
使用sklearn進行整合學習(一)
系列
目錄
1 前言
2 整合學習是什麼?
3 偏差和方差
3.1 模型的偏差和方差是什麼?
3.2 bagging的偏差和方差
3.3 boosting的偏差和方差
3.4 模型的獨立性
3.5 小結
4 Gradient Boosting
4.1 擬合殘差
4.2 擬合反向梯度
4.2.1 契機:引入損失函式
4.2.2 難題一:任意損失函式的最優化
4.2.3 難題二:無法對測試樣本計算反向梯度
4.3 常見的損失函式
4.4 步子太大容易扯著蛋:縮減
4.5 初始模型
4.5 Gradient Tree Boosting
4.6 小結
5 總結
6 參考資料
1 前言
很多人在競賽(Kaggle,天池等)或工程實踐中使用了整合學習(例如,RF、GTB等),確實也取得了不錯的效果,在保證準確度的同時也提升了模型防止過擬合的能力。但是,我們真的用對了整合學習嗎?
sklearn提供了sklearn.ensemble庫,支援眾多整合學習演算法和模型。恐怕大多數人使用這些工具時,要麼使用預設引數,要麼根據模型在測試集上的效能試探性地進行調參(當然,完全不懂的引數還是不動算了),要麼將調參的工作丟給調參演算法(網格搜尋等)。這樣並不能真正地稱為“會”用sklearn進行整合學習。
我認為,學會調參是進行整合學習工作的前提。然而,第一次遇到這些演算法和模型時,肯定會被其豐富的引數所嚇到,要知道,教材上教的虛擬碼可沒這麼多引數啊!!!沒關係,暫時,我們只要記住一句話:引數可分為兩種,一種是影響模型在訓練集上的準確度或影響防止過擬合能力的引數;另一種不影響這兩者的其他引數。模型在樣本總體上的準確度(後簡稱準確度)由其在訓練集上的準確度及其防止過擬合的能力所共同決定,所以在調參時,我們主要對第一種引數進行調整,最終達到的效果是:模型在訓練集上的準確度和防止過擬合能力的大和諧!
本篇博文將詳細闡述模型引數背後的理論知識,在下篇博文中,我們將對最熱門的兩個模型Random Forrest和Gradient Tree Boosting(含分類和迴歸,所以共4個模型)進行具體的引數講解。如果你實在無法靜下心來學習理論,你也可以在下篇博文中找到最直接的調參指導,雖然我不贊同這麼做。
2 整合學習是什麼?
我們還是花一點時間來說明一下整合學習是什麼,如果對此有一定基礎的同學可以跳過本節。簡單來說,整合學習是一種技術框架,其按照不同的思路來組合基礎模型,從而達到其利斷金的目的。
目前,有三種常見的整合學習框架:bagging,boosting和stacking。國內,南京大學的周志華教授對整合學習有很深入的研究,其在09年發表的一篇概述性論文
bagging:從訓練集從進行子抽樣組成每個基模型所需要的子訓練集,對所有基模型預測的結果進行綜合產生最終的預測結果:
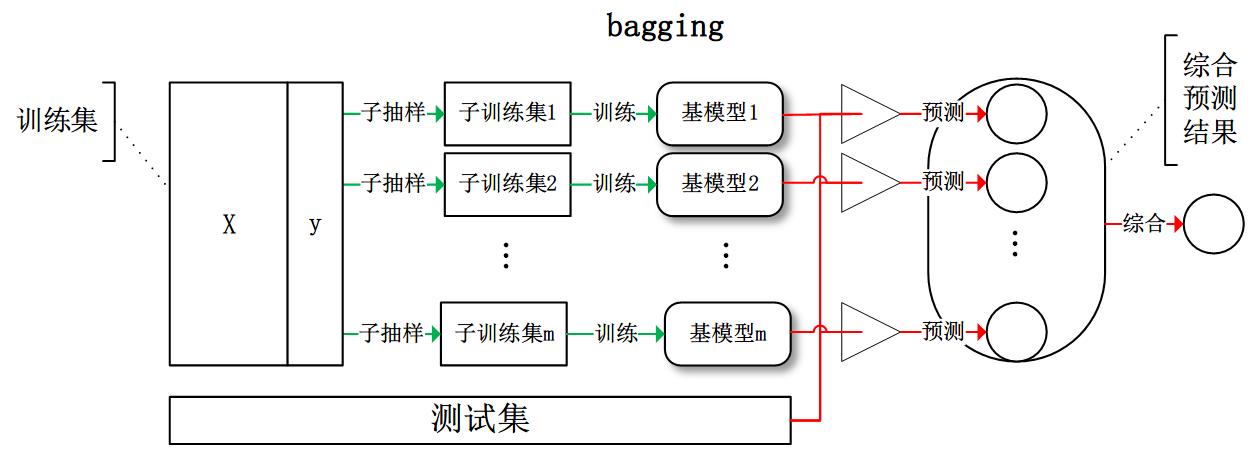
boosting:訓練過程為階梯狀,基模型按次序一一進行訓練(實現上可以做到並行),基模型的訓練集按照某種策略每次都進行一定的轉化。對所有基模型預測的結果進行線性綜合產生最終的預測結果:
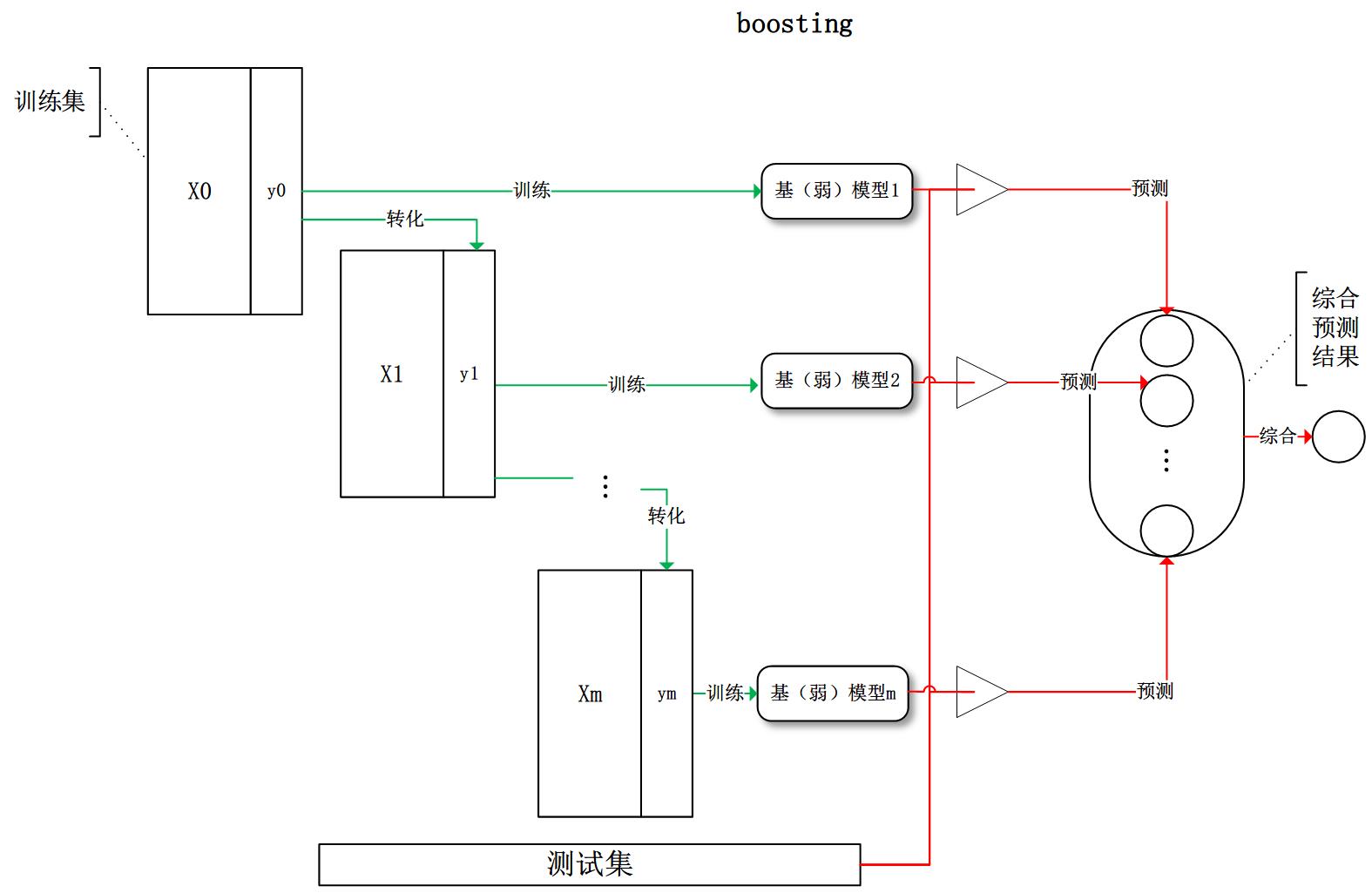
stacking:將訓練好的所有基模型對訓練基進行預測,第j個基模型對第i個訓練樣本的預測值將作為新的訓練集中第i個樣本的第j個特徵值,最後基於新的訓練集進行訓練。同理,預測的過程也要先經過所有基模型的預測形成新的測試集,最後再對測試集進行預測:
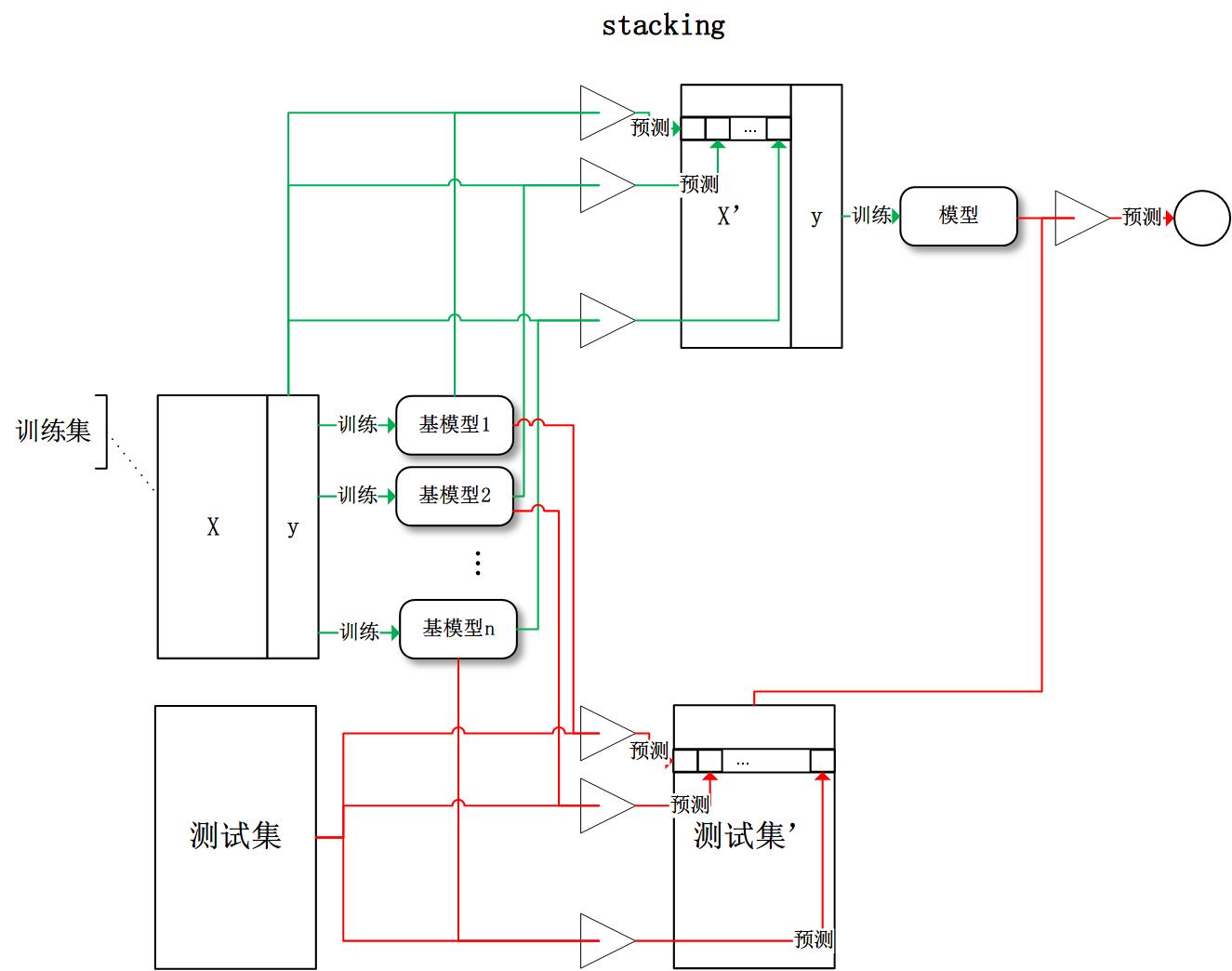
有了這些基本概念之後,直覺將告訴我們,由於不再是單一的模型進行預測,所以模型有了“集思廣益”的能力,也就不容易產生過擬合現象。但是,直覺是不可靠的,接下來我們將從模型的偏差和方差入手,徹底搞清楚這一問題。
3 偏差和方差
廣義的偏差(bias)描述的是預測值和真實值之間的差異,方差(variance)描述距的是預測值作為隨機變數的離散程度。《Understanding the Bias-Variance Tradeoff》當中有一副圖形象地向我們展示了偏差和方差的關係:

3.1 模型的偏差和方差是什麼?
模型的偏差是一個相對來說簡單的概念:訓練出來的模型在訓練集上的準確度。
要解釋模型的方差,首先需要重新審視模型:模型是隨機變數。設樣本容量為n的訓練集為隨機變數的集合(X1, X2, ..., Xn),那麼模型是以這些隨機變數為輸入的隨機變數函式(其本身仍然是隨機變數):F(X1, X2, ..., Xn)。抽樣的隨機性帶來了模型的隨機性。
定義隨機變數的值的差異是計算方差的前提條件,通常來說,我們遇到的都是數值型的隨機變數,數值之間的差異再明顯不過(減法運算)。但是,模型的差異性呢?我們可以理解模型的差異性為模型的結構差異,例如:線性模型中權值向量的差異,樹模型中樹的結構差異等。在研究模型方差的問題上,我們並不需要對方差進行定量計算,只需要知道其概念即可。
研究模型的方差有什麼現實的意義呢?我們認為方差越大的模型越容易過擬合:假設有兩個訓練集A和B,經過A訓練的模型Fa與經過B訓練的模型Fb差異很大,這意味著Fa在類A的樣本集合上有更好的效能,而Fb反之,這便是我們所說的過擬合現象。
我們常說整合學習框架中的基模型是弱模型,通常來說弱模型是偏差高(在訓練集上準確度低)方差小(防止過擬合能力強)的模型。但是,並不是所有整合學習框架中的基模型都是弱模型。bagging和stacking中的基模型為強模型(偏差低方差高),boosting中的基模型為弱模型。
在bagging和boosting框架中,通過計算基模型的期望和方差,我們可以得到模型整體的期望和方差。為了簡化模型,我們假設基模型的權重、方差及兩兩間的相關係數相等。由於bagging和boosting的基模型都是線性組成的,那麼有:

3.2 bagging的偏差和方差
對於bagging來說,每個基模型的權重等於1/m且期望近似相等(子訓練集都是從原訓練集中進行子抽樣),故我們可以進一步化簡得到:
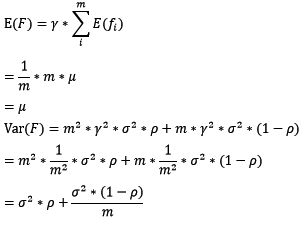
根據上式我們可以看到,整體模型的期望近似於基模型的期望,這也就意味著整體模型的偏差和基模型的偏差近似。同時,整體模型的方差小於等於基模型的方差(當相關性為1時取等號),隨著基模型數(m)的增多,整體模型的方差減少,從而防止過擬合的能力增強,模型的準確度得到提高。但是,模型的準確度一定會無限逼近於1嗎?並不一定,當基模型數增加到一定程度時,方差公式第二項的改變對整體方差的作用很小,防止過擬合的能力達到極限,這便是準確度的極限了。另外,在此我們還知道了為什麼bagging中的基模型一定要為強模型,否則就會導致整體模型的偏差度低,即準確度低。
Random Forest是典型的基於bagging框架的模型,其在bagging的基礎上,進一步降低了模型的方差。Random Fores中基模型是樹模型,在樹的內部節點分裂過程中,不再是將所有特徵,而是隨機抽樣一部分特徵納入分裂的候選項。這樣一來,基模型之間的相關性降低,從而在方差公式中,第一項顯著減少,第二項稍微增加,整體方差仍是減少。
3.3 boosting的偏差和方差
對於boosting來說,基模型的訓練集抽樣是強相關的,那麼模型的相關係數近似等於1,故我們也可以針對boosting化簡公式為:
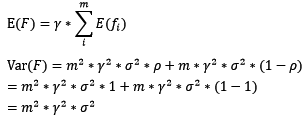
通過觀察整體方差的表示式,我們容易發現,若基模型不是弱模型,其方差相對較大,這將導致整體模型的方差很大,即無法達到防止過擬合的效果。因此,boosting框架中的基模型必須為弱模型。
因為基模型為弱模型,導致了每個基模型的準確度都不是很高(因為其在訓練集上的準確度不高)。隨著基模型數的增多,整體模型的期望值增加,更接近真實值,因此,整體模型的準確度提高。但是準確度一定會無限逼近於1嗎?仍然並不一定,因為訓練過程中準確度的提高的主要功臣是整體模型在訓練集上的準確度提高,而隨著訓練的進行,整體模型的方差變大,導致防止過擬合的能力變弱,最終導致了準確度反而有所下降。
基於boosting框架的Gradient Tree Boosting模型中基模型也為樹模型,同Random Forrest,我們也可以對特徵進行隨機抽樣來使基模型間的相關性降低,從而達到減少方差的效果。
3.4 模型的獨立性
聰明的讀者這時肯定要問了,如何衡量基模型的獨立性?我們說過,抽樣的隨機性決定了模型的隨機性,如果兩個模型的訓練集抽樣過程不獨立,則兩個模型則不獨立。這時便有一個天大的陷阱在等著我們:bagging中基模型的訓練樣本都是獨立的隨機抽樣,但是基模型卻不獨立呢?
我們討論模型的隨機性時,抽樣是針對於樣本的整體。而bagging中的抽樣是針對於訓練集(整體的子集),所以並不能稱其為對整體的獨立隨機抽樣。那麼到底bagging中基模型的相關性體現在哪呢?在知乎問答《為什麼說bagging是減少variance,而boosting是減少bias?》中請教使用者“過擬合”後,我總結bagging的抽樣為兩個過程:
- 樣本抽樣:整體模型F(X1, X2, ..., Xn)中各輸入隨機變數(X1, X2, ..., Xn)對樣本的抽樣
- 子抽樣:從整體模型F(X1, X2, ..., Xn)中隨機抽取若干輸入隨機變數成為基模型的輸入隨機變數
假若在子抽樣的過程中,兩個基模型抽取的輸入隨機變數有一定的重合,那麼這兩個基模型對整體樣本的抽樣將不再獨立,這時基模型之間便具有了相關性。
3.5 小結
還記得調參的目標嗎:模型在訓練集上的準確度和防止過擬合能力的大和諧!為此,我們目前做了一些什麼工作呢?
- 使用模型的偏差和方差來描述其在訓練集上的準確度和防止過擬合的能力
- 對於bagging來說,整體模型的偏差和基模型近似,隨著訓練的進行,整體模型的方差降低
- 對於boosting來說,整體模型的初始偏差較高,方差較低,隨著訓練的進行,整體模型的偏差降低(雖然也不幸地伴隨著方差增高),當訓練過度時,因方差增高,整體模型的準確度反而降低
- 整體模型的偏差和方差與基模型的偏差和方差息息相關
這下總算有點開朗了,那些讓我們抓狂的引數,現在可以粗略地分為兩類了:控制整體訓練過程的引數和基模型的引數,這兩類引數都在影響著模型在訓練集上的準確度以及防止過擬合的能力。
4 Gradient Boosting
對基於Gradient Boosting框架的模型的進行除錯時,我們會遇到一個重要的概念:損失函式。在本節中,我們將把損失函式的“今生來世”講個清楚!
基於boosting框架的整體模型可以用線性組成式來描述,其中h[i](x)為基模型與其權值的乘積:
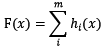
根據上式,整體模型的訓練目標是使預測值F(x)逼近真實值y,也就是說要讓每一個基模型的預測值逼近各自要預測的部分真實值。由於要同時考慮所有基模型,導致了整體模型的訓練變成了一個非常複雜的問題。所以,研究者們想到了一個貪心的解決手段:每次只訓練一個基模型。那麼,現在改寫整體模型為迭代式:
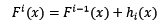
這樣一來,每一輪迭代中,只要集中解決一個基模型的訓練問題:使F[i](x)逼近真實值y。
4.1 擬合殘差
使F[i](x)逼近真實值,其實就是使h[i](x)逼近真實值和上一輪迭代的預測值F[i-1](x)之差,即殘差(y-F[i-1](x))。最直接的做法是構建基模型來擬合殘差,在博文《GBDT(MART) 迭代決策樹入門教程 | 簡介》中,作者舉了一個生動的例子來說明通過基模型擬合殘差,最終達到整體模型F(x)逼近真實值。
研究者發現,殘差其實是最小均方損失函式的關於預測值的反向梯度:

也就是說,若F[i-1](x)加上擬合了反向梯度的h[i](x)得到F[i](x),該值可能將導致平方差損失函式降低,預測的準確度提高!這顯然不是巧合,但是研究者們野心更大,希望能夠創造出一種對任意損失函式都可行的訓練方法,那麼僅僅擬合殘差是不恰當的了。
4.2 擬合反向梯度
4.2.1 契機:引入任意損失函式
引入任意損失函式後,我們可以定義整體模型的迭代式如下:
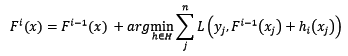
在這裡,損失函式被定義為泛函。
4.2.2 難題一:任意損失函式的最優化
對任意損失函式(且是泛函)的最優化是困難的。我們需要打破思維的枷鎖,將整體損失函式L'定義為n元普通函式(n為樣本容量),損失函式L定義為2元普通函式(記住!!!這裡的損失函式不再是泛函!!!):

我們不妨使用梯度最速下降法來解決整體損失函式L'最小化的問題,先求整體損失函式的反向梯度:
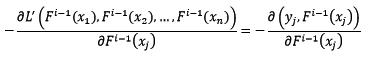
假設已知樣本x的當前預測值為F[i-1](x),下一步將預測值按照反向梯度,依照步長為r[i],進行更新:
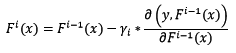
步長r[i]不是固定值,而是設計為:
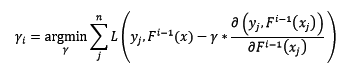
4.2.3 難題二:無法對測試樣本計算反向梯度
問題又來了,由於測試樣本中y是未知的,所以無法求反向梯度。這正是Gradient Boosting框架中的基模型閃亮登場的時刻!在第i輪迭代中,我們建立訓練集如下:
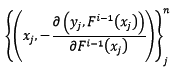
也就是說,讓基模型擬合反向梯度函式,這樣我們就可以做到只輸入x這一個引數,就可求出其對應的反向梯度了(當然,通過基模型預測出來的反向梯度並不是準確的,這也提供了泛化整體模型的機會)。
綜上,假設第i輪迭代中,根據新訓練集訓練出來的基模型為f[i](x),那麼最終的迭代公式為:
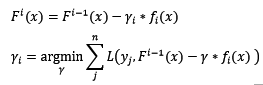
4.3 常見的損失函式
ls:最小均方迴歸中用到的損失函式。在之前我們已經談到,從擬合殘差的角度來說,殘差即是該損失函式的反向梯度值(所以又稱反向梯度為偽殘差)。不同的是,從擬合殘差的角度來說,步長是無意義的。該損失函式是sklearn中Gradient Tree Boosting迴歸模型預設的損失函式。
deviance:邏輯迴歸中用到的損失函式。熟悉邏輯迴歸的讀者肯定還記得,邏輯迴歸本質是求極大似然解,其認為樣本服從幾何分佈,樣本屬於某類別的概率可以logistic函式表達。所以,如果該損失函式可用在多類別的分類問題上,故其是sklearn中Gradient Tree Boosting分類模型預設的損失函式。
exponential:指數損失函式,表示式為:
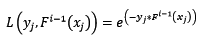
對該損失函式求反向梯度得:
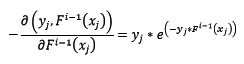
這時,在第i輪迭代中,新訓練集如下:

腦袋裡有什麼東西浮出水面了吧?讓我們看看Adaboost演算法中,第i輪迭代中第j個樣本權值的更新公式:

樣本的權值什麼時候會用到呢?計算第i輪損失函式的時候會用到:
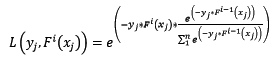
讓我們再回過頭來,看看使用指數損失函式的Gradient Boosting計算第i輪損失函式:
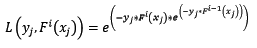
天吶,兩個公式就差了一個對權值的歸一項。這並不是巧合,當損失函式是指數損失時,Gradient Boosting相當於二分類的Adaboost演算法。是的,指數損失僅能用於二分類的情況。
4.4 步子太大容易扯著蛋:縮減
縮減也是一個相對顯見的概念,也就是說使用Gradient Boosting時,每次學習的步長縮減一點。這有什麼好處呢?縮減思想認為每次走一小步,多走幾次,更容易逼近真實值。如果步子邁大了,使用最速下降法時,容易邁過最優點。將縮減代入迭代公式:
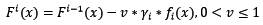
縮減需要配合基模型數一起使用,當縮減率v降低時,基模型數要配合增大,這樣才能提高模型的準確度。
4.5 初始模型
還有一個不那麼起眼的問題,初始模型F[0](x)是什麼呢?如果沒有定義初始模型,整體模型的迭代式一刻都無法進行!所以,我們定義初始模型為:
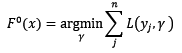
根據上式可知,對於不同的損失函式來說,初始模型也是不一樣的。對所有的樣本來說,根據初始模型預測出來的值都一樣。
4.5 Gradient Tree Boosting
終於到了備受歡迎的Gradient Tree Boosting模型了!但是,可講的卻已經不多了。我們已經知道了該模型的基模型是樹模型,並且可以通過對特徵的隨機抽樣進一步減少整體模型的方差。我們可以在維基百科的Gradient Boosting詞條中找到其虛擬碼實現。
4.6 小結
到此,讀者應當很清楚Gradient Boosting中的損失函式有什麼意義了。要說偏差描述了模型在訓練集準確度,則損失函式則是描述該準確度的間接量綱。也就是說,模型採用不同的損失函式,其訓練過程會朝著不同的方向進行!
5 總結
磨刀不誤砍柴功,我們花了這麼多時間來學習必要的理論,我強調一次:必要的理論!整合學習模型的調參工作的核心就是找到合適的引數,能夠使整體模型在訓練集上的準確度和防止過擬合的能力達到協調,從而達到在樣本總體上的最佳準確度。有了本文的理論知識鋪墊,在下篇中,我們將對Random Forest和Gradient Tree Boosting中的每個引數進行詳細闡述,同時也有一些小試驗證明我們的結論。