
一次大資料量日誌儲存升級改造
商家操作日誌的使命就是記錄賣家對商品、訂單等業務的操作。以便於後續分析。我們在做技術選型的時候確定了kafka+storm+elasticsearch,當前的架構如下:
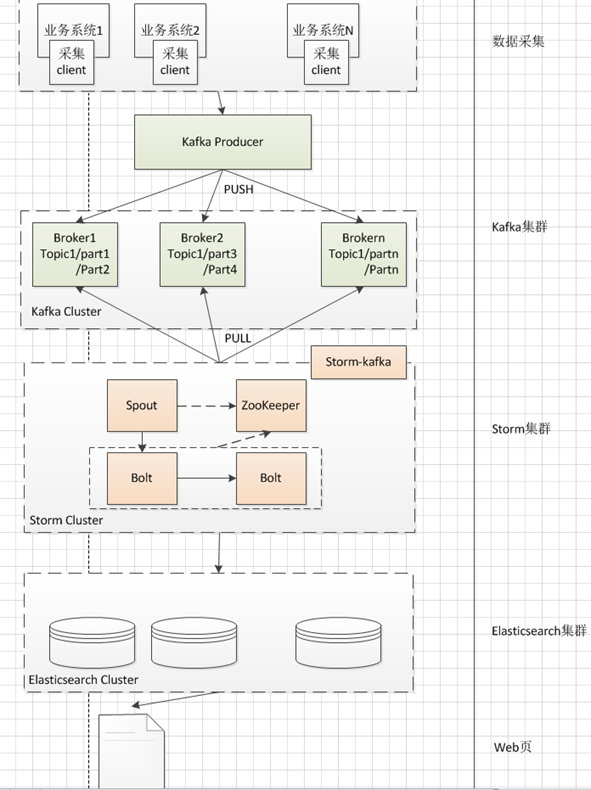
我們現在面臨這樣的問題,資料全部落到了ES上面,ES資料全部載入到記憶體裡面之後,當前2個月的數量達到數十T之多。這個量對資源的需求非常大,而且我們的要求是同時要開啟三個月的資料,因此遠遠達不到我們的要求。
![]()
我們以往是這樣做的,每天一個索引,2個月之前的索引全部關掉。只保持一個月的索引開啟。如果想查詢以前的資料,就要先關掉當前的1個月,再開啟要檢視的那個月的索引。

ES叢集,32個分片,32個副本(“1”-代表每個分片一個副本)
- "settings": {
- "index": {
- "number_of_shards": "32",
- "creation_date": "1475193606337",
- "number_of_replicas": "1",
- "version": {
- "created": "1070699"
- },
- "uuid": "JdEgO48dTTCWMAmMZ3oCXg"
- }
- },
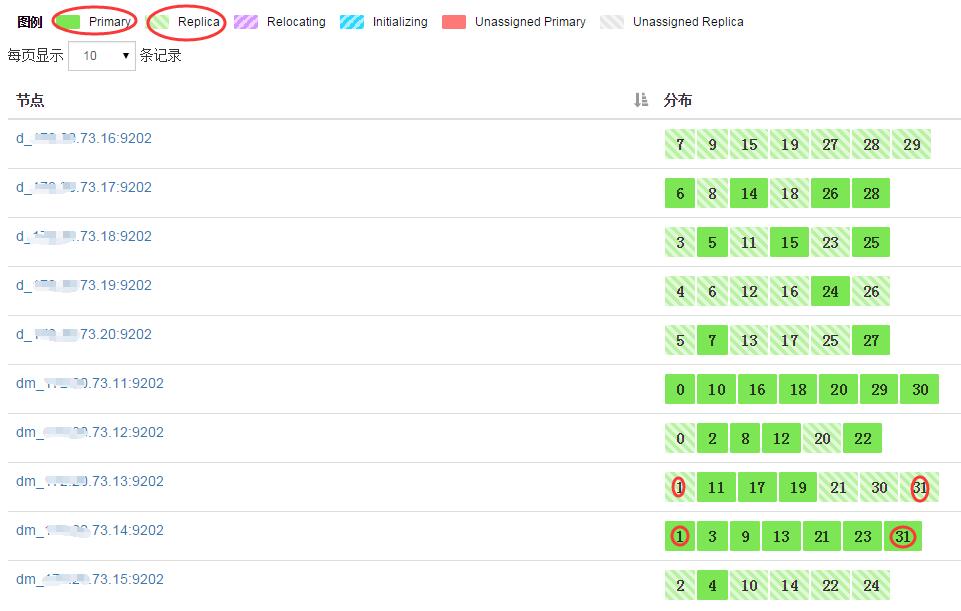
在這裡再說明下,叢集Index TPS,Search TPS與副本數的關係
叢集寫入文件TPS與副本數正相關,查詢TPS與副本數無關。
舉例:
1分鐘向叢集寫入1000個文件:
當索引有0個副本:叢集寫入文件次數為1000,Index TPS為1000/60.
當索引有1個副本:叢集寫入文件次數為2000,Index TPS為2000/60.
當索引有2個副本:叢集寫入文件次數為3000,Index TPS為3000/60.
1分鐘查詢1000次:
當索引有0個副本:search TPS為 1000/60.
當索引有1個副本:search TPS為 1000/60.
當索引有2個副本:search TPS為 1000/60.
我們必須要調整我們的架構及儲存方式。ES只用於熱資料的分析,利用ES的檢索特性。3個月以前的資料全部放入HBASE,利用HBASE的這種儲存,對歷史資料查詢,只從HBASE裡面查。更新後的儲存處理方案下面這樣
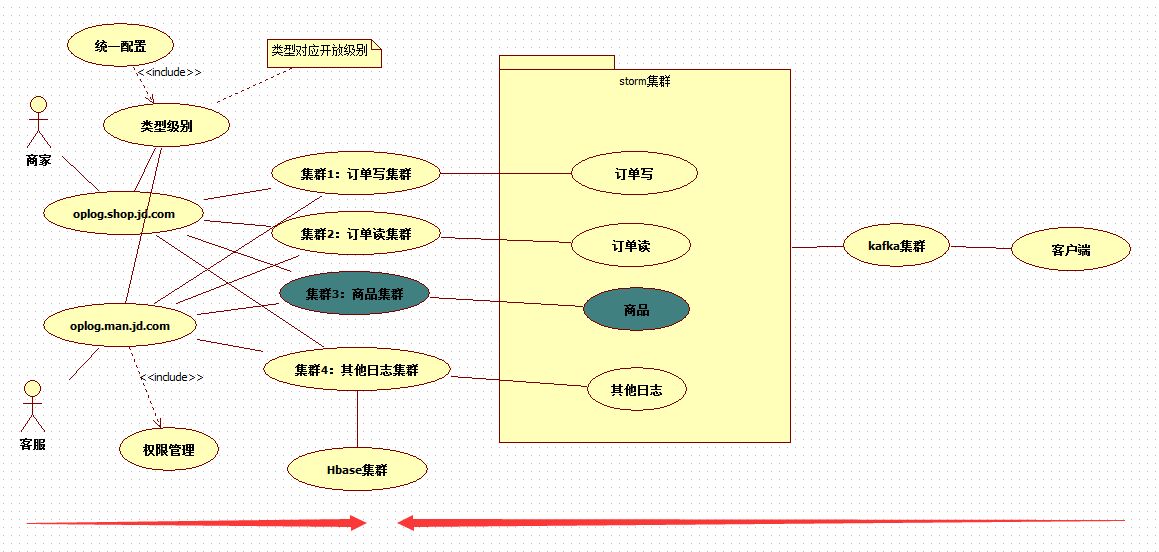
將日誌分叢集儲存,日誌量大的與日誌量小的,互不影響。將來申請資源單獨針對相應的日誌叢集來申請。這次調整從業務類別來拆分,繼續保留了原來的kafka+storm+elasticsearch技術方案,因為日誌處理在這個技術選型下是沒有任何問題的,我們所要調整的是落地的細節上的問題。比如我們這次的儲存方案調整。