
centos 部署Hadoop-3.0-高效能叢集(一)安裝
Hadoop概述:Hadoop是一個由Apache基金會所開發的分散式系統基礎架構。使用者可以在不瞭解分散式底層細節的情況下,開發分散式程式。充分利用叢集的威力進行高速運算和儲存。
Hadoop的框架最核心的設計就是:HDFS和MapReduce。HDFS分散式檔案系統為海量的資料提供了儲存,則MapReduce為海量的資料提供了計算。
網方網站:http://hadoop.apache.org/
廢話不多說,下面開始搭建
一、實驗環境 準備
安裝前,3臺虛擬機器IP及機器名稱如下:
主機名 IP地址 角色
ha146.cn 192.168.1.146 NameNode
ha147.cn 192.168.1.147 DataNode1
ha120.cn 192.168.1.120 DataNode2
因為是本地搭建所以直接關閉三臺機器防火牆
systemctl stop firewalld.service
systemctl disable firewalld.service
(1)三臺機器上配置hosts檔案,(三臺都配置)
vim /etc/hosts 新增
192.168.1.146 ha146.cn
192.168.1.147 ha147.cn
192.168.1.120 ha120.cn
(2)建立執行hadoop使用者賬號和Hadoop目錄(3臺都建立)
useradd -u 8000
echo 123456 | passwd --stdin hadoop #設定密碼
(3)給hadoop賬戶增加sudo許可權
vim /etc/sudoers
新增 hadoop ALL=(ALL) ALL

:wq!強制儲存
(4)配置Hadoop環境,安裝Java環境JDK:三臺機器上都要配置
我用的是原始碼安裝 jdk1.8.0_131 。也可以yum安裝 。
官方地址: http://www.oracle.com/technetwork/java/javase/downloads/index.htm
JDK下載地址 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
tar xvf jdk-linux-x64.tar.gz -C /usr/local/
配置環境變數 vim /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_131
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATHsource /etc/profile
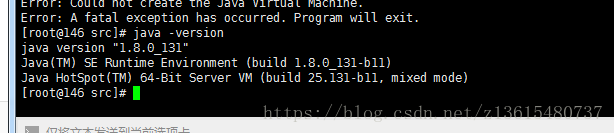
java -version 檢視是否配置成功
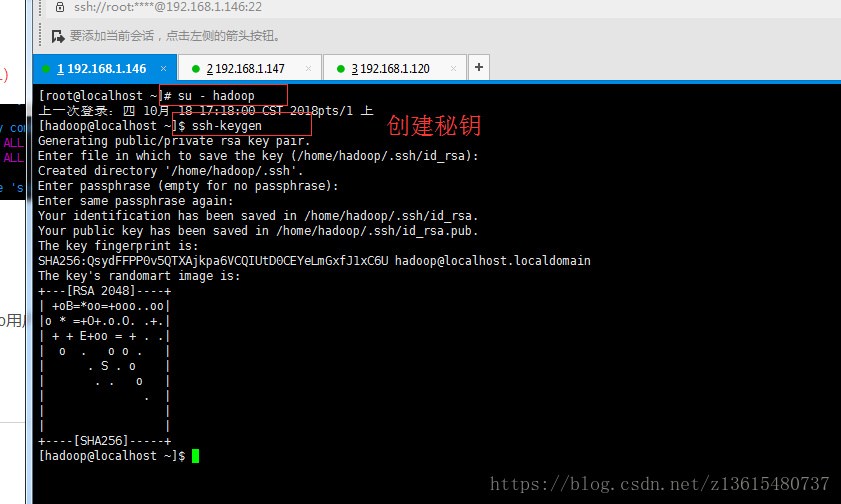
(4)配置ssh無密碼登入
在146伺服器上 切換到hadoop使用者 su - hadoop
ssh-keygen
[[email protected] ~]$ ssh-copy-id 192.168.1.147
[[email protected] ~]$ ssh-copy-id 192.168.1.120
測試 ssh 192.168.1.147 如果直接登入,不需要密碼說明成功
二、配置hadoop
在146上安裝Hadoop 並配置成namenode主節點
Hadoop安裝目錄:/home/hadoop/hadoop-3.0.0
使用root帳號將hadoop-3.0.0.tar.gz 上傳到伺服器 可以去官網下載http://hadoop.apache.org/ 我的是3.0
上傳到hadoop的家目錄 切換到hadoop解壓 只要解壓檔案就可以,不需要編譯安裝
tar xvf hadoop-3.0.0.tar.gz

建立hadoop相關的工作目錄(每臺機上都要建立目錄)
mkdir -p /home/hadoop/dfs/name /home/hadoop/dfs/data /home/hadoop/tmp#每臺機上都要建立目錄
sudo chown -R hadoop:hadoop /home/hadoop/* # 確定每個目錄下的所屬都是hadoop 每臺機都要執行
配置Hadoop:需要修改7個配置檔案。進入配置檔案 cd hadoop-3.0.0/etc/hadoop/
檔名稱:hadoop-env.sh、yarn-evn.sh、workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
1、 vim hadoop-env.sh (指定java執行環境變數)
改:54 # export JAVA_HOME=
為:export JAVA_HOME=/usr/local/jdk1.8.0_131/
2、vim yarn-env.sh 儲存yarn框架的執行環境
檢視優先規則: 23行
## Precedence rules:
##
## yarn-env.sh > hadoop-env.sh > hard-coded defaults
3、vim core-site.xml,指定訪問hadoop web介面訪問路徑
在19 20行新增
<property>
<name>fs.defaultFS</name>
<value>hdfs://ha146.cn:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>13107</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>io.file.buffer.size 的預設值 4096 。這是讀寫 sequence file 的 buffer size, 可減少 I/O 次數。在大型的 Hadoop cluster,建議可設定為 65536
4、vim hdfs-site.xmldfs.http.address配置了hdfs的http的訪問位置;dfs.replication配置了檔案塊的副本數,一般不大於從 機的個數。
還是19 20行 新增
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ha146.cn:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
注:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ha146.cn:9001</value> # 通過web介面來檢視HDFS狀態
</property>
<property>
<name>dfs.replication</name>
<value>2</value> #每個Block有2個備份。
</property>
5、vim mapred-site.xml 這個是mapreduce任務的配置,由於hadoop2.x使用了yarn框架,所以要實現分散式部署,必須在mapreduce.framework.name屬性下配置為yarn。mapred.map.tasks和mapred.reduce.tasks分別為map和reduce的任務數,同時指定:Hadoop的歷史伺服器historyserver Hadoop自帶了一個歷史伺服器,可以通過歷史伺服器檢視已經執行完的Mapreduce作業記錄,比如用了多少個Map、用了多少個Reduce、作業提交時間、作業啟動時間、作業完成時間等資訊。預設情況下,Hadoop歷史伺服器是沒有啟動的,我們可以通過下面的命令來啟動Hadoop歷史伺服器
$ /home/hadoop/hadoop-3.0.0/sbin/mr-jobhistory-daemon.sh start historyserver
historyserverWARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
WARNING: /home/hadoop/hadoop-3.0.0/logs does not exist. Creating.
這樣我們就可以在相應機器的19888埠上開啟歷史伺服器的WEB UI介面。可以檢視已經執行完的作業情況。
還是19 20行
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>6、vim yarn-site.xml 該檔案為yarn框架的配置,主要是一些任務的啟動位置
同樣還是在<configuration></configuration> 之間新增
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>ha146.cn:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>ha146.cn:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>ha146.cn:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>ha146.cn:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>ha146.cn:8088</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/home/hadoop/hadoop-3.0.0/etc/hadoop:/home/hadoop/hadoop-3.0.0/share/hadoop/common/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/common/*:/home/hadoop/hadoop-3.0.0/share/hadoop/hdfs:/home/hadoop/hadoop-3.0.0/share/hadoop/hdfs/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/hdfs/*:/home/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/*:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn/* </value>
</property>注意classpath下面只有一行沒有回車
7、vim workers 編輯datanode節點host
ha147.cn
ha120.cn

三、複製配置初始化 啟動
上面是146主服務配置完了 需要將=剛剛配置的檔案複製到147和120伺服器上
scp /home/hadoop/hadoop-3.0.0/etc/hadoop/* 192.168.1.147:/home/hadoop/hadoop-3.0.0/etc/hadoop/
scp /home/hadoop/hadoop-3.0.0/etc/hadoop/* 192.168.1.120:/home/hadoop/hadoop-3.0.0/etc/hadoop/
在146上初始化 Hadoop hadoop namenode的初始化,只需要第一次的時候初始化,之後就不需要了
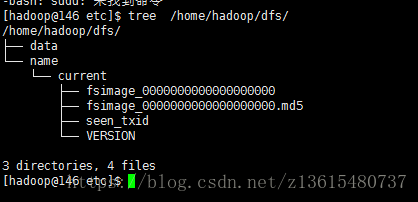
/home/hadoop/hadoop-3.0.0/bin/hdfs namenode -format
echo $? 看執行成功沒
tree /home/hadoop/dfs/
/home/hadoop/hadoop-3.0.0/sbin/start-dfs.sh 啟動
/home/hadoop/hadoop-3.0.0/sbin/stop-dfs.sh 關閉
/home/hadoop/hadoop-3.0.0/sbin/start-all.sh 啟動全部
新增環境變數 HADOOP_HOME
[[email protected]~]# vim /etc/profile #新增追加以下內容:
export HADOOP_HOME=/home/hadoop/hadoop-3.0.0
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[[email protected]~]# source /etc/profile
[[email protected]~]# start #輸入start 按兩下tab鍵,測試命令補齊
相關推薦
centos 部署Hadoop-3.0-高效能叢集(一)安裝
Hadoop概述:Hadoop是一個由Apache基金會所開發的分散式系統基礎架構。使用者可以在不瞭解分散式底層細節的情況下,開發分散式程式。充分利用叢集的威力進行高速運算和儲存。 Hadoop的框架最核心的設計就是:HDFS和MapReduce。HDFS分散式檔案系統為海
Vue-cli 3.0 構建專案(一)構建初始專案
1. 環境配置 安裝 Vue-cli 3.0 腳手架工具 終端輸入執行 npm install -g @vue/cli 安裝完成後,輸入 vue -V 檢視是否安裝成功 新的命令語句 2. 初始化專案 終端輸入執行
iOS下OpenGL ES 3.0程式設計入門(一):構建Hello World環境
OpenGL ES簡介: OpenGL ES (OpenGL for Embedded Systems) 是 OpenGL三維圖形 API 的子集,針對手機、PDA和遊戲主機等嵌入式裝置而設計。該API由Khronos集團定義推廣,Khronos是一個圖形軟硬體
Redis叢集(一)安裝配置和簡便槽分配
為什麼要用Redis叢集 Redis叢集是Redis提供的分散式資料庫方案,叢集通過**分片(sharding)**來進行資料提供,並提供複製和故障轉移功能。 學習記錄以下幾點: 節點 槽指派 命令執行 重新分片 轉向 故障轉移 訊
大資料環境基礎之Centos安裝Haoop叢集(5)安裝hadoop叢集
首先要去下載hadoop-2.5.2.tar.gz安裝包,將安裝包移動到當前使用者的根目錄解壓 用命令ls檢視解壓後的hadoop 配置hadoop環境變數 配置jdk路徑,終端輸入 vi hadoop-env.sh 配置yarn環境變數 yarn-env
阿里雲ECS伺服器部署HADOOP叢集(一):Hadoop完全分散式叢集環境搭建
準備: 兩臺配置CentOS 7.3的阿里雲ECS伺服器; hadoop-2.7.3.tar.gz安裝包; jdk-8u77-linux-x64.tar.gz安裝包; hostname及IP的配置: 更改主機名: 由於系統為CentOS 7,可以直接使用‘hostnamectl set-hostname 主機
最新OpenShift 3.9 叢集(Ansible)安裝
說明:本篇主要是基於最新的openshift3.9進行的叢集安裝,安裝環境是虛擬機器,在本地通過VirtualBox安裝centos7.5虛擬機器,準備了3臺虛擬機器,一臺作為master,另外兩臺slave。通過這種方式模擬實際伺服器的叢集搭建openshift 特別注意 搭建的前提
AFNetWorking(3.0)原始碼分析(五)——AFHTTPRequestSerializer & AFHTTPResponseSerializer
在前面的幾篇部落格中,我們分析了AFURLSessionMangerd以及它的子類AFHTTPSessionManager。我們對AF的主要兩個類,有了一個比較全面的瞭解。 對於AFHTTPSessionManager,當其在要傳送請求時,會呼叫AFHTTPRequestSerial
AFNetWorking(3.0)原始碼分析(四)——AFHTTPSessionManager(2)
在上一篇部落格中,我們分析了AFHTTPSessionManager,以及它是如何實現GET/HEAD/PATCH/DELETE相關介面的。 我們還剩下POST相關介面沒有分析,在這篇部落格裡面,我們就來分析一下POST相關介面是如何實現的。 multipart/form-data請
從零搭建Hadoop叢集(一)——離線安裝YUM源搭建
概述 Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,簡稱“CDH”),基於Web的使用者管理介面,支援大部分Hadoop元件,包括HDFS、YARN、Hive、 Hbase、Zookeep
開源物聯網框架ServerSuperIO 3.0正式釋出(C#),跨平臺:Win&Win10 Iot&Ubuntu&Ubuntu Mate,一套裝置驅動跨平臺掛載,附:開發套件和教程。
3.0版本主要更新內容: 1.增加跨平臺能力:Win&Win10 Iot&Ubuntu&Ubuntu Mate 2.統一裝置驅動介面:可以一套裝置驅動,跨平臺掛載執行,降低人力成本,提高開發效率。 3.增加二次開發套件:支援控制檯和UI介面兩種方式。 4.增加配置工具:
AWS上搭建Hadoop叢集(一)——單機安裝Hadoop
課堂專案中實現了在AWS上搭建Hadoop叢集進行資料分析,過程中間不免遇到眾多問題,在此總結以供各位參考。 建立EC2例項 亞馬遜AWS服務想必大家都有所瞭解,這裡略過註冊過程(為了拿student credit還是花了一番功夫)。在EC2的介面上,
Python 3.0 新特性(1)
萬眾期待的Python3.0(final)在2008年12月3日釋出了,本文將介紹一下Python3所具有的與Python2.5不同的新特性。 Python3的下載地址是: 1.print的變化:、 在python3.0中,print成為了一個函式,將傳入的引數
CentOS部署Kubernetes1.13集群-1(使用kubeadm安裝K8S)
1.7 沒有 div docker0 forward format www dynamic 開始 參考:https://www.kubernetes.org.cn/4956.html 1.準備 說明:準備工作需要在集群所有的主機上執行 1.1系統配置 在安裝之前,
Ubuntu18.04.1配置NVIDIA驅動(run file),cuda9.0(run file),cudnn7.3.1(deb檔案) (一)
2018.12.29更新 NVIDIA驅動:https://www.geforce.cn/drivers 搜尋自己電腦的gpu版本:下面是驅動型號的一部分結果 cuda版本:https://developer.nvidia.com/cuda-toolkit
Windows mysql-8.0.11 master-slave 叢集(一)
一、下載安裝 mysql-8.0.11-winx64.zip:(2)安裝目錄:D:\Servers\mysql-8.0.11-3306(3)資料目錄:D:\Servers\mysql-8.0.11-3306\data(4)配置:D:\Servers\mysql-8.0.11
【Docker】基於例項專案的叢集部署(一)安裝環境搭建
叢集 叢集具有三高特點: 高效能 高負載 高可用 現在的環境中,經常會用到叢集,如資料庫叢集。如,我們在主機上部署資料庫節點,形成叢集。 安裝環境與配置 在Docker中部署叢集,首先要安裝Linux環境,這裡我們使用VMware虛擬機
Cocos2dx 3.0 提高篇(八)淺談Vector的使用
前兩天有人問我說在3.0 beta2版本里,使用array 後編譯出錯,其實是因為自beta版本開始,已沒有Array 和 Dictionary,取而代之的是容器:Vector 和 Map 先說Vector吧。 如果說C++的vector容器怎麼用,如果我說太多肯定一下子就
opencv,我的電腦轉換2.49版本和3.0版本筆記(vs2015)
會配置的直接從3開始改配置路徑,前面的基本上已經配置過了,出錯的直接重修配置一遍就行, 本系列文章由出品,轉載請註明出處。 寫作當前博文時配套使用的OpenCV版本: 2.4.8、2.4.9、3.0 ( 2014年4月28更新OpenCV 2
android studio | openGL es 3.0增強現實(AR)開發 (1) 建立一個openGL es 3.0開發環境
1.什麼是NDK,什麼是JNI? NDK:Native Development Kit(原生開發工具包), NDK允許使用者使用類似C / C++之類的原生程式碼語言執行部分程式。它包括下面的部分(1)從C / C++生成原生程式碼庫所需要的工具和buil