
新版火狐瀏覽器如何使用Xpath語法解析網頁元素。
最近在學習Xpath語法,想使用火狐瀏覽器試試有沒有專門的工具,搜了一下,發現網上都是什麼FireBug和FireXpath什麼的。但是新版火狐瀏覽器(58版)之後都不支援這些工具了,於是只好自己找了。
找了一下就發現了這個,Try XPath—–新版火狐瀏覽器的外掛。安裝方式很簡單:
在火狐瀏覽器右上角開啟選單,選擇“附加元件”,然後在搜尋欄搜尋xpath。
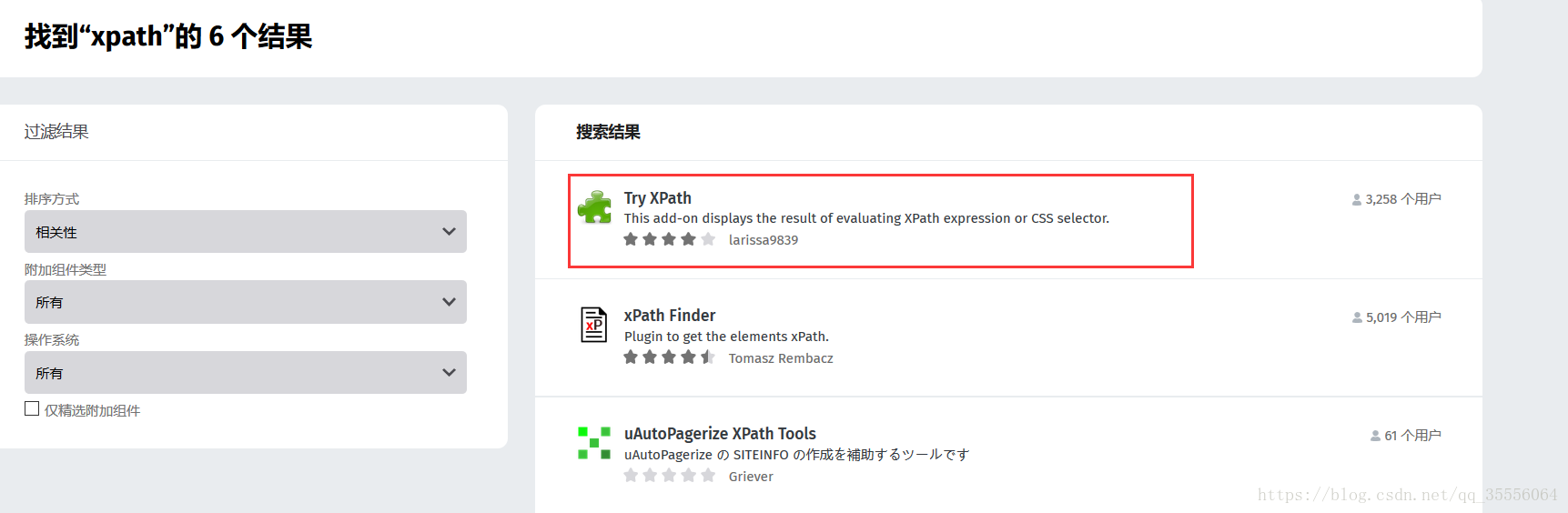
點進去之後,選擇Add to Firefox:
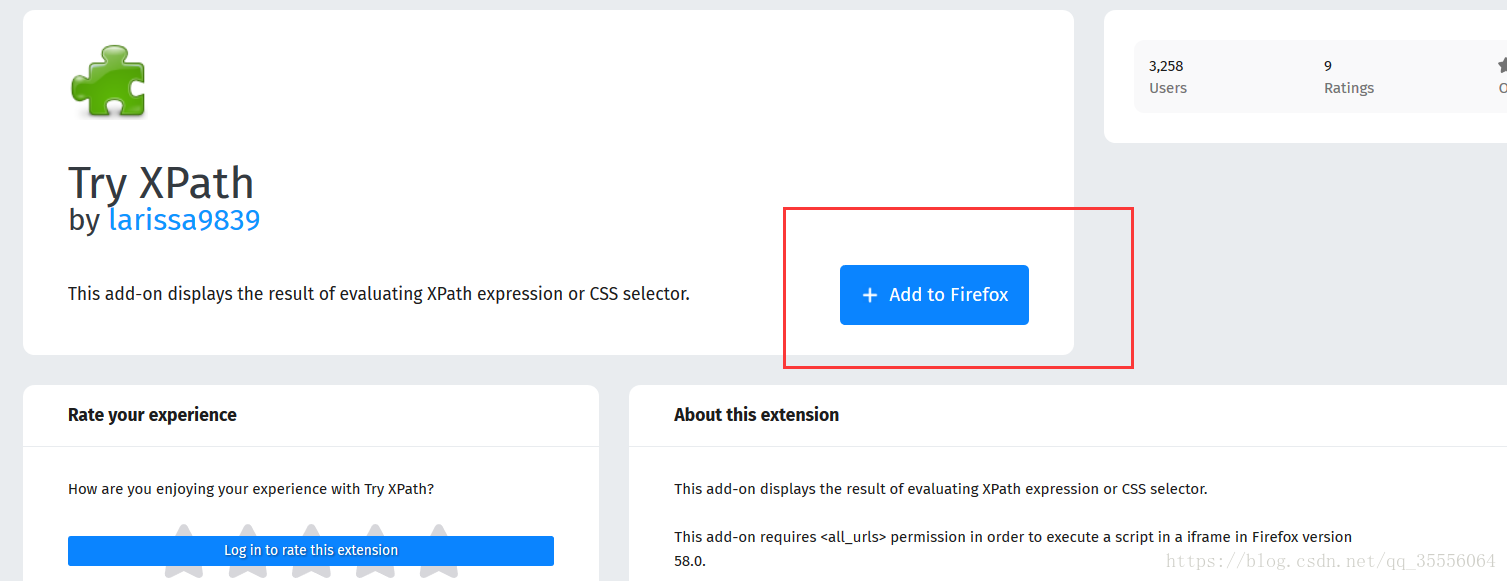
確定什麼許可權,然後在你的火狐瀏覽器的左上角出現這個標誌就安裝成功了。
使用方式也很簡單。開啟你的網頁,點選上面的那個圖示:
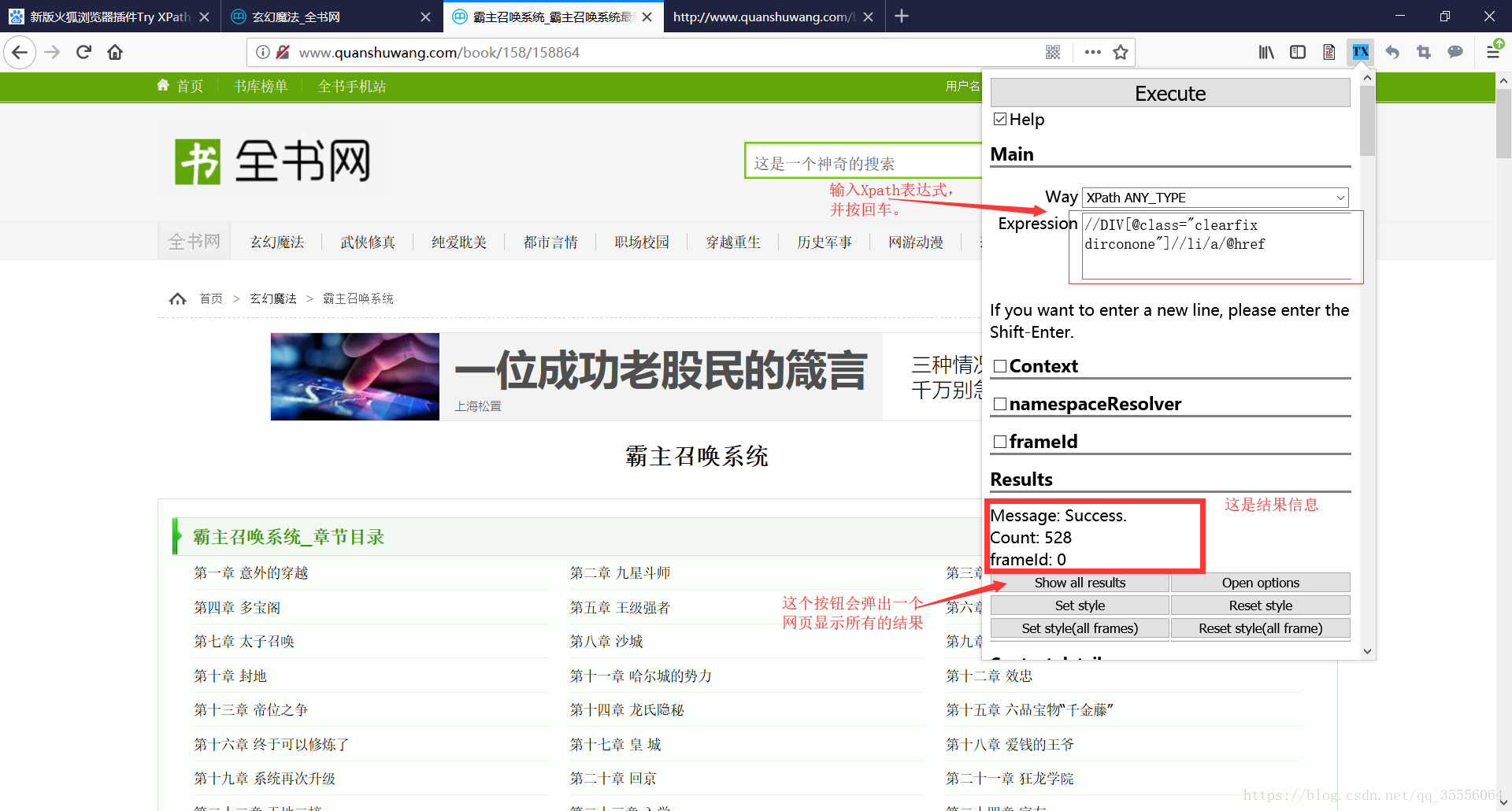
你也可以下滑顯示部分結果,有些結果也會在網頁中用紅色框框顯示。
顯示全部結果就像這樣:
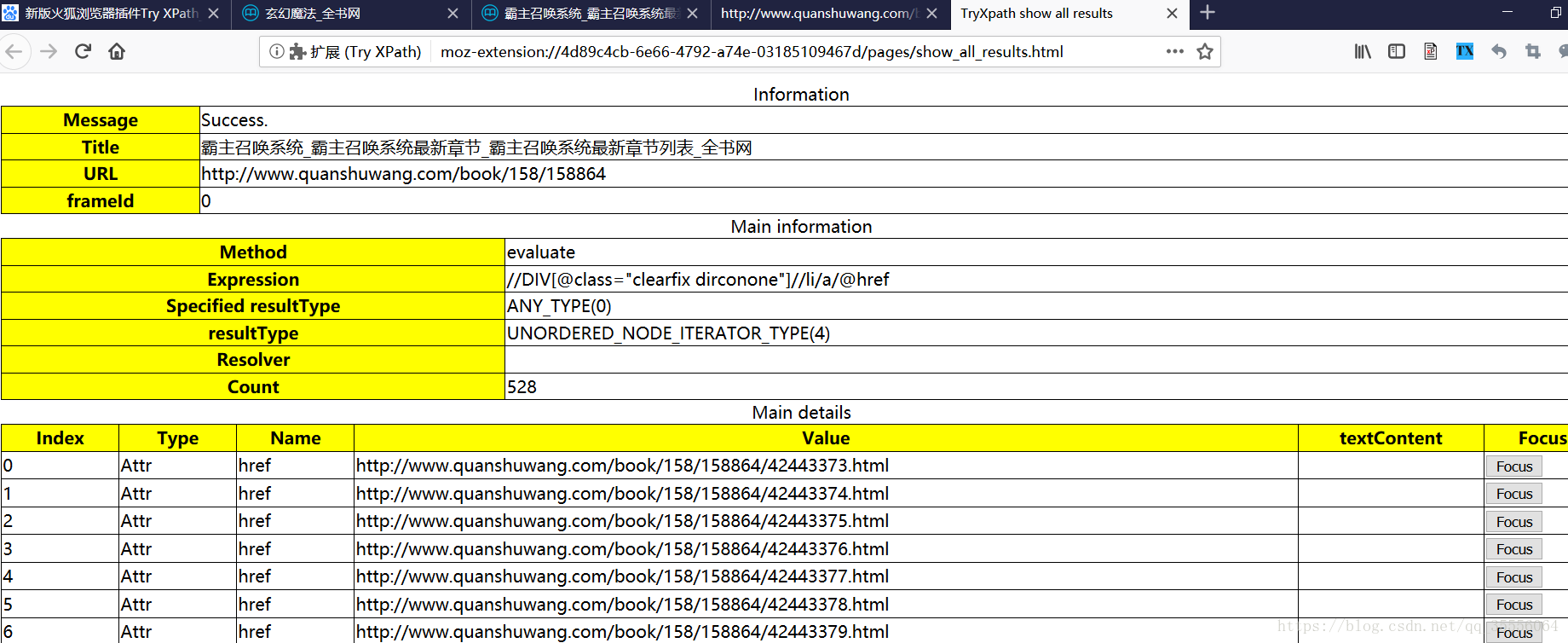
到此,基本功能就結束了。大家可以對照網頁原始碼試著寫xpath,看看是不是對的。
相關推薦
新版火狐瀏覽器如何使用Xpath語法解析網頁元素。
最近在學習Xpath語法,想使用火狐瀏覽器試試有沒有專門的工具,搜了一下,發現網上都是什麼FireBug和FireXpath什麼的。但是新版火狐瀏覽器(58版)之後都不支援這些工具了,於是只好自己找了。 找了一下就發現了這個,Try XPath—–新版火狐瀏覽
新版火狐瀏覽器(61.0.2 (64 位))如何進行元素定位
com 恢復 分享 http bubuko 一個 src 開始 選擇 ---恢復內容開始--- 我們在寫自動化腳本進行web測試時,經常會用到元素定位,之前我們用的都是Firebug+Firepath,但瀏覽器總要更新的,所以就有了這篇筆記,新版的火狐瀏覽器整合掉了這兩個小
Ubuntu下安裝最新版火狐瀏覽器並設定成中文
解除安裝: sudo apt-get remove firefox 安裝: sudo apt-get install firefox 設定成中文; sudo apt-get install firefox-locale-zh-hans 然後再開啟瀏覽器看是否設定成中文
讓網頁在ie瀏覽器下以最高版本解析網頁
com class mpat ble 標準模式 -1 高版本 content 解析 <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"> <meta http-equiv="X-UA-
定位網頁元素的解析
css 提高 都是 如果 默認 dex 屬性 ive 20px 一.position屬性定位網頁元素 1.static :默認值,沒有定位。按照標準文檔流的方式提現出來 2.relative:相對定位,相對於自身元素原來的位置進行定位 <style type="
第9課、解析網頁中的元素-四周學會爬蟲系統
ini bsp tip 好的 python3 pycharm har tle erp 目標:爬取本地網頁中,評分大於3的文章,並打印出來 準備: 安裝Python3.0。 安裝PyCharm,用於開發Python的集成環境。 安裝BeautifulSoup庫,學習爬蟲
火狐瀏覽器被惡意篡改,劫持(開啟同時跳出主頁和2345網頁)
煩 居然被劫持了,我有一丟丟小強迫症,無法忍受同時跳出兩個頁面,還是特別醜的頁面。。。歐歐歐 醜吧 這才是寶貝 方法如下 直接上乾貨: 開啟快捷方式的圖示屬性,你會發現 在目標一欄的後邊除了路徑還會多出來一個網址,且無法修改,要求管理員許可權 百度了很多,終於解決 先把目標一欄後
python在lxml中使用XPath語法進行#資料解析
在lxml中使用XPath語法: 獲取所有li標籤: from lxml import etree html = etree.parse('hello.html') print type(html) # 顯示etree.parse() 返回型別 result = html.xpath('//li')
火狐瀏覽器安裝firebug和xpath
火狐瀏覽器安裝firebug和XPath時踩坑,百度後查閱很多前輩的經驗,最終解決問題,藉此分享下解決方法: 1.下載firebug外掛 連結:https://pan.baidu.com/s/1AZtqVBZZLEOCjOlZP-znpQ提取碼:igkd Firebug的外掛版本對應
使用Xpath定位元素(和元素定位相關的Xpath語法)
本文主要講述Xpath語法中,和元素定位相關的語法第一種方法:通過絕對路徑做定位(相信大家不會使用這種方式) By.xpath("html/body/div/form/input")第二種方法:通過相對
讓火狐瀏覽器可以訪問含有activex控制元件網頁的三種方式
http://www.cnblogs.com/zhwl/archive/2012/11/22/2782968.html 一:安裝一個擴充套件MediaWrap 0.1.7.3 mediawrap 是一個很小的 Firefox 擴充套件。它能夠將 Activ
python 爬蟲(xpath解析網頁,下載照片)
XPath (XML Path Language) 是一門在 XML 文件中查詢資訊的語言,可用來在 XML 文件中對元素和屬性進行遍歷。 lxml 是 一個HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 資料。lxml和正則一樣,也是用 C
谷歌瀏覽器和火狐瀏覽器插件安裝方法,分別以”谷歌訪問助手”和”網頁截圖”為例
顯示 microsoft 打開 bold image 過程 測試 ott 拓展 本文內容 問題陳述 1. 谷歌瀏覽器安裝插件步驟 1.1 基本準備 1.2 安裝插件步驟圖文展示 1.3 安裝後測試使用效果 2. 火狐瀏覽器安裝插件步驟 2.1 基本準備 2.2 安裝插件步驟
Selenium自動化測試之Xpath網頁元素定位
XPath 是一門在 XML 文件中查詢資訊的語言。XPath 可用來在 XML 文件中對元素和屬性進行遍歷。XPath雖然是被設計用來搜尋XML文件的,不過它也能很好的在HTML文件中工作,並且大部分瀏覽器也支援通過XPath來查詢節點。 xpath的作用就
FillForm網頁表單填寫外掛(用於火狐瀏覽器,自動填表,自動錶單,填寫表單)
FillForm網頁文字框填寫擴充套件,在您需要的時候填寫資料。可以填寫非表單內容。目前僅處理Input、textarea、select標籤。 擴充套件安裝後可以通過選單“工具” - “FillForm”開始使用,Save是儲存,Fill是填寫(當然也可以通過快捷鍵快速操作
Python爬蟲實戰--(二)解析網頁中的元素
使用requests傳送請求 首先匯入requests庫和beautifulsoup庫 import requests from bs4 import BeautifulSoup 呼叫requests.get()方法獲得指定url的res
網頁元素節點選取之xpath測試——python lxml的etree方法
最近在用scrapy爬取資料,每次寫一堆xpath語法,然後執行爬蟲時由於xpath語法錯誤、或者邏輯錯誤亦或者節點不精準多做很多工作,於是想查檢視有沒有簡易的xpath節點測試工具或方法:網上有xpath線上測試小工具,但這種線上測試網頁在測試網頁文字較大時測試匹配不出來,
電腦經驗 火狐瀏覽器檢視3D網頁結構
慈心積善融學習,技術願為有情學。善心速造多好事,前人栽樹後乘涼。我今於此寫經驗,願見文者得啟發。1、右上角 點選後,找到附加元件2、搜尋 tilt,安裝,然後它提示你重啟瀏覽器3、重啟好後
selenium2在啟動火狐瀏覽器時一直打不開網頁提示火狐連線被重置怎麼辦或者一直在轉載入不了網頁
System.setProperty("webdriver.firefox.bin", "D:/Users/DUANYAPING740/AppData/Local/Mozilla Firefox/firefox.exe");ProfilesIni profilesini=new ProfilesIni();
網頁結構的簡介和Xpath語法的入門教程
則表達式 scrapy ebp 結構 view 根據 廣泛 wechat db2 相信很多小夥伴已經聽說過Xpath,之前小編也寫過一篇關於Xpath的文章,感興趣的小夥伴可以戳這篇文章如何利用Xpath抓取京東網商品信息以及Python網絡爬蟲四大選擇器(正則表達式、BS