
用gensim實現word2vec 和 glove
本篇講講gensim的word2vec模型的使用以及 glove模型用gensim來實現!
首先我們來講word2vec, 剛開始接觸的時候比較迷糊, 我是從tensorflow的神經網路切入的,瞭解了one-hot 知道要將word 轉換成向量才能作為tensor的輸入,因此之前的文章也專門寫了怎麼將word 轉換成是很tensor輸入格式的操作.網路上大部分文章都會很詳盡的講述了word2vec的原理, CBOW 和 SKIP-GRAW是word2vec的兩種基本模型,前者是以周邊詞預測中間詞,後者是以中間詞預測周邊詞.具體原理本文就不在講述了.總而言之 word2vec 是一種將word轉換成詞向量的方法, 你可以用tensorflow來實現,也可以用現成的 gensim來實現. gensim中已經將word2vec訓練好了,你只需要將語料傳入gensim定義好的方法中,則無需再設計什麼神經網路的框架,gensim內部已經定義了一套完整的框架來訓練你傳入的語料,當然 window_size 這樣的引數是要自己傳入的!
話不多說我們上程式碼:
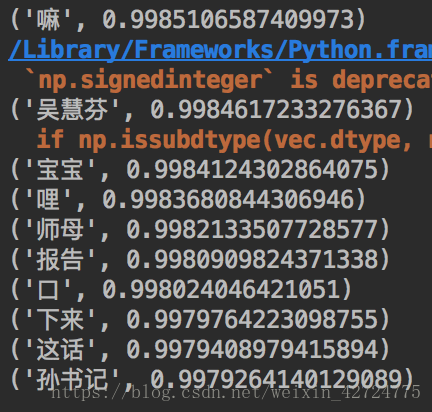
import jieba from gensim.models import word2vec #對你的語料進行分詞, 目前用的是jieba分詞,為什麼要進行分詞? 因為中文語意強大,因此進行分詞能夠更好的將有意義的詞放在一起 #如果你對你的分詞結果不滿意,也可以認為干預, 比如用jieba.suggest_freq()函式來制定某些分詞 def jieba_cut(filename, cut_filename): with open(filename, 'rb') as f: mycontent = f.read() jieba_content = jieba.cut(mycontent, cut_all=False) final_file = ' '.join(jieba_content) final_file = final_file.encode('utf-8') with open(cut_filename, 'wb+') as cut_f: cut_f.write(final_file) def my_word2vec(cut_filename): mysetence = word2vec.Text8Corpus(cut_filename) # size: embedding的維數 ,hs: 1為負取樣, min_count 詞頻 windows: 視窗大小 model = word2vec.Word2Vec(mysetence, size=100, hs=1, min_count=1, window=3) return model if __name__ == '__main__': filename = r'/Users/apple/Documents/語料/renmingdemingyi.txt' cut_filename = r'/Users/apple/Documents/語料/renmingdemingyi_cut.txt' jieba_cut(filename, cut_filename) model = my_word2vec(cut_filename) for key in model.similar_by_word(u'李達康', topn=10): print(key)
執行這段程式碼:

我用的語料比較簡單,人民的名義小說, 也沒有做任何特殊的處理,所以匹配的也不是很好! 主要是講解一下就是這麼個操作思路. 你也可以用tensorflow 自己來實現word2vec!
word2vec的引數關係還是比較大的, 比如上面的code 把hs=1 取消了 那得出的結果有些天差地別!
接下來我們看看glove的東東, 聽說這個glove比word2vec還厲害~~ 由於我用的是python ,也不想在mac電腦上跑虛擬機器,所以就沒有去搭建glove的生成環境,直接從glove官網上下載了語料 glove.6B.50d.txt 這個表示 50維 前面6B是什麼 不清楚.....
那麼下載了glove.6B.50d.txt如何使用呢? 其實 gensim也可以使用glove的txt 差別就在於gensim的格式比glove.6B.50d.txt多了一行 多出的這行是首行 --- 行數 維度 比如 400000 50 這樣的一行!
既然如此我們就可以直接將glove.6B.50d.txt改造一下,新增400001 50 這樣的行在首行 (400001 50 ) 這個是glove.6B.50d.txt的行數和維度
因此我們用glove的語料改造一下 就可以直接用
import gensim
from glove_vec import GloveVec
def load(filename):
myglovevec = GloveVec(filename, 50)
model = gensim.models.KeyedVectors.load_word2vec_format(myglovevec.get_file()) #GloVe Model
#model_name = r'/Users/apple/Documents/語料/my_model.npy'
#model.save(model_name)
return model
model = load(r'/Users/apple/Documents/語料/glove.6B.50d.txt')
for key in model.similar_by_word(r'brother', topn=10):
print(key)其中GloveVec這個類主要做的就是添加了 (40001 50) 這個, 你也可以手動新增!
執行上面的程式碼的到如下:
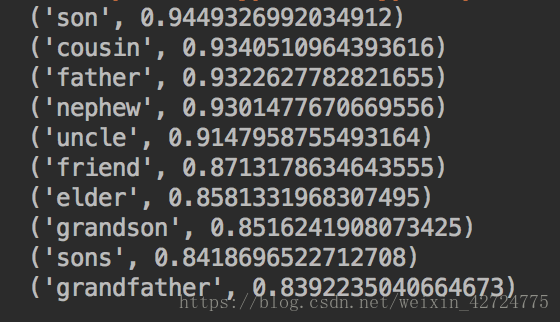
效果還是不錯的! 可以直接使用!
我沒有下載glove中文的語料,所以就用英文的做寫比較! 聽說中文的話 阿里的新開源的
本文的全部程式碼會上傳的github! (目前暫時未上傳)