
反爬蟲的必要措施!get到了就在也不擔心反爬了!
阿新 • • 發佈:2019-02-01
0×00 前言
0×01 介紹
0×02 問題的分類
0×03 順從的藝術
0×04 反爬蟲
0×05 Anti-Anti-Spider
0×06 爬蟲編寫注意事項
0×07 反饋與問題




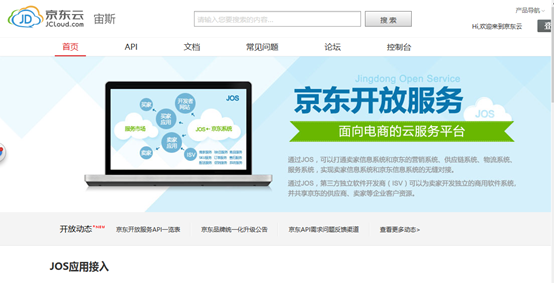
然後我們開啟API頁面的商品API頁面:
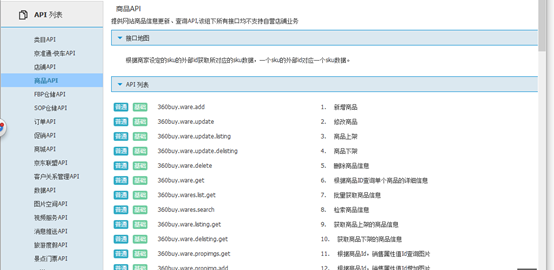
我們發現它提供了不少易用的介面,開發者註冊以後可以使用,或者處理一下丟給爬蟲去使用。同樣的淘寶也有相應的平臺,但是應該是收費的,就是淘寶開放平臺,要在聚石塔呼叫API才會生效:
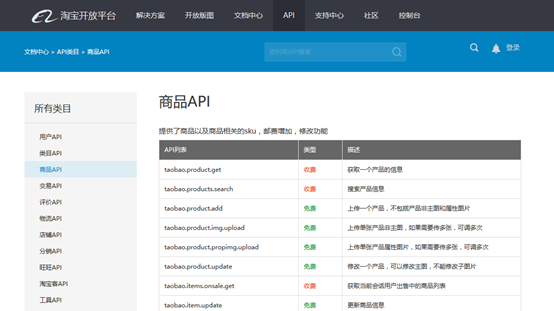


2. User-Agent
User-Agent是使用者訪問網站時候的瀏覽器的標識
下面我列出了常見的幾種正常的系統的User-Agent大家可以參考一下,


3、驗證碼反爬蟲
這個辦法也是相當古老並且相當的有效果,如果一個爬蟲要解釋一個驗證碼中的內容,這在以前通過簡單的影象識別是可以完成的,但是就現在來講,驗證碼的干擾線,噪點都很多,甚至還出現了人類都難以認識的驗證碼(某二三零六)。





接下來我們就討論一些關於反爬蟲反制的措施。其實在這段時間內,我總結出一條用於爬蟲編寫的核心定律:
像一個人一樣瀏覽網頁,像一臺機器一樣分析資料
接下來我們就討論一下在整個一系列文章出現的解決方案能突破幾種限制(Python2):
1. Urllib是最弱的web網頁瀏覽模式,User-Agent,cookie,ip都無法解決;
2. Requests模組與urllib2,urllib3,基本可以解決靜態網頁的所有問題,但是沒辦法解決IP限制,如果需要解決IP限制則需要使用代理,如果需要解決驗證碼問題,則需要自己配置OCR;
3. Selenium+瀏覽器:無法解決驗證碼的問題,效率低,速度慢;
4. Ghost.py無法解決驗證碼問題,效率低,速度慢。


