
【問題】使用BeautifulSoup解析在python2和python3下表現不一樣?
我要解析的網址是:http://browse.renren.com/sAjax.do?ajax=1&q=&p=[{%22t%22:%22age%22,%22range%22:%221%22}]&s=0&u=874525581&act=search&offset=0&sort=0
貌似是需要人人賬號才能登陸。
我想要得到這個頁面一共十個使用者的id。從chrome開發者工具的Element中可以看到–>
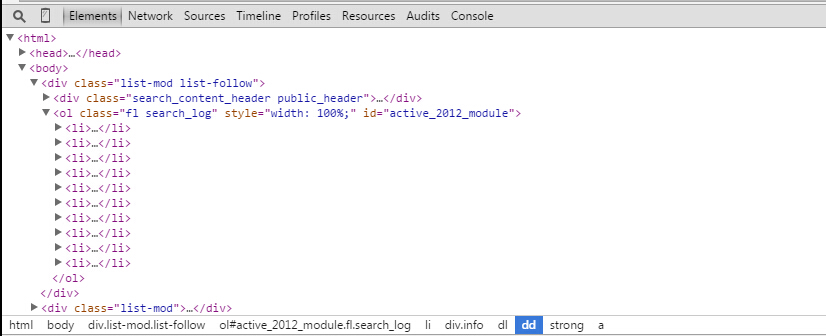
先找到 ol class=”fl search_log”等等等 這個標籤,再去找他的直接子孩子,10個 li 標籤(ol和li標籤在原始碼中也是有的,不用擔心在Element中有,在檢視網頁原始碼中沒有)。
於是我在python2中:
ageUrl = 'http://browse.renren.com/sAjax.do?ajax=1&q=&p=[{"t":"age","range":"1"}]&s=0&u=874525581&act=search&offset=%0&sort=0'
agePage = urllib2.urlopen(ageUrl).read()
liList = BeautifulSoup(agePage).find(class_=['f1', 'search_log']).find_all('li', recursive=False) 可以得到:

是10個
再看 ol class=f1 search_log… 標籤的孩子吧:
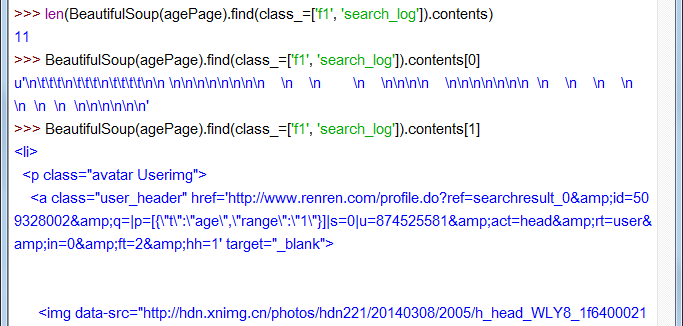
11個孩子,contents[1]顯示不全,是一個使用者的 li
我再用python3:

可以去看liList,它把所有10個li都作為列表的一項了(這裡就不放圖了)
再看 ol class=f1 search_log… 標籤的孩子吧
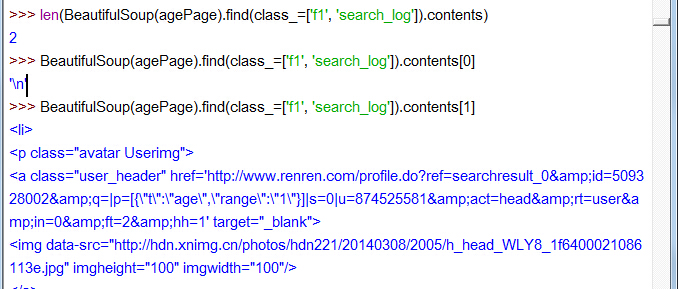
兩個孩子。contents[1]顯示不全,好長一溜兒呢,是10個使用者的 li
我不知道為什麼網頁結構解析的都不一樣
stackoverflow上有個問題Python3, BeautifulSoup dropping a paragraph tag
裡面有說到,對於網頁結構不好的頁面來說,使用不同的解析器結果是不同的。參見BeautifulSoup文件中的程式碼診斷:
如果想知道Beautiful Soup到底怎樣處理一份文件,可以將文件傳入 diagnose() 方法(Beautiful Soup 4.2.0中新增),Beautiful Soup會輸出一份報告,說明不同的解析器會怎樣處理這段文件,並標出當前的解析過程會使用哪種解析器:
from bs4.diagnose import diagnose
data = open("bad.html").read()
diagnose(data)
# Diagnostic running on Beautiful Soup 4.2.0
# Python version 2.7.3 (default, Aug 1 2012, 05:16:07)
# I noticed that html5lib is not installed. Installing it may help.
# Found lxml version 2.3.2.0
#
# Trying to parse your data with html.parser
# Here's what html.parser did with the document:
# ...那我就在python2,3中分別試下,看他們用的是什麼解析器

可以看到python2是html.parser。
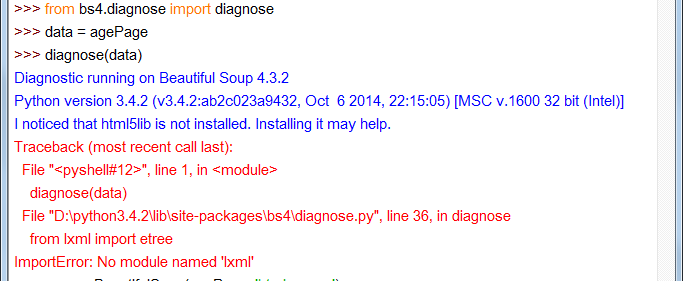
非常悲劇的看到,python3是先試了html5lib(不是說lxml最優先的麼?),再去找lxml,沒有居然報錯了,奇怪。算了,兩個都沒有,我想他也是用的html.parser咯。
所以py2和py3用的都是html.parser,然後結果不一樣。
我不知道怎麼解決。