的方式不斷複製下去。
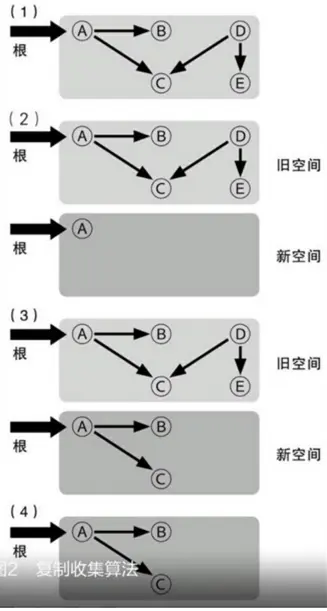
-
圖2的(1)部分是GC開始前的記憶體狀態,這和圖1的(1)部分是一樣的
-
圖2的(2)部分中,在舊物件所在的“舊空間”以外,再準備出一塊“新空間”,並將可能從根被引用的物件複製到新空間中
-
圖2的(3)部分中,從已經複製的物件開始,再將可以被引用的物件像一串糖葫蘆一樣複製到新空間中。複製完成之後,“死亡”物件就被留在了舊空間中
-
圖2的(4)部分中,將舊空間廢棄掉,就可以將死亡物件所佔用的空間一口氣全部釋放出來,而沒有必要再次掃描每個物件。下次GC的時候,現在的新空間也就變成了將來的舊空間
通過圖2我們可以發現,複製收集方式中,只存在相當於標記清除方式中的標記階段。由於清除階段中需要對現存的所有物件進行掃描,在存在大量物件,且其中大部分都即將死亡的情況下,全部掃描一遍的開銷實在是不小。而在複製收集方式中,就不存在這樣的開銷。
但是,和標記相比,將物件複製一份所需要的開銷則比較大,因此在“存活”物件比例較高的情況下,反而會比較不利。這種演算法的另一個好處是它具有區域性性(Lo-cality)。在複製收集過程中,會按照物件被引用的順序將物件複製到新空間中。於是,關係較近的物件被放在距離較近的記憶體空間中的可能性會提高,這被稱為區域性性。區域性性高的情況下,記憶體快取會更容易有效運作,程式的執行效能也能夠得到提高。
基於分代技術的演算法抉擇
上文提到了幾種GC演算法,但是各自的各自的優點,必須放到適合的場景內才能發揮最大的效率。
在JVM堆裡分有兩部分:新生代(young generate)和老年代(old generation)。

在新生代中長期存活的物件會逐漸向老年代過渡,新生代中的物件每經歷一次GC,年齡就增加一歲,當年齡超過一定值時,就會被移動到老年代。
新生代
大部分的新建立物件分配在新生代。因為大部分物件很快就會變得不可達,所以它們被分配在新生代,然後消失不再。當物件從新生代移除時,我們稱之為"Minor GC"。新生代使用的是複製收集演算法。
新生代劃分為三個部分:分別為Eden、Survivor from、Survivor to,大小比例為8:1:1(為了防止複製收集演算法的浪費記憶體過大)。每次只使用Eden和其中的一塊Survivor,回收時將存活的物件複製到另一塊Survivor中,這樣就只有10%的記憶體被浪費,但是如果存活的物件總大小超過了Survivor的大小,那麼就把多出的物件放入老年代中。
在三個區域中有兩個是Survivor區。物件在三個區域中的存活過程如下:
-
大多數新生物件都被分配在Eden區。
-
第一次GC過後Eden中還存活的物件被移到其中一個Survivor區。
-
再次GC過程中,Eden中還存活的物件會被移到之前已移入物件的Survivor區。
-
一旦該Survivor區域無空間可用時,還存活的物件會從當前Survivor區移到另一個空的Survivor區。而當前Survivor區就會再次置為空狀態。
-
經過數次(預設是15次)在兩個Survivor區域移動後還存活的物件最後會被移動到老年代。
如上所述,兩個Survivor區域在任何時候必定有一個保持空白。如果同時有資料存在於兩個Survivor區或者兩個區域的的使用量都是0,則意味著你的系統可能出現了執行錯誤。
老年代
存活在新生代中但未變為不可達的物件會被複制到老年代。一般來說老年代的記憶體空間比新生代大,所以在老年代GC發生的頻率較新生代低一些。當物件從老年代被移除時,我們稱之為 "Major GC"(或者Full GC)。 老年代使用標記-清理或標記-整理演算法
老年代裡放著什麼?
-
new 出來的大物件
-
長期存活的物件(前面說過)
-
如果在Survivor空間中相同年齡所有物件的綜合大於Survivor空間的一半,年齡大於或等於該年齡的物件就可以直接進入老年代,無須等待
MaxTenuringThreshold中要求的年齡(預設是15)。
空間分配擔保
在發生Minor GC前,虛擬機器會先檢查老年代最大可用的連續空間是否大於新生代所有物件總空間。
-
如果大於,那麼Minor GC可以確保是安全的。
-
如果小於,虛擬機器會檢視HandlePromotionFailure設定值是否允許擔任失敗。
-
如果允許,那麼會繼續檢查老年代最大可用連續空間是否大於歷次晉升老年代物件的平均大小
-
如果大於,將嘗試著進行一次Minor GC,儘管這次Minor GC是有風險的
-
.如果小於,進行一次Full GC.
-
-
如果不允許,也要改為進行一次Full GC.
-
前面提到過,新生代使用複製收集演算法,但為了記憶體利用率,只使用其中一個Survivor空間來作為輪換備份,因此當出現大量物件在Minor GC後仍然存活的情況時(最極端就是記憶體回收後新生代中所有物件都存活),就需要老年代進行分配擔保,讓Survivor無法容納的物件直接進入老年代。與生活中的貸款擔保類似,老年代要進行這樣的擔保,前提是老年代本身還有容納這些物件的剩餘空間,一共有多少物件會活下來,在實際完成記憶體回收之前是無法明確知道的,所以只好取之前每一次回收晉升到老年代物件容量的平均大小值作為經驗值,與老年代的剩餘空間進行比較,決定是否進行Full GC來讓老年代騰出更多空間。
取平均值進行比較其實仍然是一種動態概率的手段,也就是說如果某次Minor GC存活後的物件突增,遠遠高於平均值的話,依然會導致擔保失敗(Handle Promotion Failure)。如果出現了HandlePromotionFailure失敗,那就只好在失敗後重新發起一次Full GC。雖然擔保失敗時繞的圈子是最大的,但大部分情況下都還是會將HandlePromotionFailure開關開啟,避免Full GC過於頻繁,
虛擬機器的實現
上文講了JVM垃圾回收的原理和使用的演算法,接下來就該講JVM使用的具體的垃圾回收器了。垃圾回收器在JVM中作為一個守護執行緒執行,它不能過多的佔用系統資源,否則將會極大的影響使用者體驗。在從GC Roots開始對物件進行可達性分析時,需要STOP THE WORLD,因為如果不這麼做,程式一邊修改引用,GC收集器一邊進行標記,那麼標記的結果肯定是有問題的,所以收集器應當採取適當的措施減少這個停頓的時間。
在這裡以HotSpot為例子對虛擬機器演算法進行概要講解。
列舉根節點
從可達性分析中從GC Roots節點找引用為例,可作為GC Roots的節點主要是全域性性的引用與執行上下文中,如果要逐個檢查引用,必然消耗時間。
另外可達性分析對執行時間的敏感還體現在GC停頓上,因為這項分析工作必須在一個能確保一致性的快照中進行——這裡的“一致性”的意思是指整個分析期間整個系統執行系統看起來就行被凍結在某個時間點,不可以出現分析過程中物件引用關係還在不斷變化的情況,該點不滿足的話分析結果的準確性就無法得到保證。這點是導致GC進行時必須暫停所有Java執行執行緒的其中一個重要原因。
由於目前主流的Java虛擬機器都是準確式GC,做一檔執行系統停頓下來之後,並不需要一個不漏的檢查執行上下文和全域性的引用位置,虛擬機器應當有辦法得知哪些地方存放的是物件的引用。在HotSpot的實現中,是使用一組OopMap的資料結構來達到這個目的的。
安全點
在OopMap的協助下,HotSpot可以快速且準確的完成GC Roots的列舉,但可能導致引用關係變化的指令非常多,如果為每一條指令都生成OopMap,那將會需要大量的額外空間,這樣GC的空間成本會變的很高。
實際上,HotSpot也的確沒有為每條指令生成OopMap,只是在特定的位置記錄了這些資訊,這些位置被稱為安全點(SafePoint)。SafePoint的選定既不能太少,以致讓GC等待時間太久,也不能設定的太頻繁以至於增大執行時負荷。所以安全點的設定是以讓程式“是否具有讓程式長時間執行的特徵”為標準選定的。“長時間執行”最明顯的特徵就是指令序列的複用,例如方法呼叫、迴圈跳轉、異常跳轉等,所以具有這些功能的指令才會產生SafePoint。
對於SafePoint,另一個問題是如何在GC發生時讓所有執行緒都跑到安全點在停頓下來。這裡有兩種方案:搶先式中斷和主動式中斷。搶先式中斷不需要執行緒程式碼主動配合,當GC發生時,首先