
stm32 HardFault_Handler除錯及問題查詢方法
阿新 • • 發佈:2019-01-31
相關文章
STM32出現HardFault_Handler故障的原因主要有兩個方面:
1、記憶體溢位或者訪問越界。這個需要自己寫程式的時候規範程式碼,遇到了需要慢慢排查。
2、堆疊溢位。增加堆疊的大小。
出現問題時排查的方法:
發生異常之後可首先檢視LR暫存器中的值,確定當前使用堆疊為MSP或PSP,然後找到相應堆疊的指標,並在記憶體中檢視相應堆疊裡的內容。由於異常發生時,核心將R0~R3、R12、Returnaddress、PSR、LR暫存器依次入棧,其中Return address即為發生異常前PC將要執行的下一條指令地址。
注意:暫存器均是32位,且STM32是小端模式。(參考Cortex-M3權威)
編寫問題程式碼如下:
-
void StackFlow(void)
-
{
-
int a[3],i;
-
for(i=0; i<10000; i++)
-
{
-
a[i]=1;
-
}
-
}
-
void SystemInit(void)
-
{
-
RCC->CR |= (uint32_t)0x00000001;
-
RCC->CFGR = 0x00000000;
-
RCC->CR &= (uint32_t)0xFEF6FFFF;
-
RCC->PLLCFGR = 0x24003010;
-
StackFlow();
-
RCC->CR &= (uint32_t)0xFFFBFFFF;
-
。。。。。。。。。。。。。。
- }
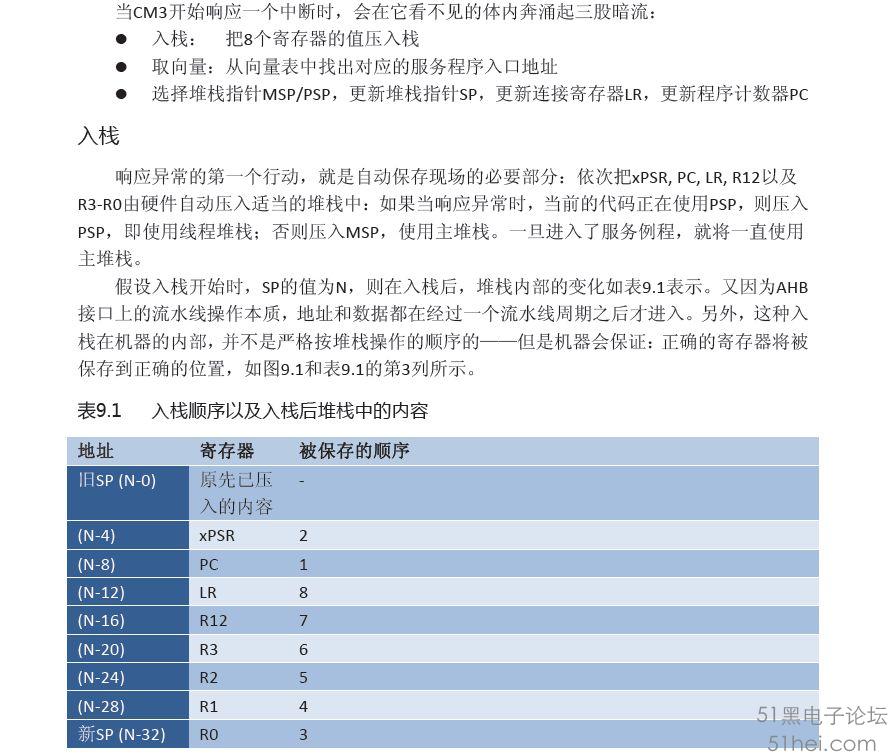
DEBUG如下圖
SP值為0x20008560,檢視堆疊裡面的值依次為R0~R3、R12、Return address、PSR、LR, 例如R0(1027 00 00), 顯然堆疊後第21個位元組到24位元組即為Returnaddress,該地址0x08001FFD即為異常前PC將要執行的下一條指令地址(即StackFlow()後面的語句處RCC->CR &= (uint32_t)0xFFFBFFFF)
另一種方法:
預設的HardFault_Handler處理方法不是B .這樣的死迴圈麼?樓主將它改成BXLR直接返回的形式。然後在這條語句打個斷點,一旦在斷點中停下來,說明出錯了,然後再返回,就可以返回到出錯的位置的下一條語句那兒
Cortex-M3/4的Fault異常是由於非法的儲存器訪問(比如訪問0地址、寫只讀儲存位置等)和非法的程式行為(比如除以0等)等造成的。常見的4種異常及產生異常的情況如下:
BusFault:在fetch指令、資料讀寫、fetch中斷向量或中斷時儲存恢復暫存器棧情況下,檢測到記憶體訪問錯誤則產生BusFault。
Memory ManagementFault:訪問了記憶體管理單元(MPU)定義的不合法的記憶體區域,比如向只讀區域寫入資料。
UsageFault:檢測到未定義指令或在存取記憶體時有未對齊。還可以通過軟體配置是否檢測到除0和其它未對齊記憶體訪問也產生該異常,預設關閉,需要在工程初始化時配置:
[cpp] viewplaincopyprint?
-
SCB->CCR |= 0x18; // enable div-by-0 and unaligned fault
HardFault:在除錯程式過程中,這種異常最常見。上面三種異常發生任何一種異常都會引起HardFault,在上面的三種異常未使能的情況下,預設發生異常時進入HardFault中斷服務程式。使能前三種異常也要在初始化時配置:
[cpp] viewplaincopyprint?
-
SCB->SHCSR |= 0x00007000; // enable Usage Fault, Bus Fault, and MMU Fault
在預設復位初始化時,HardFault使能,其它三者不使能,因此當程式中出現不合法記憶體訪問(一般是指標錯誤引起)或非法的程式行為(一般就是數學裡面常見的除0)時都將產生HardFault中斷。
[url=]2 HardFault除錯方法[/url]假設IDE環境為Keil,晶片為STM32F103。
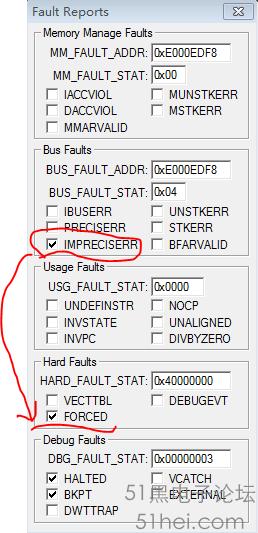
在stm32f10x_it.c中,新增軟體斷點,一旦除錯時出現Hard Fault則會在停在__breakpoint(0)處。
- void HardFault_Handler(void)
- {
- if (CoreDebug->DHCSR & 1) { //check C_DEBUGEN == 1 -> Debugger Connected
- __breakpoint(0); // halt program execution here
- }
- while (1)
- {
- }
-
}
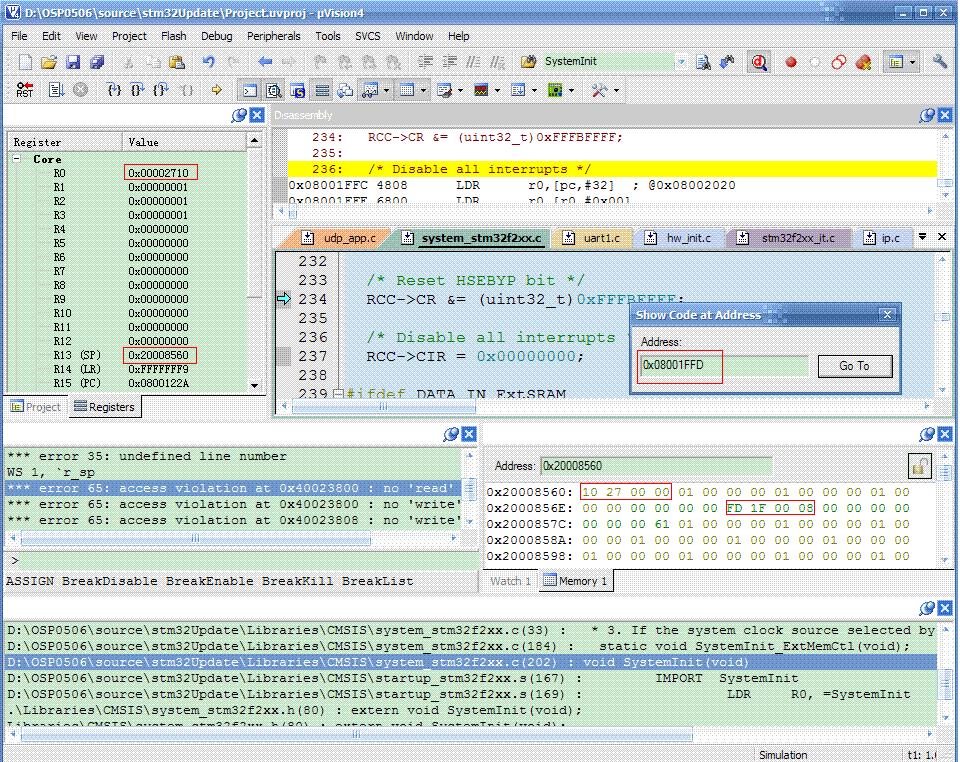
當進入HardFault斷點後,選單欄Peripherals >Core Peripherals >FaultReports開啟異常發生的報告,檢視發生異常的原因。

上面的報告發生了BUS FAULT,並將Fault的中斷服務轉向Hard Fault。
相對於檢測發生了什麼異常,定位異常發生位置顯得更重要。
(1)開啟Call Stack視窗(如下圖左側,斷點停在Hard Fault服務程式中)
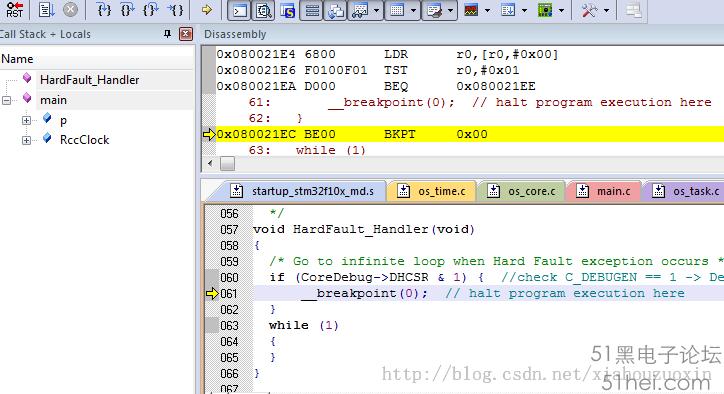
(2)在Call Stack的HardFault_Handler上右鍵Show CallerCode(有的Keil版本也可以直接雙擊)

這時將跳轉到發生異常的原始碼位置(如上圖),異常發生在p->hour=0這一行。這裡錯誤很明顯:指標p尚未為成員變數分配記憶體空間,直接訪問未分配的內粗空間肯定出錯。
再說明2點:
[1] 在複雜的情況下,即使定位了異常發生位置也很難容易的改正錯誤,要學會使用Watch視窗對發生錯誤的指標變數進行跟蹤;
[2]在問題不明晰的情況下,嘗試分析反彙編程式碼,就自己遇到的,部分情況下的異常發生在BL等跳轉指令處,BL跳轉到了不合法的記憶體地址產生異常
Refrences:
[1] Application Note209. Using Cortex-M3 and Cortex-M4 FaultExceptions.
[2] Cortex-M3權威指南