
大資料技術之Hive實戰——Youtube專案(一)
一、需求描述
統計 Youtube 視訊網站的常規指標,各種 TopN 指標:
–統計視訊觀看數 Top10
–統計視訊類別熱度 Top10
–統計視訊觀看數 Top20 所屬類別包含這 Top20 視訊的個數
–統計視訊觀看數 Top50 所關聯視訊的所屬類別 Rank
–統計每個類別中的視訊熱度 Top10
–統計每個類別中視訊流量 Top10
–統計上傳視訊最多的使用者 Top10 以及他們上傳的視訊
–統計每個類別視訊觀看數 Top10
二、知識儲備梳理
2.1、order by,sort by,distribute by,cluster by
背景表結構
在講解中我們需要貫串一個 例子,所以需要設計一個情景,對應 還要有一個表結構和填充
資料。如下:有 3 個欄位,分別為 personId 標識某一個人,company 標識一家公司名稱,
money 標識該公司每年盈利收入(單位:萬元人民幣)

建表匯入資料:
create table company_info(
personId string,
company string,
money float
)row format delimited fields terminated by "\t"
load data local inpath “company_info.txt” into table company_info;
2.1.1、order by
hive 中的 order by 語句會對查詢結果做一次全域性排序,即,所有的 mapper 產生的結果都會
交給一個 reducer 去處理,無論資料量大小,job 任務只會啟動一個 reducer,如果資料量巨
大,則會耗費大量的時間。
尖叫提示:如果在嚴格模式下,order by 需要指定 limit 資料條數,不然資料量巨大的情況下
會造成崩潰無輸出結果。涉及屬性:set hive.mapred.mode=nonstrict/strict
例如:按照 money 排序的例子
select * from company_info order by money desc;
2.1.2、sort by
hive 中的 sort by 語句會對每一塊區域性資料進行區域性排序,即,每一個 reducer 處理的資料都
是有序的,但是不能保證全域性有序。
2.1.3、distribute by
hive 中的 distribute by 一般要和 sort by 一起使用,即將某一塊資料歸給(distribute by)某一個
reducer 處理,然後在指定的 reducer 中進行 sort by 排序。
尖叫提示:distribute by 必須寫在 sort by 之前
尖叫提示:涉及屬性 mapreduce.job.reduces,hive.exec.reducers.bytes.per.reducer例如:不同的人(personId)分為不同的組,每組按照 money 排序。
select * from company_info distribute by personId sort by personId, money desc;
2.1.4、cluster by
hive 中的 cluster by 在 distribute by 和 sort by 排序欄位一致的情況下是等價的。同時,cluster
by 指定的列只能是降序,即預設的 descend,而不能是 ascend。
例如:寫一個等價於 distribute by 與 sort by 的例子
select * from company_info distribute by personId sort by personId;
等價於
select * from compnay_info cluster by personId;
2.2、行轉列、列轉行(UDAF 與 UDTF)
2.2.1、行轉列
表結構:
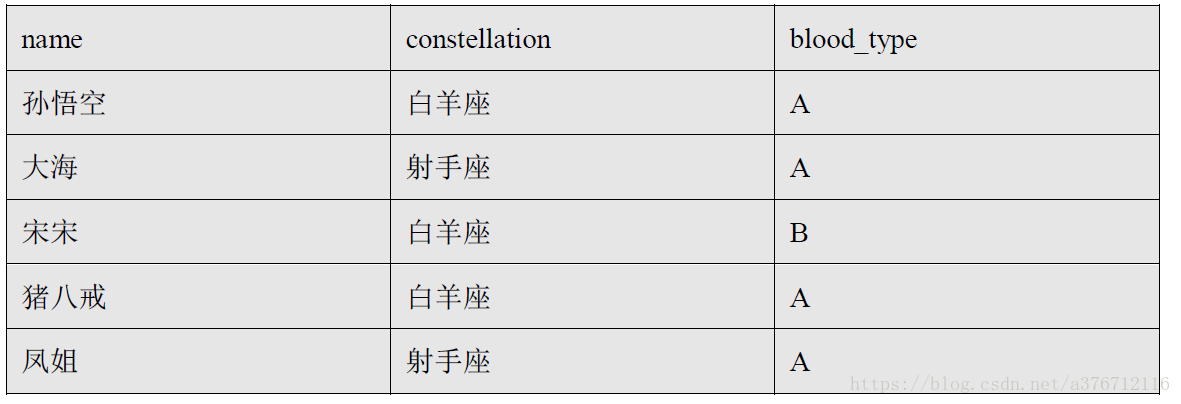
建立表及資料匯入:
create table person_info(
name string,
constellation string,
blood_type string)
row format delimited fields terminated by "\t";
load data local inpath “person_info.tsv” into table person_info;例如:把星座和血型一樣的人歸類到一起
select
t1.base,
concat_ws('|', collect_set(t1.name)) name
from
(select
name,
concat(constellation, ",", blood_type) base
from
person_info) t1
group by
t1.base;2.2.2、列轉行
表結構:
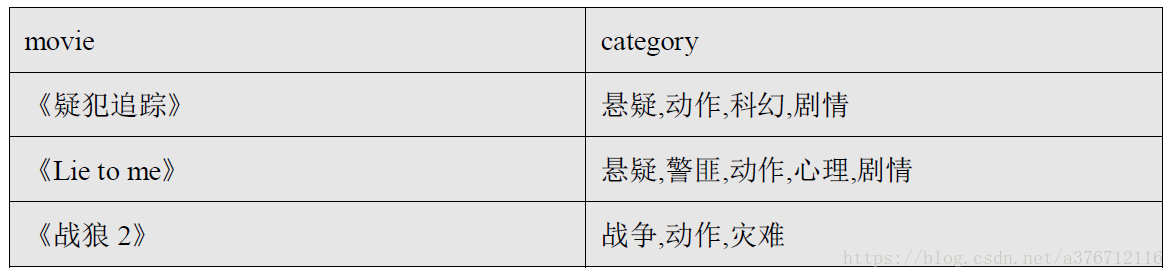
建立表及匯入資料:
create table movie_info(
movie string,
category array<string>)
row format delimited fields terminated by "\t"
collection items terminated by ",";
load data local inpath "movie_info.tsv" into table movie_info;例如:將電影分類中的陣列資料展開
select
movie,
category_name
from
movie_info lateral view explode(category) table_tmp as category_name;2.3、陣列操作
“fields terminated by”:欄位與欄位之間的分隔符。
“collection items terminated by”:一個欄位中各個子元素 item 的分隔符。
2.4、orc 儲存
orc 即 Optimized Row Columnar (ORC) file,在 RCFile 的基礎上演化而來,可以提供一種高
效的方法在 Hive 中儲存資料,提升了讀、寫、處理資料的效率。
2.5、Hive 分桶
Hive 可以將表或者表的分割槽進一步組織成桶,以達到:
1、資料取樣效率更高
2、資料處理效率更高
桶通過對指定列進行雜湊來實現,將一個列名下的資料切分為“一組桶”,每個桶都對應了
一個該列名下的一個儲存檔案。
2.5.1、直接分桶
開始操作之前,需要將 hive.enforce.bucketing 屬性設定為 true,以標識 Hive 可以識別桶。
create table music(
id int,
name string,
size float)
clustered by (id) sort by (id) into 4 buckets
row format delimited fields terminated by "\t";該程式碼的意思是將 music 表按照 id 將資料分成了 4 個桶,插入資料時,會對應 4 個 reduce
操作,輸出 4 個檔案。
2.5.2、在分割槽中分桶
當資料量過大,需要龐大分割槽數量時,可以考慮桶,因為分割槽數量太大的情況可能會導致文
件系統掛掉,而且桶比分割槽有更高的查詢效率。資料最終落在哪一個桶裡,取決於 clustered
by 的那個列的值的 hash 數與桶的個數求餘來決定。雖然有一定離散性,但不能保證每個桶
中的資料量是一樣的。
create table music2(
id int,
name string,
size float)
partitioned by (date string)
clustered by (id) sorted by(size) into 4 bucket
row format delimited
fields terminated by "\t";
load data local inpath 'demo/music.txt' into table music2 partition(date='2017-08-30');