
intellij idea本地配置連線遠端hadoop叢集開發
自己研究大資料一年多了,雖然技術上有很多提高,但是有個問題就是一直沒法使用本地聯調叢集,每次都是寫完打包放到叢集執行。最近發現可以本地直接連線遠端聯調,大大提高了開發效率,分享一下。
1、下載hadoop,配置到本地環境變數中,路徑中最好不要有空格或下劃線
環境變數:
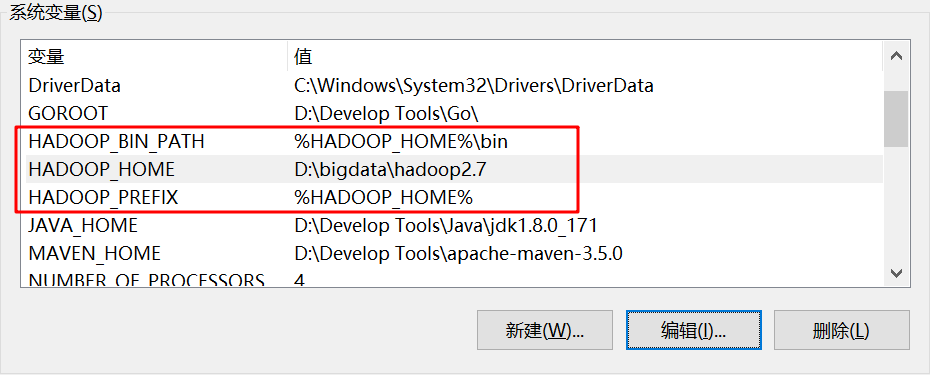
2、修改專案的pom.xml
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>commons-cli</groupId> <artifactId>commons-cli</artifactId> <version>1.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency>
3、把叢集中core-site.xml和hdfs-site.xml兩個檔案拿下來,放到專案中resources目錄下
4、設定Intellij idea中執行變數:
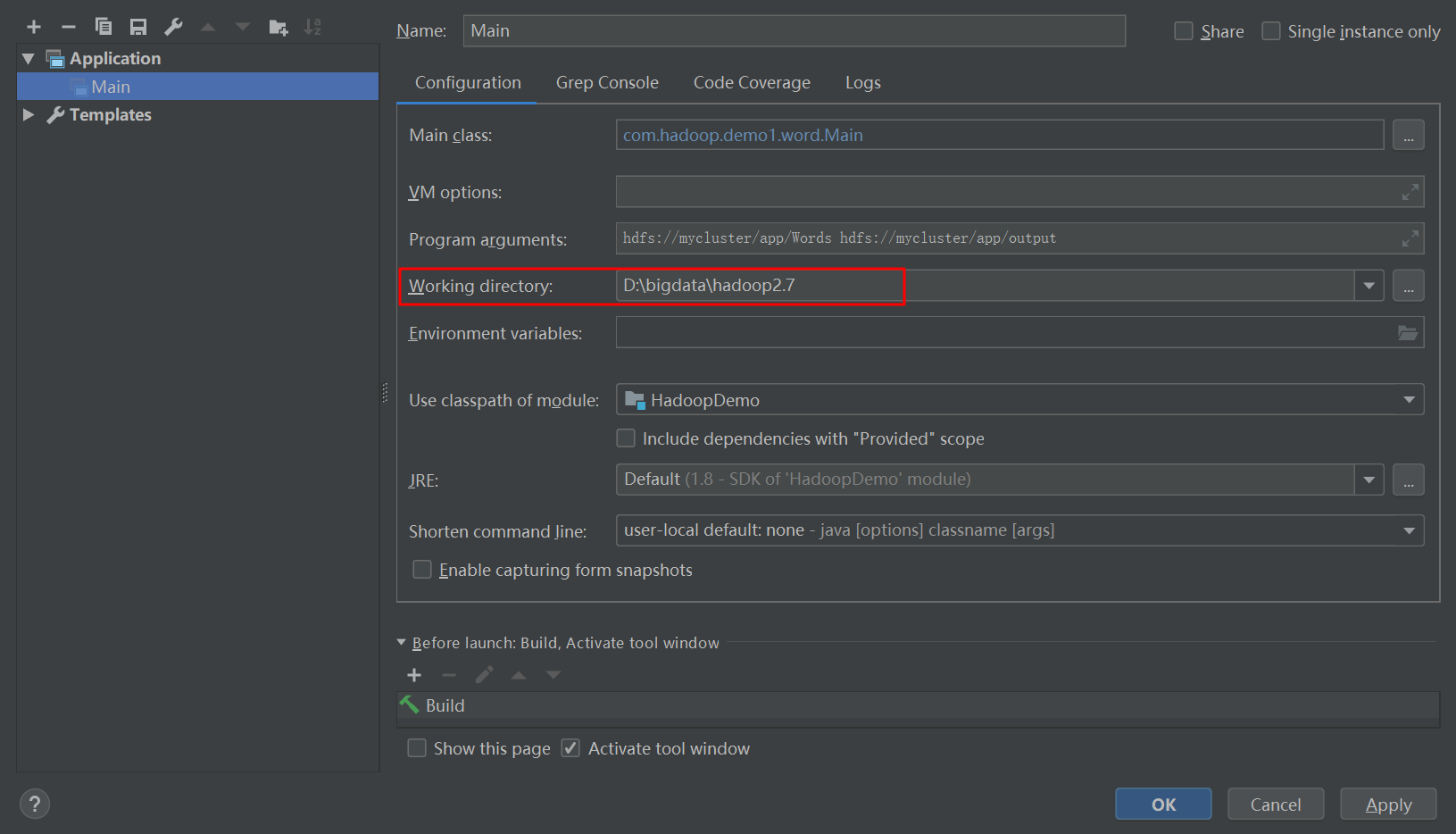
這裡的working directory設定為hadoop的安裝地址。至於上面的Program arguments,這是設定執行時傳遞的引數,可以傳值,直接編寫到程式中也可以。
這個地方遇到了坑,網上都是設定的單機IP地址加埠,比如hdfs://192.168.xx.xx:9000/...這種樣式的,我也一直測試但都是報不能連線9000埠。還一直以為自己哪裡配錯了。但是後來想明白了,既然是連線操作hdfs,那應該是8020埠,換了之後果然連通了。**如果這裡用的是IP地址加埠,那resources中core-site.xml中也要使用同樣的。**我這裡使用的是叢集名稱的方式,resources中core-site.xml中也要使用同樣的方式。如果兩個不一樣,會報錯誤。不建議使用IP的方式,假如配置使用的IP在啟動的時候是standby角色的namenode,執行的時候會報不能寫的錯誤,所以最好是使用hdfs://叢集服務名
5、這個時候執行會報錯:Unable to load native-hadoop library for your platform… using builtin-Java classes where applicable,需要下載hadoop.dll,然後替換掉本地hadoop中bin目錄下的檔案。至於winutils.exe,我是沒有替換也能正常執行,可換可不換。
下載地址:
6、執行繼續報錯
org.apache.hadoop.security.AccessControlException: Permission denied: user=ZhOu, access=WRITE, inode="/app":root:supergroup:drwxr-xr-x
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
7、做到這裡,就可以正常執行了。不需要每次打包放到線上執行了。Spark專案也是一樣的做法,只是把working directory設定為spark的安裝路徑即可。