
sqoop 將hive資料匯出mysql,map reduce卡住問題
直接上圖給初入坑的小夥伴看看問題的樣子
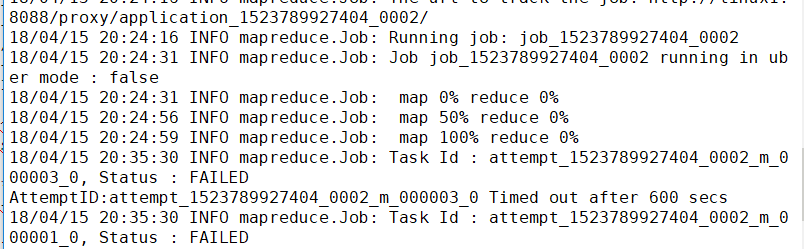
檢視日誌沒有報錯,各種百度......
最後對了一下mysql的表字段和hive的表字段才發現有一個欄位沒有對上。
最後留下一篇記錄提醒一下入門的小白。
當然,導致問題的原因有多種,只希望能提醒粗心的小白別忘記考慮到欄位的對應。
相關推薦
sqoop 將hive資料匯出mysql,map reduce卡住問題
直接上圖給初入坑的小夥伴看看問題的樣子檢視日誌沒有報錯,各種百度......最後對了一下mysql的表字段和hive的表字段才發現有一個欄位沒有對上。最後留下一篇記錄提醒一下入門的小白。當然,導致問題的原因有多種,只希望能提醒粗心的小白別忘記考慮到欄位的對應。
使用sqoop將hive資料匯入mysql例項
1.環境配置 CentOS6.5 hadoop2.2 jdk1.7.0 sqoop1.4.4 zookeeper3.4.5 Mysql 14.14 2.在mysql上建立表 先按照需求在
利用sqoop將hive資料匯入匯出資料到mysql
執行環境 centos 5.6 hadoop hive sqoop是讓hadoop技術支援的clouder公司開發的一個在關係資料庫和hdfs,hive之間資料匯入匯出的一個工具 在使用過程中可能遇到的問題: sqoop依賴zookeeper,所以必須配置ZOOK
sqoop將hive資料導進mysql報錯:Unsupported major.minor version 52.0
離線分析需要將hive的資料匯入到mysql做視覺化,導資料時報錯,檢視log:發現jdk版本原因,sqoop shell命令會用系統jdk編譯成jar包,然後用cdh的jdk跑map將資料導到mysql. 檢視jdk(jdk1.7為報錯
利用sqoop將hive資料匯入Oracle中(踩的坑)
教程很多,這裡只說踩過的坑 1.下載sqoop時,還得下一個bin的包,拿到sqoop-1.4.6.jar 的包,放到hadoop的lib目錄下 2.匯入oracle,執行程式碼時,使用者名稱和表名必須大寫!且資料庫建表時表名必須大寫! 示例程式碼: sqoop expo
利用sqoop將hive資料匯入Oracle中
首先: 如oracle則執行sqoop list-databases --connect jdbc:oracle:thin:@//192.168.27.235:1521/ORCL --username DATACENTER -P 來測試是否能正確連線資料庫 如mysql則執行sq
使用sqoop將HDFS資料匯出到RDBMS,map100%reduce0%問題
time:2016/12/29 場景:將hive中的資料匯出到oracle資料庫中 遇到的問題: 使用oozie跑job的時候,一直處於running狀態。實際上資料量很小,而且語句也不復雜。 檢視日
利用sqoop將hive和MySQL資料互匯入
1. hadoop、hive、MySQL安裝(略)啟動hadoop 執行start-all.sh start-dfs.sh start-yarn.sh 2. 下載sqoop 3. 解壓 #tar -zxvfsqoop-1.4.6.bin__hadoop-
hive的mr和map-reduce基本設計模式
key format values 模式 none columns lan pac ... (原創文章,謝絕轉載~) hive可以使用 explain 或 explain extended (select query) 來看mapreduce執行的簡要過程描述。expla
利用sqoop從 hive中往mysql中導入表出現的問題
ive ptr 解析 修改 技術 字段 map temp article 這個錯誤的原因是指定Hive中表字段之間使用的分隔符錯誤,供Sqoop讀取解析不正確。如果是由hive執行mapreduce操作匯總的結果,默認的分隔符是 ‘\001‘,否則如果是從HDFS文件導入
大資料處理神器map-reduce實現(僅python和shell版本)
熟悉java的人直接可以使用java實現map-reduce過程,而像我這種不熟悉java的怎麼辦?為了讓非java程式設計師方便處理資料,我把使用python,shell實現streaming的過程,也即為map-reduce過程,整理如下: 1.如果資料不在hive裡面,而在
sqoop匯入hive資料時對換行等特殊字元處理
使用場景: 公司大資料平臺ETL操作中,在使用sqoop將mysql中的資料抽取到hive中時,由於mysql庫中默寫欄位中會有換行符,導致資料存入hive後,條數增多(每個換行符會多出帶有null值得一條資料),導致統計資料不準確。 解決辦法: 利用一下兩個引數
python將Excel資料匯出幷儲存在json檔案中
一:python3.6,安裝xlrd模組(windows 環境下easy_install-3.6.exe xlrd) 二:程式碼如下: # -*- coding: utf-8 -*- import xlrd import json def open_excel(file): """
sqoop 從 hive 導到mysql遇到的問題
2013-08-22 周海漢/文 2013.8.22 環境 hive 版本hive-0.11.0 sqoop 版本 sqoop-1.4.4.bin__hadoop-1.0.0 從hive導到mysql mysql 表:
hive資料匯出
通過insert命令進行匯出 insert overwrite[local] directory 'path' select * ... ->匯出到本地目錄 insert overwrite local directory '/opt/da
JS 將Table資料匯出到Excel表
通過JavaScript方法將table中的資料匯出在excel表中,使用方便,可以直接瀏覽器直接下載所需要的excel表,一般適用於後臺管理的匯出資料需求。 使用方法 1.對table標籤設定id,例如:id=”ta” 2.點選按鈕呼叫 <but
如何使用SQLyog將大量資料匯入mysql資料庫
之前是通過SQLyog將excel檔案儲存為csv檔案,然後匯入mysql資料庫,不過由於資料量大,建表語句寫的很麻煩(先copy Excel橫表的第一行(屬性那一行),然後轉置,到txt檔案,寫建表語句,加逗號),昨天用一天的時間琢磨這個問題,在前輩的指點下,發現這個能匯
【python Excel】如何使用python將大量資料匯出到Excel中的小技巧之二
最近對python的openpyxl 升級到了__version__ = '2.5.4',發現原先的程式碼不能使用,各種報錯之後,然後重新了寫的版本,故分享給各位同仁。如有錯誤,敬請賜教。# coding:utf-8 """ File Name: Excel.py Func
用sqoop將oracle資料匯入Hbase 使用筆記
網上已經有很多關於這方面的資料,但是我在使用過程中也遇見了不少問題 1. sqoop 的環境我沒有自己搭建 直接用的公司的 2. oracle 小白怕把公司環境弄壞了,自己用容器搭建了一個 docker pull docker.io/wnameless/oracle-xe
將excel資料匯入mysql中
1.開啟存放資料段的Excel檔案,處理好列的關係,將不必要的列都刪除掉,將Excel另存為CSV格式。2.在MySQL中建表,列的名字和資料格式都要和Excel中的一致。建表格式參考:CREATE TABLE IF NOT EXISTS data1( id INT UN