
c++虛擬函式的實現以及在類中的記憶體分佈
阿新 • • 發佈:2019-01-30
c++為了相容c保留了struct型別,但是c++中的struct和c有明顯的區別,c++中的struct可以繼承,可以有成員函式,但是在c中卻不行,在c++中struc和class更相似(還是有一些區別的,這裡不再敘述),c中struct的記憶體分佈很簡單,那麼c++中的class(struct)是怎麼樣的呢?
首先沒有虛擬函式的類其記憶體佈局和c的struct沒有什麼根本的區別,其例項效率和c是一樣的。當有虛擬函式時物件會有一個特殊的指標指向虛擬函式表(vpt),在最初的cfront(c++的第一個編譯器)實現中,虛擬函式表指標(vpt)儲存在物件的底部。這保持了與C結構佈局的相容性。但是,在C++中加入了多重繼承和虛基類後,許多實現開始將vptr置於物件的頂部。在多重繼承環境中,如果可以通過指向成員的指標呼叫虛擬函式,使用這個方案更加效率。但是,它破壞了C++物件與c結構的互操作性。目前,許多實現都將vptr置於物件的頂部。
②在D3類物件內部,B::g()未被覆蓋。因此,D3內g0的虛擬函式表入口是B::g()的地址。由於B和D3的地址相同,所以不需要調整this指標。所以,儲存的偏移量是0
③與②相同,因為在D3中並未覆蓋B::h()。
④用指向D3類物件的D1型別的指標呼叫f()時,被呼叫的函式仍然是D3::f(),因為D3覆蓋了B::f()。需要注意的是,D1型別的指標指向的是D3內部的D1類物件(參見上面的pd1),然而,在進入D3::f()中時,this指標必須指向D3的開始位置,而不是D1的開始位置。D1類物件的地址是D3類物件的地址與D3類物件開始位置到D1類物件開始位置的偏移量的代數和。這個偏移量就是 offset_D1,也就是到D3類物件內部D1部分開始位置的偏移量。因此,為了獲得D3的開始位置,需要加上- offset D1。這就是儲存在(D3內部D1的)虛擬函式表中第二個位置的內容。 儲存在新虛擬函式表中的偏移量與物件的地址相加,該物件的地址被用來當作this指標。在這個例子中,必須從D3(或者B)內部D1的地址中減去 offset_D1,才能獲得D3物件的地址。所以,要將- offset D1置於虛擬函式表中。這樣修改後,“pd1->f():”應該是:(*(pdl->vptr[1]. function)((D1*)((char*) pd1 + pd1->vptr[1]. offset)))
這裡,(pd1->vptr[1]. function)給出了虛擬函式表中函式的地址,而剩下的部分是操控地址,以獲得物件的開始位置。在這個例子中,偏移量是負值。 這種方案增加了虛擬函式表的大小,而且,每次呼叫虛擬函式都要通過偏移量計算機制計算偏移量,即使地址是正確的(即,表格中儲存的偏移量是0)也是如此。這浪費了記憶體(和CPU時間)。在多數情況下,並不需要調整偏移量。但是,虛擬函式表的每個位置仍然要儲存偏移量。如果能避免這種浪費,再好不過了。 有些編譯器使用另一種方案,即 thunk模型來解決這些問題。這裡使用帶函式地址的舊虛擬函式表(每個函式只有一個儲存位置),不會增加虛擬函式表的大小。如果不需要調整this指標,儲存在虛擬函式表中的地址就是指向被執行函式的指標(像以前一樣)。如果需
要調整this指標的偏移量,儲存在虛擬函式中的地址則指向某段進行調整的程式碼( thunk),並呼叫合適的函式。現在,執行實際函式分成兩個步驟。該方案的優點是,只有那些需要調整this指標偏移量的虛擬函式呼叫,才會有額外的開銷,同時還能保持較小的虛擬函式表大
小。這兩種方案,在計算偏移量方面的開銷相同。在執行pd1->f()時,編譯器像對待任何虛擬函式那樣進行常規地操作:它在虛擬函式表中找到該函式,然後呼叫,然而這不是最終的結果,這個函式只是對this指標做出了調整,通過調整this指標的位置進而呼叫到實際的函式。如下圖: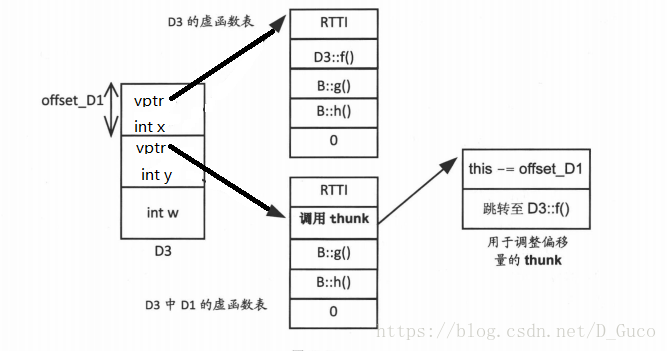 從以上的例子可以發現,在多重繼承層次中:
從以上的例子可以發現,在多重繼承層次中:
(a)訪問非虛成員函式和資料成員非常簡單,不會導致任何額外的執行時開銷
(b)但是,根據編譯器的實現不同,在呼叫虛擬函式時,有些呼叫可能導致增加虛擬函式表大小的額外開銷,或者只有那些需要調整this指標的呼叫才會發生額外的執行開銷,但不會增加虛擬函式表的大小。
所有這些問題都不能作為反對多重繼承的論據。的確,這些問題涉及開銷,但是,多重繼承減少了編碼的負擔,同時也讓問題的解決方案更加簡潔,這當然要付出一些代價. 總之,與n個基類的多重繼承層次相關的額外虛擬函式表有n-1個。派生類和最左邊的非虛基類共享同一個虛擬函式表。因此,帶有2個基類的多重繼承層次,有1個(2-1=1)基類的虛擬函式表和1個派生類的虛擬函式表(最左邊的基類與派生類共享該虛擬函式表),總共有2個虛擬函式表。注意 虛擬函式不僅會改變物件的記憶體佈局,對編譯器是否生成一些我們平時認為會生成的預設建構函式也會有影響: 對於某些不帶虛擬函式的類,如果在類中未宣告預設建構函式,實際上就根本不必生成預設建構函式。因為,即使該類有資料成員,在這個建構函式內部也不需要進行任何工作。大多數編譯器不會生成這樣的建構函式。使用者總是相信生成了一個預設建構函式,但實際上沒有。還有編譯器是否應該生成預設複製建構函式並呼叫它?並非如此,因為如果類表現了逐位複製( bitwise copy)語義。我們只需要將Obj1中的位複製到Obj2中。不必為此呼叫複製建構函式,因此,編譯器也不必合成一個複製建構函式,因為兩者結構沒有區別(只是位的集合)。對於大多數處理器,這可以通過一個單獨的記憶體移動指令完成
一般而言,逐位複製語義在下面這些情況時不適用:
(a)類包含內嵌物件(即,將另一個類的物件作為資料成員),這些內嵌物件中包含複製建構函式(編譯器生成或程式設計師定義)。
(b)類從一個或多個包含複製建構函式(程式設計師定義或者編譯器生成)的基類派生。
(c)類聲明瞭虛擬函式。
(d)當類從虛基類繼承時(與虛基類是否存在複製建構函式無關)。 還有一種情況更為複雜,就是虛基類和帶有虛擬函式的虛基類,留在後面說吧。
首先沒有虛擬函式的類其記憶體佈局和c的struct沒有什麼根本的區別,其例項效率和c是一樣的。當有虛擬函式時物件會有一個特殊的指標指向虛擬函式表(vpt),在最初的cfront(c++的第一個編譯器)實現中,虛擬函式表指標(vpt)儲存在物件的底部。這保持了與C結構佈局的相容性。但是,在C++中加入了多重繼承和虛基類後,許多實現開始將vptr置於物件的頂部。在多重繼承環境中,如果可以通過指向成員的指標呼叫虛擬函式,使用這個方案更加效率。但是,它破壞了C++物件與c結構的互操作性。目前,許多實現都將vptr置於物件的頂部。
class B{ class D1: public B{
public: public:
virtual void f() virtual void g();
virtual void g();
virtual void h() private:
private: int y;
int i; }
}
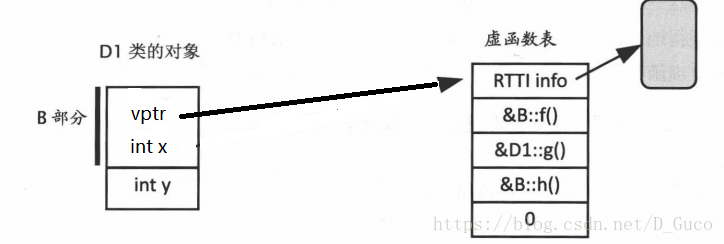
這裡的RTTI時c++的執行時型別識別資訊,我們知道只有帶有虛擬函式的類才會生成虛擬函式表,因此動態型別強制轉換隻用於多型型別,在進行動態型別轉換時只要取虛擬函式表中的第0個元素得到type_info類物件判斷其真正的型別在進行操作.
接下來看一個複雜的:
class B{
public:
virtual void f()
virtual void g()
virtual void h()
private:
int x;
}
cass D1{
public:
void ff();
virtual void f()
private: 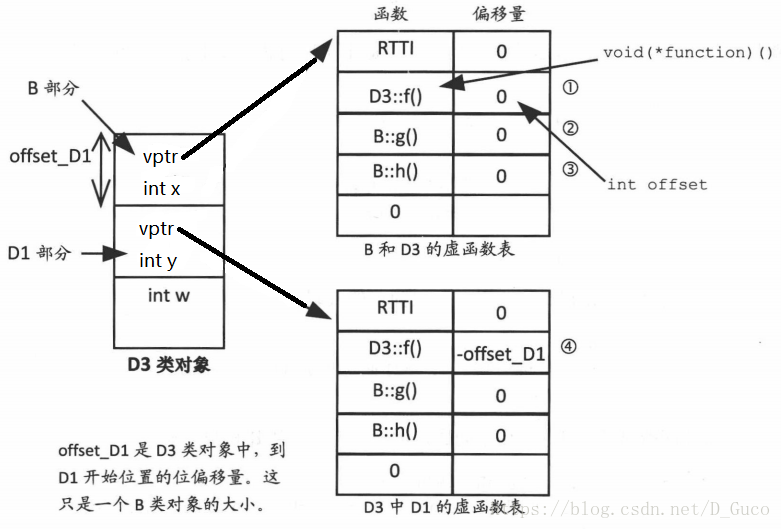
考慮下面的例子:
B* pb= new B
pb->X=0;
D3* pd3= new D3
pd3->ff();//ff在D1中這是一個有效呼叫。但是,這裡有一個問題。成員函式D1:ff()需要的引數是指向Dl的(this)指標,而不是指向D3的指標。D3類物件的地址與B類物件的地址相同一它們開始於相同的地址。但是,D3內的D1地址是D3(或者B)的地址加上D3到D1的偏移量。成員函式D1:ff()應該接收正確的this指標(指向D1物件的指標)。在編譯時,已知D3內部Dl1的偏移量,所以可以在編譯時很方便地處理這個問題,不會引入任何執行時開銷。我們將D3內部D1的偏移量稱為 offset D1。
因此,pd3->ff()變為:((DI*)(((char*)pd3)+ offset D1 ))->ff();編譯器只需將 offset D1加入到pd3中的地址上,然後將其強制轉換為D1·。但是,在將 offset DI1與pd3相加之前,必須將pd3當作char指標,而不是D3指標,以確保正確進行指標運算。因此,pd3被強制轉換為char*,然後加上偏移量,最後,將所得地址轉換為D1*並呼叫ff(),這些都在編譯時完成,沒有執行時開銷。
繼續看:
D3* pd3 = new D3;
D1* pd1 = new D3;//pd1必須指向D3中的D1部分
B* pb = new D3;
//3個指標都指向D3物件,這沒問題,因為D3同時從B和D1派生。
pd3->f();//由於動態繫結,呼叫D3::f()
pd1->f();//還是呼叫D3::f(),但是pd1指向D3類物件中D1部分的開始位置。
pb->f();//D3::f()struct vtb1_entry{
void (*function)();
int offset;
}②在D3類物件內部,B::g()未被覆蓋。因此,D3內g0的虛擬函式表入口是B::g()的地址。由於B和D3的地址相同,所以不需要調整this指標。所以,儲存的偏移量是0
③與②相同,因為在D3中並未覆蓋B::h()。
④用指向D3類物件的D1型別的指標呼叫f()時,被呼叫的函式仍然是D3::f(),因為D3覆蓋了B::f()。需要注意的是,D1型別的指標指向的是D3內部的D1類物件(參見上面的pd1),然而,在進入D3::f()中時,this指標必須指向D3的開始位置,而不是D1的開始位置。D1類物件的地址是D3類物件的地址與D3類物件開始位置到D1類物件開始位置的偏移量的代數和。這個偏移量就是 offset_D1,也就是到D3類物件內部D1部分開始位置的偏移量。因此,為了獲得D3的開始位置,需要加上- offset D1。這就是儲存在(D3內部D1的)虛擬函式表中第二個位置的內容。 儲存在新虛擬函式表中的偏移量與物件的地址相加,該物件的地址被用來當作this指標。在這個例子中,必須從D3(或者B)內部D1的地址中減去 offset_D1,才能獲得D3物件的地址。所以,要將- offset D1置於虛擬函式表中。這樣修改後,“pd1->f():”應該是:(*(pdl->vptr[1]. function)((D1*)((char*) pd1 + pd1->vptr[1]. offset)))
這裡,(pd1->vptr[1]. function)給出了虛擬函式表中函式的地址,而剩下的部分是操控地址,以獲得物件的開始位置。在這個例子中,偏移量是負值。 這種方案增加了虛擬函式表的大小,而且,每次呼叫虛擬函式都要通過偏移量計算機制計算偏移量,即使地址是正確的(即,表格中儲存的偏移量是0)也是如此。這浪費了記憶體(和CPU時間)。在多數情況下,並不需要調整偏移量。但是,虛擬函式表的每個位置仍然要儲存偏移量。如果能避免這種浪費,再好不過了。 有些編譯器使用另一種方案,即 thunk模型來解決這些問題。這裡使用帶函式地址的舊虛擬函式表(每個函式只有一個儲存位置),不會增加虛擬函式表的大小。如果不需要調整this指標,儲存在虛擬函式表中的地址就是指向被執行函式的指標(像以前一樣)。如果需
要調整this指標的偏移量,儲存在虛擬函式中的地址則指向某段進行調整的程式碼( thunk),並呼叫合適的函式。現在,執行實際函式分成兩個步驟。該方案的優點是,只有那些需要調整this指標偏移量的虛擬函式呼叫,才會有額外的開銷,同時還能保持較小的虛擬函式表大
小。這兩種方案,在計算偏移量方面的開銷相同。在執行pd1->f()時,編譯器像對待任何虛擬函式那樣進行常規地操作:它在虛擬函式表中找到該函式,然後呼叫,然而這不是最終的結果,這個函式只是對this指標做出了調整,通過調整this指標的位置進而呼叫到實際的函式。如下圖:
從以上的例子可以發現,在多重繼承層次中:(a)訪問非虛成員函式和資料成員非常簡單,不會導致任何額外的執行時開銷
(b)但是,根據編譯器的實現不同,在呼叫虛擬函式時,有些呼叫可能導致增加虛擬函式表大小的額外開銷,或者只有那些需要調整this指標的呼叫才會發生額外的執行開銷,但不會增加虛擬函式表的大小。
所有這些問題都不能作為反對多重繼承的論據。的確,這些問題涉及開銷,但是,多重繼承減少了編碼的負擔,同時也讓問題的解決方案更加簡潔,這當然要付出一些代價. 總之,與n個基類的多重繼承層次相關的額外虛擬函式表有n-1個。派生類和最左邊的非虛基類共享同一個虛擬函式表。因此,帶有2個基類的多重繼承層次,有1個(2-1=1)基類的虛擬函式表和1個派生類的虛擬函式表(最左邊的基類與派生類共享該虛擬函式表),總共有2個虛擬函式表。注意 虛擬函式不僅會改變物件的記憶體佈局,對編譯器是否生成一些我們平時認為會生成的預設建構函式也會有影響: 對於某些不帶虛擬函式的類,如果在類中未宣告預設建構函式,實際上就根本不必生成預設建構函式。因為,即使該類有資料成員,在這個建構函式內部也不需要進行任何工作。大多數編譯器不會生成這樣的建構函式。使用者總是相信生成了一個預設建構函式,但實際上沒有。還有編譯器是否應該生成預設複製建構函式並呼叫它?並非如此,因為如果類表現了逐位複製( bitwise copy)語義。我們只需要將Obj1中的位複製到Obj2中。不必為此呼叫複製建構函式,因此,編譯器也不必合成一個複製建構函式,因為兩者結構沒有區別(只是位的集合)。對於大多數處理器,這可以通過一個單獨的記憶體移動指令完成
一般而言,逐位複製語義在下面這些情況時不適用:
(a)類包含內嵌物件(即,將另一個類的物件作為資料成員),這些內嵌物件中包含複製建構函式(編譯器生成或程式設計師定義)。
(b)類從一個或多個包含複製建構函式(程式設計師定義或者編譯器生成)的基類派生。
(c)類聲明瞭虛擬函式。
(d)當類從虛基類繼承時(與虛基類是否存在複製建構函式無關)。 還有一種情況更為複雜,就是虛基類和帶有虛擬函式的虛基類,留在後面說吧。