
基於opencv的haar演算法以人臉識別為例的訓練分類器xml的方法
阿新 • • 發佈:2019-01-30
第一步 採集樣本
1、 將正負樣本分別放在兩個不同的資料夾下面
分別取名pos和neg,其中pos用來存放正樣本影象,neg用來存放負樣本
注意事項:1、正樣本要統一切成24*24畫素(或者其他)的格式,建議儲存成灰度圖,節省空間
2、正樣本的數目越多,訓練的時間也將越長,訓練出來的效果也就越好
3、負樣本的數量想對於正樣本一定要足夠的多,很多朋友在訓練的時候,往往出現了CPU佔用率達到了100%,但是訓練只是停留在一個分類器長達幾小時沒有相應,問題出現在取負樣本的那個函式 icvGetHaarTrainingDataFromBG中; 當剩下所有的negtive樣本在臨時的cascade Classifier中,evaluate的結果都是0(也就是拒絕了),隨機取樣本的數目到幾百萬都是找不到誤檢測的neg樣本了,因而沒法跳出迴圈
這裡我們假定根目錄在D:\boost下面 。
在cmd下面進入pos目錄,輸入 dir /b > pos.txt
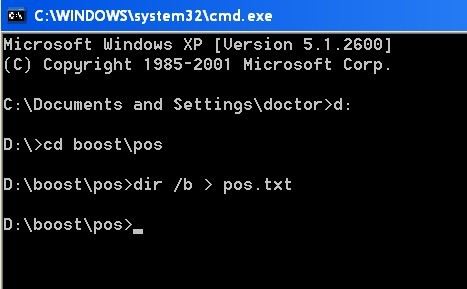
這個時候會在pos檔案加下面生成一個pos.txt檔案,開啟pos.txt

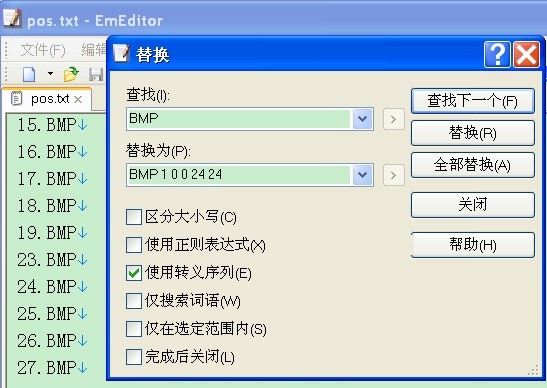
 我們對它進行如下編輯:
我們對它進行如下編輯:
(1)、將BMP 替換成為 BMP 1 0 0 24 24
注意:1代表此圖片出現的目標個數 後面的 0 0 24 24代表目標矩形框(0,0)到(24,24),使用者可以根據自身需要調整數值
(2)、刪除文字中最後一行的“pos.txt”
2、對負樣本進行編輯
注意:1、負樣本說明檔案不能含有目標物體
2、負樣本影象尺寸不受到限制,但是尺寸越大,訓練所用的時間越長,
3、負樣本影象可以是灰度圖,也可以不是,筆者建議使用灰度圖,這樣處理起來可能更有效率
4、負樣本影象一定不要重複,增大負樣本影象的差異性,可以增加分類器的使用範圍,筆者建議可以使用網上的素材庫,將1000多張不含目標的圖片灰度處理後用來訓練,效果更佳
二、使用opencv_createsamples.exe創立樣本VEC檔案
1、首先我們將要用的的2個程式opencv_createsamples.exe和opencv_haartraining.exe拷到根目錄下
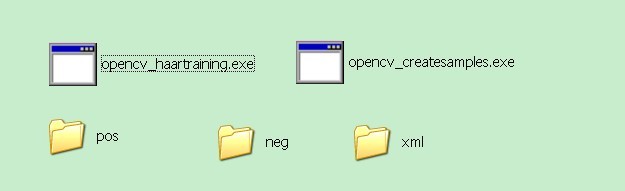
在CMD下輸入如下命令:
opencv_createsamples.exe -vec pos.vec -info pos\pos.txt -bg neg\neg.txt -w 40 -h 40 -num 142
以上引數的含義如下:
-vec <vec_file_name>
訓練好的正樣本的輸出檔名。
-img<image_file_name>
源目標圖片(例如:一個公司圖示)
-bg<background_file_name>
背景描述檔案。
-num<number_of_samples>
要產生的正樣本的數量,和正樣本圖片數目相同。
-bgcolor<background_color>
背景色(假定當前圖片為灰度圖)。背景色制定了透明色。對於壓縮圖片,顏色方差量由bgthresh
引數來指定。則在bgcolor-bgthresh 和bgcolor+bgthresh 中間的畫素被認為是透明的。
-bgthresh<background_color_threshold>
-inv
如果指定,顏色會反色
-randinv
如果指定,顏色會任意反色
-maxidev<max_intensity_deviation>
背景色最大的偏離度。
-maxangel<max_x_rotation_angle>
-maxangle<max_y_rotation_angle>,
-maxzangle<max_x_rotation_angle>
最大旋轉角度,以弧度為單位。
-show
如果指定,每個樣本會被顯示出來,按下"esc"會關閉這一開關,即不顯示樣本圖片,而建立過程
繼續。這是個有用的debug 選項。
-w<sample_width>
輸出樣本的寬度(以畫素為單位)
-h《sample_height》
輸出樣本的高度,以畫素為單位。
按下回車後我們的正樣本

三、使用opencv_haartraing.exe進行訓練
引數說明如下:
Haartraining 的命令列引數如下:
-data<dir_name>存放訓練好的分類器的路徑名。
-vec<vec_file_name>正樣本檔名(由trainingssamples 程式或者由其他的方法建立的)
-bg<background_file_name>背景描述檔案。
-npos<number_of_positive_samples>,
-nneg<number_of_negative_samples>用來訓練每一個分類器階段的正/負樣本。合理的值是:
-nPos = 7000;nNeg = 3000-nstages<number_of_stages>訓練的階段數。
-nsplits<number_of_splits>決定用於階段分類器的弱分類器。
如果1,則一個簡單的stump classifier 被使用。如果是2 或者更多,則帶有number_of_splits 個內部節點的CART 分類器被使用。
-mem<memory_in_MB>預先計算的以MB 為單位的可用記憶體。記憶體越大則訓練的速度越快。-sym(default)-nonsym指定訓練的目標物件是否垂直對稱。垂直對稱提高目標的訓練速度。例如,正面部是垂直對稱的。
-minhitrate《min_hit_rate》每個階段分類器需要的最小的命中率。總的命中率為min_hit_rate 的number_of_stages 次方。
-maxfalsealarm<max_false_alarm_rate>沒有階段分類器的最大錯誤報警率。總的錯誤警告率為max_false_alarm_rate 的number_of_stages 次方。
-weighttrimming<weight_trimming>指定是否使用權修正和使用多大的權修正。一個基本的選擇是0.9-eqw
-mode<basic(default)|core|all>選擇用來訓練的haar 特徵集的種類。basic 僅僅使用垂直特徵。all 使用垂直和45 度角旋轉特徵。-w《sample_width》-h《sample_height》訓練樣本的尺寸,(以畫素為單位)。必須和訓練樣本建立的尺寸相同
在CMD下輸入opencv_haartraining.exe -data xml -vec pos.vec -bg neg\neg.txt -w 40 -h 40 -mem 800

然後開始訓練
訓練過程如圖,呵呵,要是成百上千的樣本的話,我們先去吃完泡麵休息一下吧

好了,休息回來,訓練完成提示資訊如下:

在根目錄下就會生成相應的XML檔案
1、 將正負樣本分別放在兩個不同的資料夾下面
分別取名pos和neg,其中pos用來存放正樣本影象,neg用來存放負樣本

注意事項:1、正樣本要統一切成24*24畫素(或者其他)的格式,建議儲存成灰度圖,節省空間
2、正樣本的數目越多,訓練的時間也將越長,訓練出來的效果也就越好
3、負樣本的數量想對於正樣本一定要足夠的多,很多朋友在訓練的時候,往往出現了CPU佔用率達到了100%,但是訓練只是停留在一個分類器長達幾小時沒有相應,問題出現在取負樣本的那個函式 icvGetHaarTrainingDataFromBG中; 當剩下所有的negtive樣本在臨時的cascade Classifier中,evaluate的結果都是0(也就是拒絕了),隨機取樣本的數目到幾百萬都是找不到誤檢測的neg樣本了,因而沒法跳出迴圈
這裡我們假定根目錄在D:\boost下面 。
在cmd下面進入pos目錄,輸入 dir /b > pos.txt
這個時候會在pos檔案加下面生成一個pos.txt檔案,開啟pos.txt
我們對它進行如下編輯:(1)、將BMP 替換成為 BMP 1 0 0 24 24
注意:1代表此圖片出現的目標個數 後面的 0 0 24 24代表目標矩形框(0,0)到(24,24),使用者可以根據自身需要調整數值
(2)、刪除文字中最後一行的“pos.txt”
2、對負樣本進行編輯
在CMD下輸入 dir /b > neg.txt

注意:1、負樣本說明檔案不能含有目標物體
2、負樣本影象尺寸不受到限制,但是尺寸越大,訓練所用的時間越長,
3、負樣本影象可以是灰度圖,也可以不是,筆者建議使用灰度圖,這樣處理起來可能更有效率
4、負樣本影象一定不要重複,增大負樣本影象的差異性,可以增加分類器的使用範圍,筆者建議可以使用網上的素材庫,將1000多張不含目標的圖片灰度處理後用來訓練,效果更佳
二、使用opencv_createsamples.exe創立樣本VEC檔案
1、首先我們將要用的的2個程式opencv_createsamples.exe和opencv_haartraining.exe拷到根目錄下
在CMD下輸入如下命令:
opencv_createsamples.exe -vec pos.vec -info pos\pos.txt -bg neg\neg.txt -w 40 -h 40 -num 142
以上引數的含義如下:
-vec <vec_file_name>
訓練好的正樣本的輸出檔名。
-img<image_file_name>
源目標圖片(例如:一個公司圖示)
-bg<background_file_name>
背景描述檔案。
-num<number_of_samples>
要產生的正樣本的數量,和正樣本圖片數目相同。
-bgcolor<background_color>
背景色(假定當前圖片為灰度圖)。背景色制定了透明色。對於壓縮圖片,顏色方差量由bgthresh
引數來指定。則在bgcolor-bgthresh 和bgcolor+bgthresh 中間的畫素被認為是透明的。
-bgthresh<background_color_threshold>
-inv
如果指定,顏色會反色
-randinv
如果指定,顏色會任意反色
-maxidev<max_intensity_deviation>
背景色最大的偏離度。
-maxangel<max_x_rotation_angle>
-maxangle<max_y_rotation_angle>,
-maxzangle<max_x_rotation_angle>
最大旋轉角度,以弧度為單位。
-show
如果指定,每個樣本會被顯示出來,按下"esc"會關閉這一開關,即不顯示樣本圖片,而建立過程
繼續。這是個有用的debug 選項。
-w<sample_width>
輸出樣本的寬度(以畫素為單位)
-h《sample_height》
輸出樣本的高度,以畫素為單位。
按下回車後我們的正樣本
三、使用opencv_haartraing.exe進行訓練
引數說明如下:
Haartraining 的命令列引數如下:
-data<dir_name>存放訓練好的分類器的路徑名。
-vec<vec_file_name>正樣本檔名(由trainingssamples 程式或者由其他的方法建立的)
-bg<background_file_name>背景描述檔案。
-npos<number_of_positive_samples>,
-nneg<number_of_negative_samples>用來訓練每一個分類器階段的正/負樣本。合理的值是:
-nPos = 7000;nNeg = 3000-nstages<number_of_stages>訓練的階段數。
-nsplits<number_of_splits>決定用於階段分類器的弱分類器。
如果1,則一個簡單的stump classifier 被使用。如果是2 或者更多,則帶有number_of_splits 個內部節點的CART 分類器被使用。
-mem<memory_in_MB>預先計算的以MB 為單位的可用記憶體。記憶體越大則訓練的速度越快。-sym(default)-nonsym指定訓練的目標物件是否垂直對稱。垂直對稱提高目標的訓練速度。例如,正面部是垂直對稱的。
-minhitrate《min_hit_rate》每個階段分類器需要的最小的命中率。總的命中率為min_hit_rate 的number_of_stages 次方。
-maxfalsealarm<max_false_alarm_rate>沒有階段分類器的最大錯誤報警率。總的錯誤警告率為max_false_alarm_rate 的number_of_stages 次方。
-weighttrimming<weight_trimming>指定是否使用權修正和使用多大的權修正。一個基本的選擇是0.9-eqw
-mode<basic(default)|core|all>選擇用來訓練的haar 特徵集的種類。basic 僅僅使用垂直特徵。all 使用垂直和45 度角旋轉特徵。-w《sample_width》-h《sample_height》訓練樣本的尺寸,(以畫素為單位)。必須和訓練樣本建立的尺寸相同
在CMD下輸入opencv_haartraining.exe -data xml -vec pos.vec -bg neg\neg.txt -w 40 -h 40 -mem 800
然後開始訓練
訓練過程如圖,呵呵,要是成百上千的樣本的話,我們先去吃完泡麵休息一下吧
好了,休息回來,訓練完成提示資訊如下:
在根目錄下就會生成相應的XML檔案