
PathSim:異構資訊網路中基於元路徑的Top-K相似度搜索(一)
阿新 • • 發佈:2019-01-31
2018年到啦,祝大家新年快樂~~時間過得真快,一年又這樣匆匆過去了,回想2017年,我。。。確實也沒怎麼努力學習,我深刻檢討,所以,先立個flag,2018年,我要認真鑽研,順利畢業,找個好工作,恩!好了,閒話到此為止,下面進入正題~
這篇部落格總結了異質資訊網路中一個計算相似性的PathSim演算法,有些人可能對異質資訊網路並不熟悉,下面就來簡單介紹一下相關的概念,再來介紹這個演算法及其應用。
相關概念
1.異質資訊網路
異質資訊網路英文全稱 heterogeneous information network,也可以被譯為異構資訊網路,但這個概念可能與通訊網路中的異構網路的概念混淆, 所以大多數都被翻譯為異質資訊網路。異質資訊網路G=(V
圖1:網路例項
2.網路模式
網路模式(Network Schema)是定義在物件型別(A)和關係型別(R)上的一個有向圖, 是資訊網路的元描述S=(A,R)。包含物件型別對映θ:V→A和關係型別的對映φ:E→S。
圖2:網路模式
3.元路徑
元路徑是定義在網路模式上的連結兩類物件的一條路徑,形式化定義為
圖3:元路徑示例
PathSim演算法介紹
1.演算法背景
儘管已經有很多相似性度量方法,比如路徑數、基於隨機遊走,這些方法大多偏向於高度可見或者高度集中的物件,不能捕捉到對等物件相似性的語義資訊。在一些情況下,找到相似的相同型別物件具有十分重要的意義。比如根據自己的領域和聲譽尋找相似的作者。在這種背景下,PathSim演算法被提出,由於對等關係應該是對稱的,因此,PathSim是一種基於對稱元路徑的相似性演算法。2.演算法定義
給定一個對稱元路徑P,相同型別物件x和y之間的PathSim計算公式為:
其中,px~y是x和y之間的路徑例項
3.具體例子
為了更好的理解PathSim演算法的原理,我們結合具體的例子來進行說明,以對稱元路徑ACA為例,它表示的語義是兩個作者(A)在同一個會議(C)上發表過論文。下面是一個網路中作者和會議間的鄰接矩陣Wac,表示每個作者在每個會議上發表的論文數。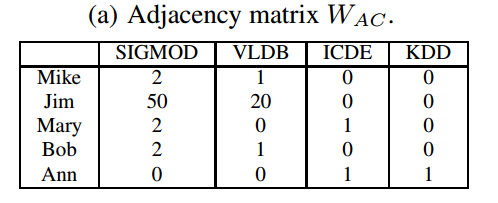
 下,交換矩陣M被定義為
下,交換矩陣M被定義為 ,其中
,其中 是型別Ai和Aj之間的鄰接矩陣,M(i,j)表示物件
是型別Ai和Aj之間的鄰接矩陣,M(i,j)表示物件 和物件
和物件 在元路徑P下的路徑例項。
利用交換矩陣計算PathSim公式為:
在元路徑P下的路徑例項。
利用交換矩陣計算PathSim公式為: 。以上圖為例,計算作者Mike和作者Jim之間的相似性
。以上圖為例,計算作者Mike和作者Jim之間的相似性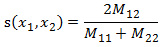 ,此例中交換矩陣為
,此例中交換矩陣為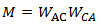 ,結果為
,結果為
|
1 |
2 |
3 |
4 |
5 |
|
|
1 |
5 |
120 |
4 |
5 |
0 |
|
2 |
120 |
2900 |
100 |
120 |
0 |
|
3 |
4 |
100 |
5 |
4 |
1 |
|
4 |
5 |
120 |
4 |
5 |
0 |
|
5 |
0 |
0 |
1 |
0 |
2 |
 ,所以作者Mike和作者Jim之間的相似性為0.0826。
,所以作者Mike和作者Jim之間的相似性為0.0826。
4.相關工具
在程式設計實現該演算法之前,我們先來介紹一下需要用到的工具。在本例中,用到了圖資料庫Neo4j,這裡簡單介紹一下為什麼使用Neo4j。 Neo4j屬於NoSQL資料庫的一種,簡單解釋為非關係資料庫。圖形資料庫使用圖形模型將資料作為圖形儲存,由頂點和邊構成,與現實中的網路類似,所以對相關領域進行建模和描述是很自然的。而傳統的關係資料庫用來儲存類似網路結構的資料常常需要很多表,在進行查詢時,表與表之間的相互join就成為了瓶頸,尤其是當查詢的深度越深,效能越差。所以關係資料庫並不擅長多對多關係的資料模型,尤其是在大型資料集時。相反,Neo4j作為圖形資料庫,比較適合多對多的關係,將資料作為節點,關係作為邊來構造,也更加符合現實情況,所以在此選擇了此圖資料庫。 Neo4j的安裝此處就不再介紹,我安裝的版本是2.0.1,如果你不想改動程式碼就可以下載這個版本,高版本可能個別方法會有不同,可以檢視其提供的api進行修改。 還要介紹一個很好用的外掛Maven,在eclipse裡面可以快速安裝,方法自行百度吧~Maven是一個專案管理工具,使用者體驗十分好,有時候開發專案被匯入jar包搞到頭大,這時候就要展現Maven的強大之處了,在pom.xml檔案中新增需要的依賴,然後儲存一下需要的依賴神馬的就都匯入了,小白必備神器!5.資料準備
本例有三個檔案author.txt,conf.txt,author_conf.txt author.txt內容結構如下:作者編號,作者姓名
conf.txt內容結構如下:會議編號,會議名稱

author_conf.txt內容結構如下:作者編號,會議編號(表示作者在該會議上發表過論文)
 等等
等等6.程式設計實現
好啦,現在我們就開始程式設計實現這個演算法。首先我們先來說明一下該演算法的實現功能: Input:作者姓名 Output:與輸入作者最相似的K個作者 簡單來說,就是找到與源作者比較相似的topk個作者,這個意義在於可以進行作者合作推薦等等。該語義用元路徑表示為ACA,A代表作者節點,C代表會議節點,那麼怎麼來衡量作者與作者間的相似性呢?直觀上理解,如果兩個作者釋出在同一個會議上面的論文數越多,表示兩個作者研究的方向越一致,即相似性越高。這個思想就是上面提到的PathSim演算法,仔細研究一下該演算法,其實就是對作者在會議上發表論文次數鄰接矩陣的一個計算,具體的計算過程上面已經介紹過。 接下來就開始程式設計實現吧~ 首先,在eclipse裡面建立一個Maven專案(沒有這個外掛的先安裝一下,方法自行百度),建立過程與普通java專案類似,建立之後結構如下(把不需要的資料夾刪掉,我這裡刪除了一個src/test/java的資料夾。data資料夾是新建的,用來存放資料檔案) 然後,雙擊pom.xml檔案,點選下圖中右下角紅框,在依賴中新增專案需要的Neo4j的版本依賴,這裡用到的是2.0.1版本,新增之後,儲存一下,maven dependencies中就會自動出現右圖中的依賴,怎麼樣,是不是比手動新增方便太多,又避免了依賴新增不全,執行出錯的問題。
然後,雙擊pom.xml檔案,點選下圖中右下角紅框,在依賴中新增專案需要的Neo4j的版本依賴,這裡用到的是2.0.1版本,新增之後,儲存一下,maven dependencies中就會自動出現右圖中的依賴,怎麼樣,是不是比手動新增方便太多,又避免了依賴新增不全,執行出錯的問題。


接著就是正式開始程式設計啦,下圖是整個專案的結構,Main.java是主要邏輯程式碼,Relationships.java是關係的定義,Type.java是節點型別的定義。data資料夾中是作者、會議和他們之間關係的資料。下面分別介紹這三部分程式碼。

Type.java
該程式碼定義了圖資料庫中節點的列舉型別,包括作者和會議兩個型別標籤。package Neo4j.Neo4jDemo;
import org.neo4j.graphdb.Label;
/**
* 定義角色型別標籤
* Author 作者
* Conference 會議
* @author user
*
*/
public enum Type implements Label{
Author,Conference
}
Relationships.java
該程式碼定義了圖資料庫中關係的列舉型別,包括髮表關係型別。package Neo4j.Neo4jDemo;
import org.neo4j.graphdb.RelationshipType;
/**
* 關係型別
* Public 發表
* @author user
*
*/
public enum Relationships implements RelationshipType{
Public
}
Main.java
接下來是重頭戲了,程式碼我都進行了註釋,相信聰明的你能夠讀懂,如果有寫的不好的地方,也希望能與我交流,畢竟我也是一個正在學習中的小白。package Neo4j.Neo4jDemo;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.neo4j.graphdb.DynamicRelationshipType;
import org.neo4j.graphdb.GraphDatabaseService;
import org.neo4j.graphdb.Node;
import org.neo4j.graphdb.Relationship;
import org.neo4j.graphdb.ResourceIterable;
import org.neo4j.graphdb.Transaction;
import org.neo4j.graphdb.factory.GraphDatabaseFactory;
public class Main {
//作者集合
private static HashMap<String,String> authorMap = null;
//作者的數量
private static int authorSize = 0;
private static HashMap<String,String> confMap = null;
//會議的數量
private static int confSize = 0;
public static void main(String args[]){
//定義Neo4j資料庫,資料夾命名為ac.graphdb,字尾不能捨棄,否則neo4j community找不到資料位置
GraphDatabaseService db = new GraphDatabaseFactory().newEmbeddedDatabase("D:/Neo4jDB/ac.graphdb/");
//建立Neo4j資料庫
createGraphDB(db);
//獲取與作者Mike最相似的5個作者
List<Map.Entry<String, Float>> list = getTopKSimilarAuthor(db,"Mike",9);
//遍歷輸出k個作者
for (Map.Entry<String, Float> mapping : list) {
System.out.println(mapping.getKey() + ":" + mapping.getValue());
}
}
/**
* 獲取與作者authorName最為相似的前topk個作者
* @param db
* @param authorName
* @param k
* @return
*/
public static List<Map.Entry<String, Float>> getTopKSimilarAuthor(GraphDatabaseService db,String authorName,int k){
List<Map.Entry<String, Float>> resultList = null;
//獲得源作者Mike的會議集合
Map<String,String> confForOrginAuthorMap = getConfMapOfOneAuthor(db,authorName);
//計算Wac,即作者Mike在各個會議上面發表的論文數
int[] orginMatrix = getMatrix(confForOrginAuthorMap);
//定義相似作者集合
Map<String,Float> SimilarAuthorMap = new HashMap<String,Float>();
//遍歷作者集合
for(Map.Entry<String, String> entry:authorMap.entrySet()){
//獲得該作者的會議集合
Map<String,String> confForTargetAuthorMap = getConfMapOfOneAuthor(db,entry.getValue());
//計算Wac,即該作者在各個會議上面發表的論文數
int[] targetMatrix = getMatrix(confForTargetAuthorMap);
//計算源作者與該作者的相似性
float similarity = pathSim(orginMatrix,targetMatrix);
//將作者的名字和相似性得分作為key-value存入相似作者集合
SimilarAuthorMap.put(entry.getValue(), similarity);
System.out.println("作者"+entry.getValue()+"與Mike相似性為"+similarity);
}
List<Map.Entry<String, Float>> list = sortMap(SimilarAuthorMap);
//取集合中前k個值
resultList = list.subList(0, k);
return resultList;
}
/**
* Map集合降序排序
* @param map
* @return
*/
public static List<Map.Entry<String, Float>> sortMap(Map<String,Float> map){
List<Map.Entry<String, Float>> list = new ArrayList<Map.Entry<String, Float>>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Float>>() {
//降序排序
@Override
public int compare(Entry<String, Float> o1, Entry<String, Float> o2) {
//return o1.getValue().compareTo(o2.getValue());
return o2.getValue().compareTo(o1.getValue());
}
});
return list;
}
/**
* PathSim演算法計算兩個作者間的相似性
* @param orginMatrix
* @param targetMatrix
* @return
*/
public static float pathSim(int[] orginMatrix,int[] targetMatrix){
float similarity = 0;
int score1 = 0, score2 = 0, score3 = 0;
for(int i=0;i<confSize;i++){
score1 += orginMatrix[i]*targetMatrix[i];
score2 += orginMatrix[i]*orginMatrix[i];
score3 += targetMatrix[i]*targetMatrix[i];
}
similarity = (float)score1;
similarity *= 2.0;
similarity /= (float)(score2 + score3);
return similarity;
}
/**
* 獲得作者-會議鄰接矩陣
* @param confForAuthorMap
* @return
*/
public static int[] getMatrix(Map<String,String> confForAuthorMap){
int[] matrix = new int[confSize];
for(Map.Entry<String, String> conf: confForAuthorMap.entrySet()){
//System.out.println("作者Jim"+"在"+conf.getKey()+"會議上發表過論文,次數為"+conf.getValue());
matrix[Integer.parseInt(conf.getKey())-1] = Integer.parseInt(conf.getValue());
}
return matrix;
}
/**
* 獲取作者author的會議map,返回會議Id和發表論文數
* @param db
* @param author
* @return <confId,paperCount>
*/
public static Map<String,String> getConfMapOfOneAuthor(GraphDatabaseService db,String author){
Map<String,String> confForAuthorMap = new HashMap<String,String>();
try(Transaction tx = db.beginTx()){
ResourceIterable<Node> orginNodes = db.findNodesByLabelAndProperty(Type.Author, "authorName", author);
for(Node orginNode:orginNodes){
Iterable<Relationship> allRealtionships = orginNode.getRelationships(DynamicRelationshipType.withName("Public"));
for(Relationship r : allRealtionships){
Node conf = r.getEndNode();
confForAuthorMap.put(String.valueOf(conf.getProperty("confId")),String.valueOf(r.getProperty("paperCount")));
}
}
tx.success();
}
return confForAuthorMap;
}
/**
* 建立Neo4j資料庫
* @param db
*/
public static void createGraphDB(GraphDatabaseService db){
//定義作者集合
authorMap = getHashMap("data/author.txt");
authorSize = authorMap.size();
//定義會議集合
confMap = getHashMap("data/conf.txt");
confSize = confMap.size();
//定義關係集合
Map<String,List<String>> relations = getRelation();
//建立Neo4j事務
try(Transaction tx = db.beginTx()){
//遍歷作者集合建立作者節點
for(Map.Entry<String, String> entry:authorMap.entrySet()){
Node author = db.createNode(Type.Author);
author.setProperty("authorId", entry.getKey());
author.setProperty("authorName", entry.getValue());
}
//遍歷會議集合建立會議節點
for(Map.Entry<String, String> entry:confMap.entrySet()){
Node conf = db.createNode(Type.Conference);
conf.setProperty("confId", entry.getKey());
conf.setProperty("confName", entry.getValue());
}
//遍歷關係集合建立關係
for(Map.Entry<String, List<String>> entry:relations.entrySet()){
String authorId = entry.getKey();
List<String> confIdList = entry.getValue();
//System.out.println("作者id:"+entry.getKey()+"該會議發表論文數:"+entry.getValue().size());
for(String confId:confIdList){
//統計作者authorId在confId會議上發表論文的次數
int paperCount = Collections.frequency(entry.getValue(), confId);
//System.out.println("作者:"+authorId+"在會議"+confId+"上發表論文數" + Collections.frequency(entry.getValue(), confId));
//查詢符合條件的作者和會議
ResourceIterable<Node> authors = db.findNodesByLabelAndProperty(Type.Author, "authorId", authorId);
ResourceIterable<Node> confs = db.findNodesByLabelAndProperty(Type.Conference, "confId", confId);
for(Node author:authors){
for(Node conf:confs){
//為作者和會議建立關係
Relationship relationship = author.createRelationshipTo(conf, Relationships.Public);
//將發表論文次數作為“發表”關係的屬性
relationship.setProperty("paperCount", paperCount);
}
}
}
}
//提交事務
tx.success();
System.out.println("Done successfully");
}
}
/**
* 根據傳入的檔案路徑,獲取作者Map或者會議Map
* @param path
* @return
*/
public static HashMap<String,String> getHashMap(String path){
HashMap<String,String> hashMap = new HashMap<String,String>();
File file = new File(path);
if(!file.exists()){
System.out.println("缺少檔案!");
return null;
}
BufferedReader bufferedReader = null;
try {
bufferedReader = new BufferedReader(new FileReader(file));
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
String readString = null;
try {
while((readString = bufferedReader.readLine())!=null){
String[] splitString = readString.split(" ");
String num = splitString[0];
String content = splitString[1];
hashMap.put(num, content);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return hashMap;
}
/**
* 獲取作者-會議關係集合
* @return <authorId,[confIds]>
*/
public static Map<String,List<String>> getRelation(){
Map<String,List<String>> relations = new HashMap<String,List<String>>();
File relation_file = new File("data/author_conf.txt");
if(!relation_file.exists()){
System.out.println("缺少檔案!");
return null;
}
BufferedReader bufferedReader = null;
try {
bufferedReader = new BufferedReader(new FileReader(relation_file));
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
String readString = null;
List<String> confNum = new ArrayList<String>();
try {
while((readString = bufferedReader.readLine())!=null){
String[] splitString = readString.split(" ");
String authorNum = splitString[0];
//這裡進行判斷,如果是一個新的作者,List集合重新初始化,新增新作者發表的會議
if(!relations.containsKey(authorNum)){
confNum = new ArrayList<String>();
}
confNum.add(splitString[1]);
relations.put(authorNum, confNum);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return relations;
}
}

 瀏覽器啟動之後,點選左側三個綠圓,再點選下面紅圈的點,就可以出現下圖效果,網路的完整結構都可以看到,黃色圈代表作者,藍色圈代表會議,連線代表發表關係。發表次數越多,連邊越粗且顏色越重。點選其中的點和邊,右側會出現相關的資訊。
瀏覽器啟動之後,點選左側三個綠圓,再點選下面紅圈的點,就可以出現下圖效果,網路的完整結構都可以看到,黃色圈代表作者,藍色圈代表會議,連線代表發表關係。發表次數越多,連邊越粗且顏色越重。點選其中的點和邊,右側會出現相關的資訊。


執行程式碼結果為下圖,與Mike最為相似的9個作者,如果結果中不想包括Mike作者自己,可以修改getTopKSimilarAuthor方法中的resultList = list.subList(0, k)為resultList = list.subList(1, k+1)。結果中作者Mike與作者Jim的相似性與上面例項中計算的結果相同,可見演算法實現是正確的。
 至此,我們已經實現了ACA路徑下,作者間相似性的PathSim演算法。但實際異質資訊網路中作者與作者之間還可以通過不同的元路徑進行連結,比如APA、ACACA、APAPA等,但都是基於這個思想,所以希望通過這個簡單的例子能夠開啟大家的思維,畢竟我知道從零開始研究確實是一個很艱難的過程,感謝csdn博友王肅勤提供的程式碼(純邏輯實現),給了我很多啟發,在此基礎上加入了Neo4j,並進行了簡單計算。
由於資料集比較簡單,僅作為測試使用,之後的工作將會使用更加複雜的dblp資料集來驗證演算法的準確性。如果有進展我會繼續更新部落格的~
最後附上程式碼的壓縮包連結,也可以去我釋出的資源裡面下載 程式碼
以上~
至此,我們已經實現了ACA路徑下,作者間相似性的PathSim演算法。但實際異質資訊網路中作者與作者之間還可以通過不同的元路徑進行連結,比如APA、ACACA、APAPA等,但都是基於這個思想,所以希望通過這個簡單的例子能夠開啟大家的思維,畢竟我知道從零開始研究確實是一個很艱難的過程,感謝csdn博友王肅勤提供的程式碼(純邏輯實現),給了我很多啟發,在此基礎上加入了Neo4j,並進行了簡單計算。
由於資料集比較簡單,僅作為測試使用,之後的工作將會使用更加複雜的dblp資料集來驗證演算法的準確性。如果有進展我會繼續更新部落格的~
最後附上程式碼的壓縮包連結,也可以去我釋出的資源裡面下載 程式碼
以上~