
Python 下字串的提取、分割與刪除- 千月的python linux 系統管理指南學習筆記(11)
阿新 • • 發佈:2019-01-31
Python 下字串的提取、分割與刪除
對於文字來講,提取、分割和刪除是我們用的較多的操作。
文字我們可以看成是字串物件。首先說到的是 in 和 not in操作。
字串的提取
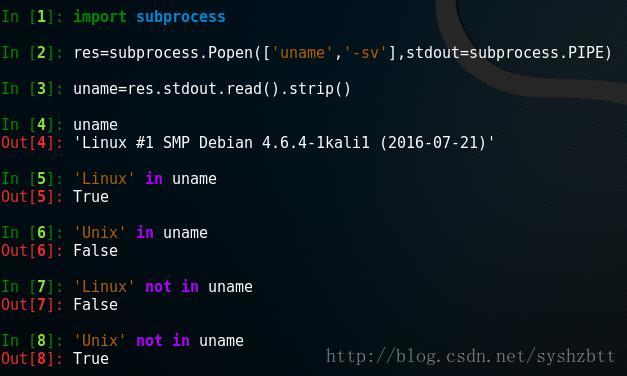
in 和 not in 判定是否包含字元
我們可以使用 in 或者 not in 來檢查一個字串是否是另一個字串的一部分。
使用方法:

從幫助中我們看到 uname.__contains__() 等價於 'Linux' in uname find() 和 index() 判定包含字元的位置 既然可以判定是否包含字元,包含字元的位置是下一個需要知道的。 字元物件.find('關鍵字') 字元物件.index('關鍵字') #查詢關鍵字處於字串的位置 兩個函式都是查詢關鍵字位置的,區別在於返回值不同。 請看例子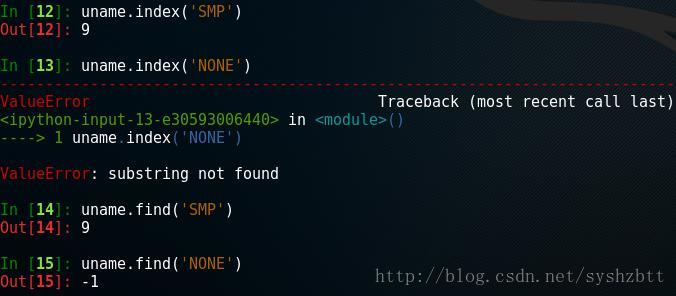
在關鍵字能查詢到的情況下 , index() 和 find() 返回值是相同的,但是在找不到的情況下,find()返回-1 而 index() 丟擲一個錯誤。 startswith() 和 endswith() 判定字串是否以特定子串開始或者結束 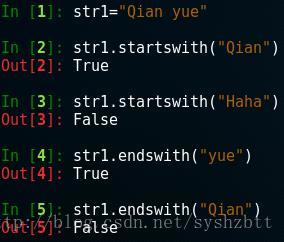
upper() 和 lower() 忽略大小寫 這兩個方法非常有用,主要用於對兩個字串比較但是不想考慮其大小寫時。 字元物件.upper() 字元物件.lower() 例子: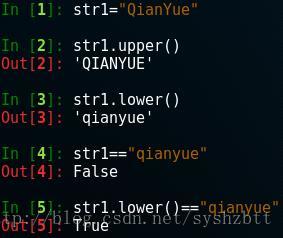
對於使用者名稱密碼或者驗證碼輸入判定時很有效。 ================================================== 字串的分割 既然可以判定是否包含字元,包含字元的位置是下一個需要知道的。 字元物件[位置1:位置2] #切分字串 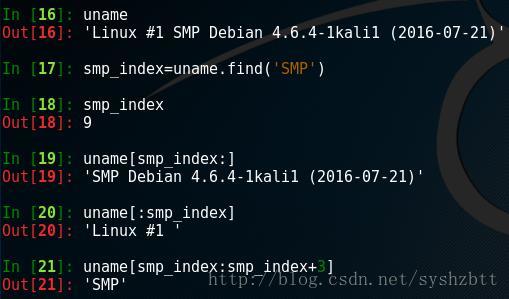
日常工作中我們可以依此來擷取個 IP 地址或者log日誌時間什麼的。 還有一種是步長擷取,用的不是很多。中間有2個冒號 [ 1:: 2 ] L i n u x 01 23 4 意思是 從1位開始,每隔2個步長擷取一個字元。答案是 iu split() 根據指定的分隔符對字串提取 這個方法的典型用法是:把希望作為分隔符的字串作為引數傳遞給它。 一般來說分隔符是一個單個字管道符,像 "," " | " 諸如此類。 字元物件.split('分隔符',[應用幾次]) #以指定分隔符分割字串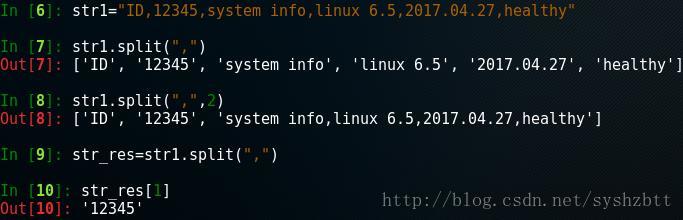
我們用逗號進行分割,如果第2個引數輸入數字,代表分割次數。 呼叫的話也很簡單。當作列表呼叫。 如果要以行來分割的話。 splitlines() 可以做到按行分割,但是一般來說行處理不用行分割的方法。這裡不贅述了。 ================================================== 字串的刪除 lstrip() rstrip() strip() 刪除空白或字元 這3個方法本來的意思是刪除前導空白 結尾空白 或者 前後空白。但是使用引數刪除任意字元。 lstrip() 刪除前導空白或者字元 rstrip() 刪除結尾空白或者字元 strip() 刪除前後的空白或者字元 注:所有strip() 方法會建立或者返回新的字串物件,不會修改原有物件。 使用方法: 字元物件.strip(['關鍵字']) #刪除空白或者關鍵字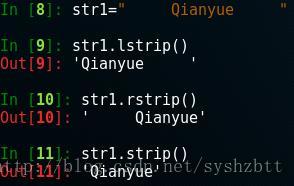
我們看到了刪除空白的情況,之後看看刪除字元的。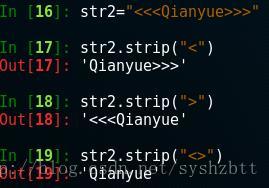
In[19] 顯示了當我們關鍵字是 “<>”的時候,並不是順序匹配 <> 而是刪除了全部的 < 和 > 下面一個例子更明顯。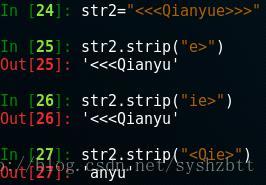
雖然是刪除了前後的字元,但是中間的字元是不會被刪除的。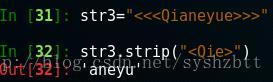
中間的 e 還在。
關鍵字 [not] in 字元物件 #判定是否存在所示關鍵字
從幫助中我們看到 uname.__contains__() 等價於 'Linux' in uname find() 和 index() 判定包含字元的位置 既然可以判定是否包含字元,包含字元的位置是下一個需要知道的。 字元物件.find('關鍵字') 字元物件.index('關鍵字') #查詢關鍵字處於字串的位置 兩個函式都是查詢關鍵字位置的,區別在於返回值不同。 請看例子
在關鍵字能查詢到的情況下 , index() 和 find() 返回值是相同的,但是在找不到的情況下,find()返回-1 而 index() 丟擲一個錯誤。 startswith() 和 endswith() 判定字串是否以特定子串開始或者結束
upper() 和 lower() 忽略大小寫 這兩個方法非常有用,主要用於對兩個字串比較但是不想考慮其大小寫時。 字元物件.upper() 字元物件.lower() 例子:
對於使用者名稱密碼或者驗證碼輸入判定時很有效。 ================================================== 字串的分割 既然可以判定是否包含字元,包含字元的位置是下一個需要知道的。 字元物件[位置1:位置2] #切分字串
日常工作中我們可以依此來擷取個 IP 地址或者log日誌時間什麼的。 還有一種是步長擷取,用的不是很多。中間有2個冒號 [ 1:: 2 ] L i n u x 01 23 4 意思是 從1位開始,每隔2個步長擷取一個字元。答案是 iu split() 根據指定的分隔符對字串提取 這個方法的典型用法是:把希望作為分隔符的字串作為引數傳遞給它。 一般來說分隔符是一個單個字管道符,像 "," " | " 諸如此類。 字元物件.split('分隔符',[應用幾次]) #以指定分隔符分割字串
我們用逗號進行分割,如果第2個引數輸入數字,代表分割次數。 呼叫的話也很簡單。當作列表呼叫。 如果要以行來分割的話。 splitlines() 可以做到按行分割,但是一般來說行處理不用行分割的方法。這裡不贅述了。 ================================================== 字串的刪除 lstrip() rstrip() strip() 刪除空白或字元 這3個方法本來的意思是刪除前導空白 結尾空白 或者 前後空白。但是使用引數刪除任意字元。 lstrip() 刪除前導空白或者字元 rstrip() 刪除結尾空白或者字元 strip() 刪除前後的空白或者字元 注:所有strip() 方法會建立或者返回新的字串物件,不會修改原有物件。 使用方法: 字元物件.strip(['關鍵字']) #刪除空白或者關鍵字
我們看到了刪除空白的情況,之後看看刪除字元的。
In[19] 顯示了當我們關鍵字是 “<>”的時候,並不是順序匹配 <> 而是刪除了全部的 < 和 > 下面一個例子更明顯。
雖然是刪除了前後的字元,但是中間的字元是不會被刪除的。
中間的 e 還在。