
Linux效能及調優指南(翻譯)之Linux程序管理
本文為IBM RedBook的Linux Performanceand Tuning Guidelines的1.1節的翻譯
原文地址:http://www.redbooks.ibm.com/redpapers/pdfs/redp4285.pdf
原文作者:Eduardo Ciliendo, Takechika Kunimasa, Byron Braswell
譯文如下:
1.1 Linux程序管理
程序管理是作業系統的最重要的功能之一。有效率的程序管理能保證一個程式平穩而高效地執行。Linux的程序管理與UNIX的程序管理相似。它包括程序排程、中斷處理、訊號、程序優先順序、上下文切換、程序狀態、進度記憶體等。
在本節中,我們將描述Linux程序管理的基本原理的實現。它將更好地幫助你理解Linux核心如何處理程序及其對系統性能的影響。
1.1.1 什麼是程序?
一個程序是一個執行在處理器的程式的一個例項。該程序使用Linux核心能夠處理的任何資源來完成它的任務。
所有執行在Linux作業系統中的程序都被task_struct結構管理,該結構同時被叫作程序描述。一個程序描述包含一個執行程序所有的必要資訊,例如程序標識、程序屬性和構建程序的資源。如果你瞭解該程序構造,你就能理解對於程序的執行和效能來說,什麼是重要的。圖1-2展示了程序結構相關的程序資訊概述。
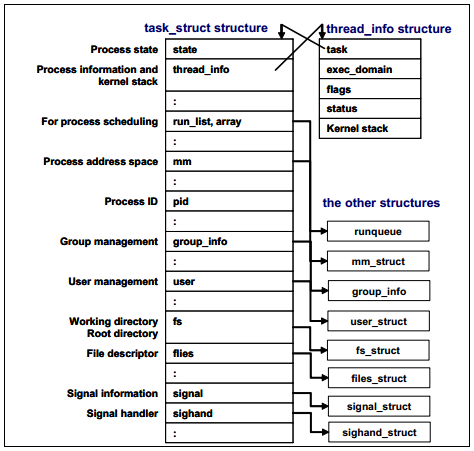
圖1-2 task_struct結構體
1.1.2 程序的生命週期
每一個程序都有其生命週期,例如建立、執行、終止和消除。這些階段會在系統啟動和執行中重複無數次。因此,程序的生命週期對於其效能的分析是非常重要的。
圖1-3展示了經典的程序生命週期。
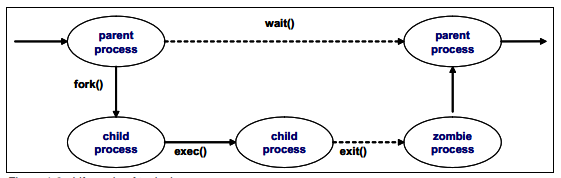
圖1-3 經典的程序生命週期
當一個程序建立一個新的程序,程序的建立程序(父程序)呼叫一個fork()系統呼叫。當fork()系統呼叫被呼叫,它得到該新建立程序(子程序)的程序描述並呼叫一個新的程序id。它複製該值到父程序程序描述到子程序中。此時整個的父程序的地址空間是沒有被複制的;父子程序共享相同的地址空間。
exec()系統呼叫複製新的程式到子程序的地址空間。因為父子程序共享地址空間,寫入一個新的程式的資料會引起一個分頁錯誤。在這種情況下,記憶體會分配新的實體記憶體頁給子程序。
這個推遲的操作叫作寫時複製。子程序通常執行他們自己的程式而不是與父程序執行相同的程式。這個操作避免了不必要的開銷,因為複製整個地址空間是一個非常緩慢和效率低下的操作,它需要使用大量的處理器時間和資源。
當程式已經執行完成,子程序通過呼叫exit()系統呼叫終止。exit()系統呼叫釋放程序大部分的資料並通過傳送一個訊號通知其父程序。此時,子程序是一個被叫作殭屍程序的程序(參閱page 7的“Zombie processes”)。
子程序不會被完全移除直到其父程序知道其子程序的呼叫wait()系統呼叫而終止。當父程序被通知子程序終止,它移除子程序的所有資料結構並釋放它的程序描述。
1.1.3 執行緒
一個執行緒是一個單獨的程序生成的一個執行單元。它與其他的執行緒並行地執行在同一個程序中。各個執行緒可以共享程序的資源,例如記憶體、地址空間、開啟的檔案等等。它們能訪問相同的程式資料集。執行緒也被叫作輕量級的程序(Light Weight Process,LWP)。因為它們共享資源,所以每個執行緒不應該在同一時間改變它們共享的資源。互斥的實現、鎖、序列化等是使用者程式的責任。
從效能的角度來說,建立執行緒的開銷比建立程序少,因數建立一個執行緒時不需要複製資源。另一方面,程序和執行緒擁在排程演算法上有相似的特性。核心以相似的方式處理它們。
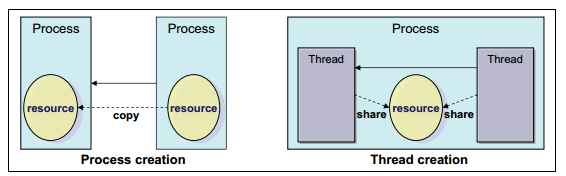
圖1-4 程序和執行緒
在現在的Linux實現中,執行緒支援UNIX的可移植作業系統介面(POSIX)標準庫。在Linux作業系統中有幾種可用的執行緒實現。以下是廣泛使用的執行緒庫:
LinuxThreads
LinuxThreads自從Linux核心2.0起就已經被作為預設的執行緒實現。LinuxThreads的一些實現並不符合POSIX標準。Native POSIX Thread Library(NPTL)正在取代LinuxThreads。LinuxThreads在將來的Linux企業發行版中將不被支援。
Native POSIX Thread Libary(NPTL)
NPTL最初是由紅帽公司開發的。NPTL與POSIX更加相容。通過Linux核心2.6的高階特性,例如,新的clone()系統呼叫、訊號處理的實現等等,它具有比LinuxThreads更高的效能和伸縮性。
NPTL與LinuxThreads有一些不相容。一個依賴於LinuxThreads的應用可能不能在NPTL實現中工作。
Next Generation POSIX Thread(NGPT)
NGPT是一個IBM開發的POSIX執行緒庫。現在處於維護階段並且在未來也沒有開發計劃。
使用LD_ASSUME_KERNEL環境變數,你可以選擇在應用中使用哪一個執行緒庫。
1.1.4 程序優先順序和nice值
程序優先順序是一個數值,它通過動態的優先順序和靜態的優先順序來決定程序被CPU處理的順序。一個擁有更高程序優先順序的程序擁有更大的機率得到處理器的處理。
核心根據程序的行為和特性使用試探演算法,動態地調整調高或調低動態優先順序。一個使用者程序可以通過使用程序的nice值間接改變靜態優先順序。一個擁有更高靜態優先順序的程序將會擁有更長的時間片(程序能在處理上執行多長時間)。
Linux支援從19(最低優先順序)到-20(最高優先順序)的nice值。預設值為0。把程式的nice值修改為負數(使程序的優先順序更高),需要以root身份登陸或使用su命令以root身份執行。
1.1.5 上下文切換
在程序執行過程中,程序的執行資訊被保存於處理器的暫存器和它的快取中。正在執行的程序載入到暫存器中的資料集被稱為上下文。為了切換程序,執行中程序的上下文將會被儲存,接下來的執行程序的上下文將被被恢復到暫存器中。程序描述和核心模式堆疊的區域將會用來儲存上下文。這個切換被稱為上下文切換。過多的上下文切換是不受歡迎的,因為處理器每次都必須清空重新整理暫存器和快取,為新的程序製造空間。它可能會引起效能問題。
圖1-5 說明了上下文切換如何工作。
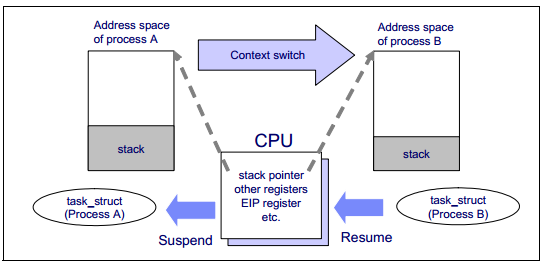
圖1-5 上下文切換
1.1.6 中斷處理
中斷處理是優先順序最高的任務之一。中斷通常由I/O裝置產生,例如網路介面卡、鍵盤、磁碟控制器、序列介面卡等等。中斷處理器通過一個事件通知核心(例如,鍵盤輸入、乙太網幀到達等等)。它讓核心中斷程序的執行,並儘可能快地執行中斷處理,因為一些裝置需要快速的響應。它是系統穩定的關鍵。當一箇中斷訊號到達核心,核心必須切換當前的程序到一個新的中斷處理程序。這意味著中斷引起了上下文切換,因此大量的中斷將會引起效能的下降。
在Linux的實現中,有兩種型別的中斷。硬中斷是由請求響應的裝置發出的(磁碟I/O中斷、網路介面卡中斷、鍵盤中斷、滑鼠中斷)。軟中斷被用於處理可以延遲的任務(TCP/IP操作,SCSI協議操作等等)。你可以在/proc/interrupts檔案中檢視硬中斷的相關資訊。
在多處理器的環境中,中斷被每一個處理器處理。繫結中斷到單個的物理處理中能提高系統的效能。更多的細節,請參閱4.4.2,“CPU的中斷處理親和力”。
1.1.7 程序狀態
每一個程序擁有自己的狀態,狀態表示了程序當前在發生什麼。
在程序的執行期間程序的狀態會發生改變。一些程序的狀態如下:
TASK_RUNNING
在此狀態下,表示程序正在CPU中執行或在佇列中等待執行(執行佇列)。
TASK_STOPPED
在此狀態下的程序被某些訊號(如SIGINT,SIGSTOP)暫停。程序正在等待通過一個訊號恢復執行,例如SIGCONT。
TASK_INTERRUPTIBLE
在此狀態下,程序被暫停並等待一個某些條件狀態的到達。如果一個程序處於TASK_INTERRUPTIBLE狀態並接收到一個停止的訊號,程序的狀態將會被改變並中斷操作。一個典型的TASK_INTERRUPTIBLE狀態的程序的例子是一個程序等待鍵盤中斷。
TASK_UNINTERRUPTIBLE
與TASK_INTERRUPTIBLE相似。當一個程序處於TASK_UNINTERRUPTIBLE狀態可以被中斷,向處於TASK_UNINTERRUPTIBLE狀態的程序傳送一個訊號不會發生任何操作。一個TASK_UNINTERRUPTIBLE程序的典型的例子是等待磁碟I/O操作。
TASK_ZOMBIE
當一個程序呼叫exit()系統呼叫退出後,它的父程序應該知道該程序的終止。處於TASK_ZOMBIE狀態的程序會等待其父程序通知其釋放所有的資料結構。
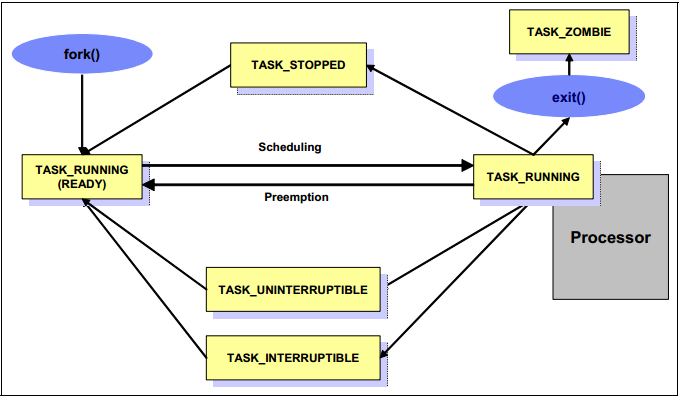
圖1-6 程序狀態
殭屍程序
當一個程序接收到一個訊號而終止,它在結束自己之前,通常需要一些時間來結束所有的任務(例如關閉開啟的檔案)。在這個通常非常短暫的時間內,該程序就是一個殭屍程序。
程序已經完成所有的關閉任務後,它會向父程序報告其即將終止。有些時候,一個殭屍程序不能把自己終止,這將會引導它的狀態顯示為z(zombie)。
使用kill命令來關閉這樣的一個程序是不可能的,因為該程序已經被認為已經死掉了。如果你不能清除殭屍程序,你可以結束其父程序,然後殭屍程序也隨之消失。但是,如果父程序為init程序,你不能結束它。init程序是一個非常重要的程序,因此可能需要重啟系統來清除殭屍程序。
1.1.8 程序記憶體段
程序使用其自身的記憶體區域來執行工作。工作的變化根據情況和程序的使用而決定。程序可以擁有不同的工作量特性和不同的資料大小需求。程序必須處理各種資料大小。為了滿足需求,Linux核心為每個程序使用動態申請記憶體的機制。程序記憶體分配的資料結構如圖1-7所示。
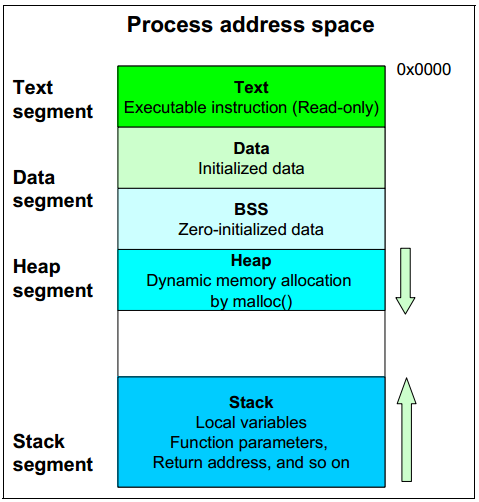
圖1-7 程序地址空間
程序記憶體區由以下幾部分組成:
Text段
該區域用於儲存執行程式碼。
Data段
資料段包括三個區域。
- Data:該區域儲存已被初始化的資料,如靜態變數。
- BSS:該區域儲存初始化為0的資料。資料被初始化為0。
- Heap:該區域用於根據需求使用malloc()動態申請的記憶體。堆向高地址方向增長。
Stack段
該區域用於儲存區域性變數、函式引數和返回函式的地址。棧向低地址方向增長。
使用者程序的地址空間記憶體分佈可以使用pmap命令來檢視。你可以使用ps命令來檢視記憶體段的大小。可以參閱2.3.10的“pmap”,“ps和pstree”。
1.1.9 Linux CPU排程
任何的計算機的基本功能都非常簡單,就是計算。為了能夠計算,它意味著必須管理計算資源或處理器和計算任務,也就是我們所知道的執行緒或程序。感謝Ingo Molnar的巨大貢獻,Linux核心使用一個O(1)的演算法代替以前的O(n)的CPU排程演算法。O(1)指的是一種靜態的演算法,意味著選擇一個程序並執行所花費的時間是一個常數,不管程序的數量的大小。
新的排程演算法的擴充套件性非常好,不管程序的數量或者處理器的數量是多少,系統的開銷都是非常少的。該演算法使用兩個程序優先順序陣列:
active(活動的)
expired(過期的)
排程器根據程序的優先順序和優先攔截率為程序分配時間片,然後程序以優先順序順序放置到active陣列內。當程序時間片耗盡,程序申請一個新的時間片並放置到expired陣列內。當active陣列中的所有程序的時間片耗盡,這兩個陣列進行切換,重新執行該演算法。對於一般的互動式程序(相對於實時程序),擁有高優先順序的程序通常比低優先順序的程序得到更長的時間片和更多的計算時間,但這並不表示低優先順序的程序會被完全忽略(餓死)。該演算法的優勢是為擁有大量執行緒和程序並擁有多處理器的企業級環境提升Linux核心的擴充套件性。該O(1)的新CPU排程器是為記憶體2.6設計的,但是現在已經移植到2.4系列中。圖1-8說明了Linux CPU如何排程工作。
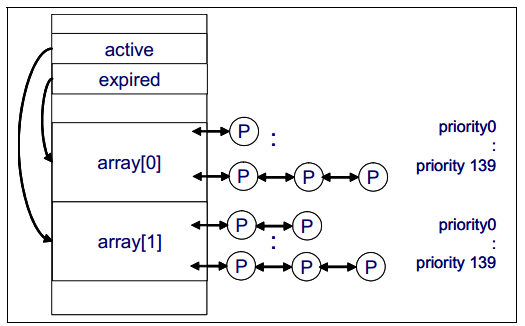
圖1-8 Linux核心2.6 O(1)排程器
新排程器的另一個顯著改進是支援非一致性記憶體架構(NUMA)和對稱多執行緒處理器,例如Intel超執行緒技術。
改進後的NUMA支援確保只有某個節點過載時,負載平衡才會跨越某個NUMA節點。這個機制確保了在NUMA系統相對比較緩慢的擴充套件連結流量的最小化。儘管每個排程節拍時負載平衡會遍歷排程域群組中的處理器,但只有在節點過載並請求負載平衡時,負載才會跨越排程域轉移。
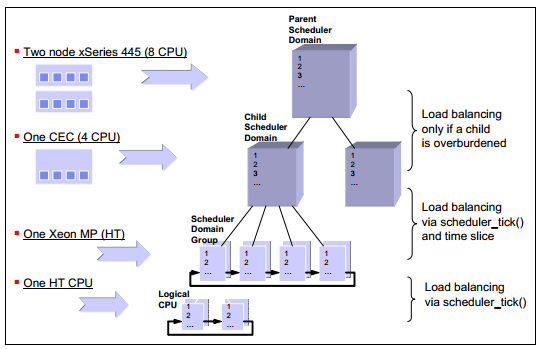
圖1-9 O(1)CPU排程器結構