
將句子表示為向量(上):無監督句子表示學習(sentence embedding)
1. 引言
word emedding技術如word2vec,glove等已經廣泛應用於NLP,極大地推動了NLP的發展。既然詞可以embedding,句子也應該可以(其實,萬物皆可embedding,Embedding is All You Need ^_^)。近年來(2014-2018),許多研究者在研究如何進行句子表示學習,從而獲得質量較高的句子向量(sentence embedding)。事實上,sentence embedding在信息檢索,句子匹配,句子分類等任務上均有廣泛應用,並且上述任務往往作為下遊任務來評測sentence embedding的好壞。本文將介紹如何用無監督學習方法來獲取sentence embedding,是對近期閱讀的sentence embedding論文筆記的總結(https://github.com/llhthinker/NLP-Papers#distributed-sentence-representations)。歡迎轉載,請保留原文鏈接https://www.cnblogs.com/llhthinker/p/10335164.html
2. 基於詞向量的詞袋模型
獲取sentence embedding最直接最簡單的思路就是對一個句子中所有詞的word embedding進行組合。這種方法最明顯的缺點是沒有考慮詞序信息,但是足夠簡單高效,在一些任務上是很好的baseline。
2.1 平均詞向量與TFIDF加權平均詞向量
平均詞向量就是將句子中所有詞的word embedding相加取平均,得到的向量就當做最終的sentence embedding。這種方法的缺點是認為句子中的所有詞對於表達句子含義同樣重要。TFIDF加權平均詞向量就是對每個詞按照tfidf進行打分,然後進行加權平均,得到最終的句子表示。
2.2 SIF加權平均詞向量
發表於2016年的論文A simple but tough-to-beat baseline for sentence embeddings提出了一種非常簡單但是具有一定競爭力的句子向量表示算法。算法包括兩步,第一步是對句子中所有的詞向量進行加權平均,得到平均向量\(v_s\);第二步是移出(減去)\(v_s\)在所有句子向量組成的矩陣的第一個主成分(principal component / singular vector)上的投影,因此該算法被簡記為WR(W:weighting, R: removing)。
第一步主要是對TFIDF加權平均詞向量表示句子的方法進行改進。論文提出了一種平滑倒詞頻

論文實驗表明該方法具有不錯的競爭力,在大部分數據集上都比平均詞向量或者使用TFIDF加權平均的效果好,在使用PSL作為詞向量時甚至能達到最優結果。當然,由於PSL本身是基於有監督任務(短語對)來訓練詞向量,因此PSL+WR能在文本蘊含或相似度計算任務上達到甚至打敗LSTM的效果也在情理之中。代碼開源在https://github.com/PrincetonML/SIF
3. 無監督句子表示學習
下面介紹的方法是在無標簽語料上訓練句子表示學習模型,基本思想都是在無標簽訓練數據上設計監督學習任務進行學習,因此這裏所說的無監督句子表示學習著重於訓練數據是無標簽的。
3.1 Paragraph Vector: PV-DM與PV-DBOW
發表於2014年的論文Distributed representations of sentences and documents提出了兩個模型用於學習句子和文檔分布式表示(段落向量,Paragraph vector)。Paragraph Vector: A distributed memory model(PV-DM) 是論文提出的第一個學習段落向量的模型,如下圖:
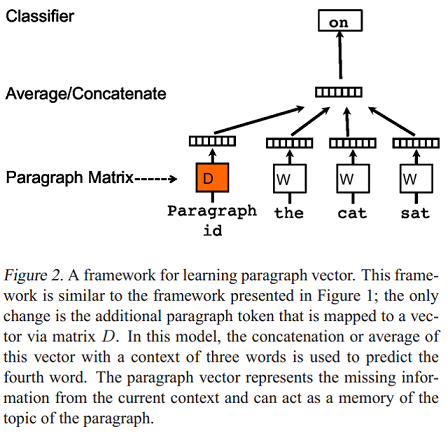
模型的具體步驟如下:
- 每個段落都映射到一個唯一的向量,由矩陣\(D?\)中的一列表示,每個詞也被映射到一個唯一的向量,表示為\(W?\) ;
- 對當前段落向量和當前上下文所有詞向量一起進行取平均值或連接操作,生成的向量用於輸入到softmax層,以預測上下文中的下一個詞: \[y=b+Uh(w_{t-k}, \dots, w_{t+k}; W; D)?\]
這個段落向量可以被認為是另一個詞。可以將它理解為一種記憶單元,記住當前上下文所缺失的內容或段落的主題 。矩陣\(D?\) 和\(W?\) 的區別是:
- 通過當前段落的index,對\(D\) 進行Lookup得到的段落向量,對於當前段落的所有上下文是共享的,但是其他段落的上下文並不會影響它的值,也就是說它不會跨段落(not across paragraphs) ;
- 當時詞向量矩陣\(W\)對於所有段落、所有上下文都是共享的。
Paragraph Vector without word ordering: Distributed bag of words (PV-DBOW) 是論文提出的第二個學習段落向量的模型,如下圖:
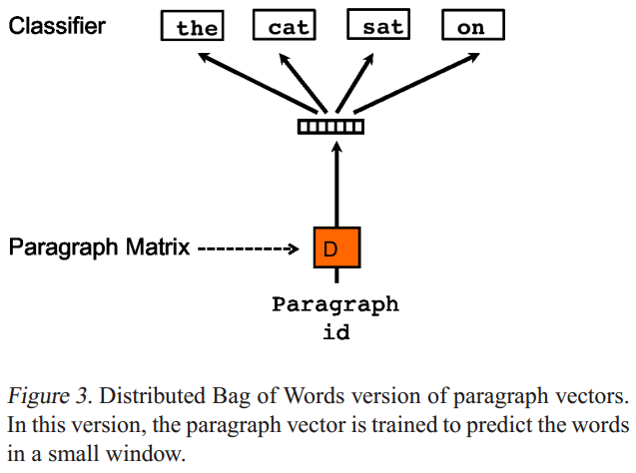
- PV-DBOW模型的輸入忽略了的上下文單詞,但是關註模型從輸出的段落中預測從段落中隨機抽取的單詞;
- PV-DBOW模型和訓練詞向量的Skip-gram模型非常相似。
PV-DM與PV-DBOW的優點它們不僅能獲取句子向量,也能獲取文檔級別向量。論文的工作很有影響力,具體實現已經集成在gensim包中。
3.2 利用篇章級文本的句子連貫性
2014年發表的論文A Model of Coherence Based on Distributed Sentence Representation提出了一種基於分布式句子表示的模型,用來判斷文本連貫性(Coherence)。模型的輸入是多個句子(a window of sentences),輸出是這些句子是連續的概率。模型的主要步驟如下:
- 對每個句子進行編碼:論文實現了循環神經網絡編碼和遞歸神經網絡編碼兩種方式,將每個句子表示成一個\(k \times 1\)的語義向量\(h_{s_i}, i = 1,...,L\),其中\(L\)為句子個數(窗口大小);
- 將一個窗口內的所有句子的語義向量進行級聯,得到大小為\((L \times k) \times 1\)的語義向量\(h_C = [h_{s_1},h_{s_2},...,h_{s_L}]\)後,進行非線性變換,即\(q_C=tanh(W_{sen} \times h_C + b_{sen})\),得到大小為\(H \times 1\)的隱藏層語義表示向量\(q_C\),其中\(W_{sen}\)為大小為\(H \times (L \times k)\)的矩陣,\(b_{sen}\)為大小為\(H \times 1\)的偏移向量;
- 最後將\(q_C\)輸入到全連接層進行二分類,即\(p(y_C=1) = sigmoid(U^Tq_C + b)\),其中\(y_C=1\)表示該窗口中的句子是連貫的,等於0則表示不連貫。
給定一篇包含\(N_d\)個句子的文檔\(d={s_1,s_2, ...,s_{N_d}}\),假設\(L=3\),可以生成如下的樣本:
\[ < s _ { \text{start} } , s _ { 1 } , s _ { 2 } > , < s _ { 1 } , s _ { 2 } , s _ { 3 } > , \ldots \\ < s _ { N _ { d } - 2 } , s _ { N _ { d } - 1 } , s _ { N _ { d } } > , < s _ { N _ { d } - 1 } , s _ { N _ { d } } , s _ { e n d } > \]
文檔\(d\)的連貫性得分\(S_d\)可以定義為所以樣本連貫性概率的乘積(得分越大表示越連貫),即
\[
S _ { d } = \prod _ { C \in d } p \left( y _ { C } = 1 \right)
\]
雖然論文的任務是判斷文本連貫性,給了後續的研究者研究句子分布式表示的啟示:類似於word2vec中使用相鄰詞預測的方式來獲得word embedding,可以通過句子連貫性這個任務自動構建數據集,無需標註即可得到sentence embedding。
3.3 基於Encoder-decoder的Skip-Thought Vectors
2015年發表的論文Skip-Thought Vectors提出了Skip-Thought模型用於得到句子向量表示Skip-Thought Vectors。基本思想是word2vec中的skip-gram模型從詞級別到句子級別的推廣:對當前句子進行編碼後對其周圍的句子進行預測。具體地,skip-thought模型如下圖,給定一個連續的句子三元組,對中間的句子進行編碼,通過編碼的句子向量預測前一個句子和後一個句子。Skip-Thought向量的實驗結果表明,可以從相鄰句子的內容推斷出豐富的句子語義。代碼開源在https://github.com/tensorflow/models/tree/master/research/skip_thoughts

模型的基本架構與encoder-decoder模型類似,論文中使用的encoder和decoder都為GRU,使用單向GRU稱為uni-skip,雙向GRU稱為bi-skip,將uni-skip和bi-skip生成的sentence embedding進行concat稱為combine-skip。論文通過大量實驗對比了上述三種變體的效果,總體上來說是uni-skip < bi-skip < combine-skip。
詞表擴展是該篇論文的重要trick。skip-thought模型的詞表規模往往是遠小於現實中的詞表(如用海量數據訓練的word2vec)。為了讓模型能夠對任意句子進行編碼,受論文Exploiting similarities among languages for machine translation的啟發,本文訓練一個線性映射模型,將word2vec的詞向量映射為skip-thought模型encoder詞表空間的詞向量。假設訓練後的skip-thought模型的詞向量矩陣為X,大小為[num_words,dim1],即詞表大小為num_words,詞向量維度為dim1,這num_words個詞在word2vec中對應的詞向量矩陣為Y,大小為[num_words, dim2],即word2vec的詞向量維度為dim2。我們的目的是word2vec中的詞向量通過線性變換後得到詞向量與skip-thought模型encoder空間的詞向量無限接近,因此最小化線性回歸\(loss= || X - Y * W ||^2\)。得到這個線性模型後,假設待編碼的句子中的某個詞不屬於skip-thought詞表,則首先在word2vec詞表中進行look up得到word2vec對應的詞向量,再通過線性模型映射為skip-thought模型encoder空間的詞向量。
3.4 基於AutoEncoder的序列去噪自編碼器(SDAE)
2016年發表的論文Learning Distributed Representations of Sentences from Unlabelled Data提出的第一種模型稱為序列去噪自編碼器(SDAE: Sequential Denoising AutoEncoder)。AutoEncoder包括編碼器和解碼器兩部分,輸入信息通過編碼器產生編碼信息,再通過解碼器得到輸入信息,模型的目標是使輸出信息和輸入信息原來越接近。DAE (Denoising AutoEncoder)表示模型的輸入信息首先經過了噪聲處理後再進行編碼和解碼,並且希望解碼的輸出信息是不含噪聲的輸入信息,即去噪。DAE常用於圖像處理,本文提出SDAE模型表示用來處理變長的句子(序列)。具體地,給定句子\(S\),采用噪聲函數:\(N(S|p_0,p_x)\),其中\(p_0, p_x\)為0到1之間的概率值。首先,對於\(S\)中的每個詞\(w\),噪聲函數\(N\)按照概率\(p_0\)隨機刪除\(w\),然後對於\(S\)中每個不重疊的bigram \(w_iw_{i+1}\),噪聲函數\(N\)按照概率\(p_x\)對\(w_i\)和\(w_{i+1}\)進行交換。論文采用基於LSTM的encoder-decoder模型,SDAE的目標是預測出原始句子\(S\)。SDAE模型在驗證集上對超參數\(p_0,p_x \in {0.1, 0.2, 0.3}\)進行搜索,得到當\(p_0=p_x=0.1\)為最優結果。論文還嘗試令\(p_0=p_x=0?\)進行對比實驗,SDAE模型即變成了SAE模型。 SDAE模型相較於Skip-Thought的優點是只需要輸入單個句子,即不要求句子所在的文本是有序的,而Skip-Thought的輸入必須是三個有序的句子。
3.5 基於詞袋模型的FastSent
2016年發表的論文Learning Distributed Representations of Sentences from Unlabelled Data提出的第二種模型稱為FastSent,Skip-Thought模型采取語言模型形式的編碼解碼方式,導致其訓練速度會很慢。FastSent采取了BoW(詞袋)形式的編碼方式,使得模型訓練速度大幅提高,因此稱為FastSent。具體地,給定一個連續的句子三元組\(S_{i-1}, S_i, S_{i+1}\),對中間的句子\(S_{i}\)進行編碼,編碼方式是\(S_i\)中所有詞的詞向量之和,即\(\mathbf { s } _ { \mathbf { i } } = \sum _ { w \in S _ { i } } u _ { w }\),然後根據\(\mathbf { s } _ { \mathbf { i } }\)對\(w \in S_{i-1} \cup S_{i+1}?\)進行預測,這與word2vec模型中的skip-gram基本一致,而無需像Skip-Thought一樣按照句子中詞的順序生成(預測)。因此FastSent的損失函數如下:
\[
\sum _ { w \in S _ { i - 1 } \cup S _ { i + 1 } } \phi \left( \mathbf { s } _ { \mathbf { i } } , v _ { w } \right)
\]
其中\(\phi \left( v _ { 1 } , v _ { 2 } \right)\)為softmax函數,\(v_w\)為目標句子中的詞\(w\)的embedding。論文還提出了一種變體模型FastSent+AE,該變體不光是預測前後兩個句子中的詞,還預測本身句子的詞,損失函數即為:
\[
\sum _ { w \in S _ { i - 1 } \cup S _ { i } \cup S _ { i + 1 } } \phi \left( \mathbf { s _ { i } } , v _ { w } \right)
\]
模型訓練後,測試階段,FastSent能夠通過計算句子中所有詞向量的和迅速得到句子embedding,即:\(\mathbf { s } = \sum _ { w \in S } u _ { w }?\)。
論文通過兩種類型的下遊任務來評測句子分布式表示的質量,分別為監督類型(包括釋義識別,文本分類)和非監督類型(語義相關性:SICK數據集與STS數據集,直接計算句子向量的余弦相似度並與人類打分進行比較)。實驗結果為SDAE模型在監督類型評測上比CBOW(將CBOW類型詞向量直接相加得到句子向量)和Skipgram等簡單模型要好,但是在非監督類型評測上結果卻相反。類似地,Skip-Thought模型在監督類型評測上比FastSent模型效果好,但在非監督類型評測上,FastSent要好於Skip-Thought。實驗結果表明,最佳方法主要取決於預期的應用。 更深,更復雜的模型(同時也需要更多的計算資源和訓練時間)更適用於監督類型評測,但淺的對數線性模型更適合無監督類型評測。
3.6 利用n-grams embedding
2017年發表的論文Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features 提出利用n-grams來學習句子表示模型Sent2Vec,是word2vec模型中CBOW形式的擴展:不僅僅使用窗口中的詞(uni-gram)來預測目標詞,而是使用窗口中所有的n-grams來預測目標詞(uni-gram)。為了得到句子向量,將句子看成一個完整的窗口,模型的輸入為句子中的n-grams,目標是預測句子中的missing word(目標詞),而句子向量是所有n-grams向量表示的平均。本文的模型與論文Enriching word vectors with subword information(FastText)很類似,主要區別有兩點,其一是本文的模型輸入是詞級別的n-grams序列而FastText是字符級別的n-grams序列,其二是本文最終的表示是對輸入的n-grams embedding進行平均而FastText是相加。代碼開源在https://github.com/epfml/sent2vec
3.7 Quick-Thought vectors
2018年發表的論文An efficient framework for learning sentence representations提出了一種簡單且有效的框架用於學習句子表示。和常規的編碼解碼類模型(如skip-thoughts和SDAE)不同的是,本文采用一種分類器的方式學習句子表示。具體地,模型的輸入為一個句子\(s\)以及一個候選句子集合\(S_{cand}\),其中\(S_{cand}\)包含一個句子\(s_{ctxt}\)是\(s\)的上下文句子(也就是\(s\)的前一個句子或後一個句子)以及其他不是\(s\)上下文的句子。模型通過對\(s\)以及\(S_{cand}\)中的每個句子進行編碼,然後輸入到一個分類器中,讓分類器選出\(S_{cand}\)中的哪個句子是\(s_{ctxt}\)。實驗設置候選句子集合大小為3,即\(S_{cand}?\)包含1個上下文句子和兩個無關句子。模型結構如下:

模型有如下兩個細節需要註意:
- 模型使用的分類器(得分函數)\(c\)非常簡單,是兩個向量內積,即\(c(u, v)=u^Tv\),計算\(s\)的embedding與所有\(S_{cand}\)中的句子向量內積得分後,輸入到softmax層進行分類。使用簡單分類器是為了引導模型著重訓練句子編碼器,因為我們的目的是為了得到好的句子向量表示而不是好的分類器。
- 雖然某些監督任務模型如文本蘊含模型是參數共享的,\(s\)的編碼器參數和候選句子編碼器參數是不同的(不共享),因為句子表示學習往往是在大規模語料上進行訓練,不必擔心參數學習不充分的問題。測試時,給定待編碼句子\(s\),通過該模型得到的句子表示是兩種編碼器的連結 \([ f ( s ) ;g ( s ) ]\)。
論文將上述模型命名為quick thoughts(QT),意味著該模型能夠迅速有效地學習句子表示向量。模型使用GRU作為Encoder,為了和Skip-Tought模型進行比較,模型包含三種變體,使用單向GRU稱為uni-QT,雙向GRU稱為bi-QT,將uni-QT和bi-QT生成的sentence embedding進行concat稱為combine-QT。此外,論文將同時使用預訓練詞向量和隨機初始化詞向量的模型稱為MultiChannel-QT(MC-QT),這種設置是參照multi-channel CNN模型。
論文通過多個句子分類任務證明QT模型了的優越性:
- 相較於其他無監督句子表示學習方法,QT在訓練時間較少的情況下(相較於Skip-Thought、SDAE),能夠達到非常不錯的效果,在大多數數據集上的效果都是最好的。
- 與監督句子表示學習方法(如InferSent等)對比,QT(MC-QT)同樣能夠在大多數數據集上取得最優效果。
- 與專門用於句子分類任務模型(如CNN)對比,QT使用ensemble,考慮模型類型(單向/雙向),詞向量(隨機/預訓練)以及數據集(BookCorpus/UMBC )三個方面進行訓練不同的模型進行集成,也取得了有競爭力的效果。
論文還通過image-sentence ranking和nearest neighbors兩個實驗來為QT有效性提供依據。代碼開源在https://github.com/lajanugen/S2V
4. 總結
- 詞向量的平均或加權平均是一個簡單有效的baseline,基於SIF詞向量加權平均的在一些任務上甚至比復雜模型的效果好。
- Paragraph Vector模型足夠簡單,並且能夠編碼文檔級文本,但是對於sentence embedding,其效果相較於其他方法不具競爭力。
- Skip-Thought,FastSent和Quick-Thought都是基於句子連貫性設計任務:
- 基於encoder-decoder的Skip-Thought模型最復雜,在監督類型評測上比FastSent模型效果好,但在非監督類型評測上,FastSent要好於Skip-Thought。
- Quick-Thought作為一個最新的模型,其復雜度介於FastSent和Skip-Thought之間,但在大多數任務上的效果比其他兩個模型都好。
- 相較於Skip-Thought,FastSent和Quick-Thought,SDAE模型與利用n-grams的Sent2Vec模型的優點是只需要輸入單個句子。此外,Sent2Vec模型效果比SDAE模型好一些。
給讀到這裏的朋友點個贊,下一篇將介紹如何利用有監督學習來訓練sentence embedding,我的github倉庫https://github.com/llhthinker/NLP-Papers包含了近年來深度學習在NLP各領域應用的優秀論文、代碼資源以及論文筆記,歡迎大家star~
References
- Le and Mikolov - 2014 - Distributed representations of sentences and documents
- Li and Hovy - 2014 - A Model of Coherence Based on Distributed Sentence Representation
- Kiros et al. - 2015 - Skip-Thought Vectors
- Hill et al. - 2016 - Learning Distributed Representations of Sentences from Unlabelled Data
- Arora et al. - 2016 - A simple but tough-to-beat baseline for sentence embeddings
- Pagliardini et al. - 2017 - Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features
- Logeswaran et al. - 2018 - An efficient framework for learning sentence representations
將句子表示為向量(上):無監督句子表示學習(sentence embedding)