
劍指Offer——Trie樹(字典樹)
劍指Offer——Trie樹(字典樹)
Trie樹
Trie樹,即字典樹,又稱單詞查詢樹或鍵樹,是一種樹形結構,是一種雜湊樹的變種。典型應用是統計和排序大量的字串(但不僅限於字串),所以經常被搜尋引擎系統用於文字詞頻統計。它的優點是:最大限度地減少無謂的字串比較,查詢效率比雜湊表高。
Trie的核心思想是空間換時間。利用字串的公共字首來降低查詢時間的開銷以達到提高效率的目的。
Trie樹也有它的缺點,Trie樹的記憶體消耗非常大。當然,或許用左兒子右兄弟的方法建樹的話,可能會好點。可見,優化的點存在於建樹過程中。
和二叉查詢樹不同,在trie樹中,每個結點上並非儲存一個元素。trie樹把要查詢的關鍵詞看作一個字元序列,並根據構成關鍵詞字元的先後順序構造用於檢索的樹結構。在
3個基本性質
1.根節點不包含字元,每條邊代表一個字元。
2.從根節點到某一節點,路徑上經過的字元連線起來,為該節點對應的字串。
3.每個節點的所有子節點包含的字元都不相同。
字典樹的構建
題目:給你100000個長度不超過10的單詞。對於每一個單詞,我們要判斷他出沒出現過,如果出現了,求第一次出現在第幾個位置。
分析:這題當然可以用hash來解決,但是本文重點介紹的是trie樹,因為在某些方面它的用途更大。比如說對於某一個單詞,我們要詢問它的字首是否出現過。這樣hash就不好搞了,而用trie還是很簡單。
假設我要查詢的單詞是abcd,那麼在他前面的單詞中,以
好比假設有b,abc,abd,bcd,abcd,efg,hii 這6個單詞,我們構建的樹就是如下圖這樣的(圖片來自百度百科):
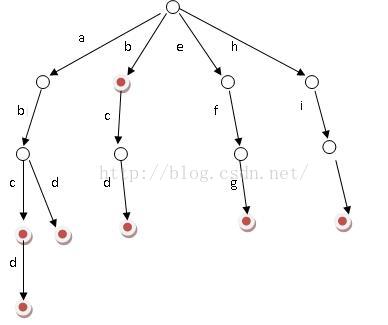
如上圖所示,對於每一個節點,從根遍歷到他的過程就是一個單詞,如果這個節點被標記為紅色,就表示這個單詞存在,否則不存在。
那麼,對於一個單詞,我只要順著他從根走到對應的節點,再看這個節點是否被標記為紅色就可以知道它是否出現過了。把這個節點標記為紅色,就相當於插入了這個單詞。
這樣一來我們查詢和插入可以一起完成(重點體會這個查詢和插入是如何一起完成的,稍後,下文具體解釋)。
我們可以看到,trie樹每一層的節點數是26^i(26個英文字母)級別的。所以為了節省空間,我們用動態連結串列,或者用陣列來模擬。空間的花費,不會超過單詞數×單詞長度。
已知n個由小寫字母構成的平均長度為10的單詞,判斷其中是否存在某個串為另一個串的字首子串。下面對比3種方法:
最容易想到的:1.即從字串集中從頭往後搜,看每個字串是否為字串集中某個字串的字首,複雜度為O(n^2)。
2.使用hash:我們用hash存下所有字串的所有字首子串,建立存有子串hash的複雜度為O(n*len),而查詢的複雜度為O(n)* O(1)= O(n)。
3.使用trie:因為當查詢如字串abc是否為某個字串的字首時,顯然以b,c,d....等不是以a開頭的字串就不用查找了。所以建立trie的複雜度為O(n*len),而建立+查詢在trie中是可以同時執行的,建立的過程也就可以稱為查詢的過程,hash就不能實現這個功能。所以總的複雜度為O(n*len),實際查詢的複雜度也只是O(len)。(說白了,就是Trie樹的平均高度h為len,所以Trie樹的查詢複雜度為O(h)=O(len)。好比一棵二叉平衡樹的高度為logN,則其查詢,插入的平均時間複雜度亦為O(logN))。
查詢
Trie樹是簡單但實用的資料結構,通常用於實現字典查詢。我們做即時響應使用者輸入的AJAX搜尋框時,就是Trie樹。本質上,Trie是一棵儲存多個字串的樹。相鄰節點間的邊代表一個字元,這樣樹的每條分支代表一則子串,而樹的葉節點則代表完整的字串。和普通樹不同的地方是,相同的字串字首共享同一條分支。下面,再舉一個例子。給出一組單詞,inn, int, at, age, adv, ant, 我們可以得到下面的Trie:
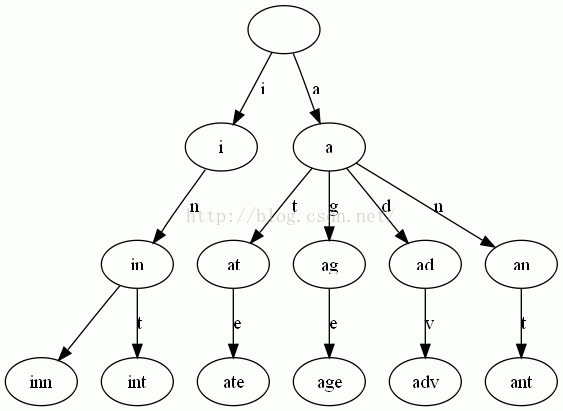
可以看出:
每條邊對應一個字母。
每個節點對應一項字首。葉節點對應最長字首,即單詞本身。
單詞inn與單詞int有共同的字首“in”, 因此他們共享左邊的一條分支,root->i->in。同理,ate, age, adv, 和ant共享字首"a",所以他們共享從根節點到節點"a"的邊。
查詢操縱非常簡單。比如要查詢int,順著路徑i -> in -> int就找到了。
搭建Trie的基本演算法也很簡單,無非是逐一把每個單詞的每個字母插入Trie。插入前先看字首是否存在。如果存在,就共享,否則建立對應的節點和邊。比如要插入單詞add,就有下面幾步:
考察字首"a",發現邊a已經存在。於是順著邊a走到節點a。
考察剩下的字串"dd"的字首"d",發現從節點a出發,已經有邊d存在。於是順著邊d走到節點ad
考察最後一個字元"d",這下從節點ad出發沒有邊d了,於是建立節點ad的子節點add,並把邊ad->add標記為d。
查詢分析
在trie樹中查詢一個關鍵字的時間和樹中包含的結點數無關,而取決於組成關鍵字的字元數。而二叉查詢樹的查詢時間和樹中的結點數有關O(log2n)。
如果要查詢的關鍵字可以分解成字元序列且不是很長,利用trie樹查詢速度優於二叉查詢樹。例如:若關鍵字長度最大是5,則利用trie樹,利用5次比較可以從26^5=11881376個可能的關鍵字中檢索出指定的關鍵字。而利用二叉查詢樹至少要進行次比較。
應用
1. 字串檢索,詞頻統計,搜尋引擎的熱門查詢
事先將已知的一些字串(字典)的有關資訊儲存到trie樹裡,查詢另外一些未知字串是否出現過或者出現頻率。
舉例:
1、有一個1G大小的一個檔案,裡面每一行是一個詞,詞的大小不超過16位元組,記憶體限制大小是1M。返回頻數最高的100個詞。
2、給出N 個單片語成的熟詞表,以及一篇全用小寫英文書寫的文章,請你按最早出現的順序寫出所有不在熟詞表中的生詞。
3、給出一個詞典,其中的單詞為不良單詞。單詞均為小寫字母。再給出一段文字,文字的每一行也由小寫字母構成。判斷文字中是否含有任何不良單詞。例如,若rob是不良單詞,那麼文字problem含有不良單詞。
4、1000萬字符串,其中有些是重複的,需要把重複的全部去掉,保留沒有重複的字串。請怎麼設計和實現?
5、一個文字檔案,大約有一萬行,每行一個詞,要求統計出其中最頻繁出現的前10個詞,請給出思想,給出時間複雜度分析。
6、尋找熱門查詢:搜尋引擎會通過日誌檔案把使用者每次檢索使用的所有檢索串都記錄下來,每個查詢串的長度為1-255位元組。假設目前有一千萬個記錄,這些查詢串的重複讀比較高,雖然總數是1千萬,但是如果去除重複和,不超過3百萬個。一個查詢串的重複度越高,說明查詢它的使用者越多,也就越熱門。請你統計最熱門的10個查詢串,要求使用的記憶體不能超過1G(京東筆試題簡答題與此類似)。
(1) 請描述你解決這個問題的思路;
(2) 請給出主要的處理流程,演算法,以及演算法的複雜度。
2. 字串最長公共字首
Trie樹利用多個字串的公共字首來節省儲存空間,反之,當我們把大量字串儲存到一棵trie樹上時,我們可以快速得到某些字串的公共字首。舉例:
1) 給出N 個小寫英文字母串,以及Q 個詢問,即詢問某兩個串的最長公共字首的長度是多少. 解決方案:
首先對所有的串建立其對應的字母樹。此時發現,對於兩個串的最長公共字首的長度即它們所在結點的公共祖先個數,於是,問題就轉化為了離線(Offline)的最近公共祖先(Least Common Ancestor,簡稱LCA)問題。
而最近公共祖先問題同樣是一個經典問題,可以用下面幾種方法:
1. 利用並查集(Disjoint Set),可以採用經典的Tarjan 演算法;
2. 求出字母樹的尤拉序列(Euler Sequence )後,就可以轉為經典的最小值查詢(Range Minimum Query,簡稱RMQ)問題了;
3. 排序
Trie樹是一棵多叉樹,只要先序遍歷整棵樹,輸出相應的字串便是按字典序排序的結果。
舉例:給你N 個互不相同的僅由一個單詞構成的英文名,讓你將它們按字典序從小到大排序輸出。
4. 作為其他資料結構和演算法的輔助結構
如字尾樹,AC自動機等。
舉例
下面以字典樹的構建與單詞查詢為例。
TrieTreeNode.java
package cn.edu.ujn.trieTree;
public class TrieTreeNode {
int nCount; //記錄該字元出現次數
char ch; //記錄該字元
TrieTreeNode[] child; // 記錄子節點
final int MAX_SIZE = 26;
public TrieTreeNode() {
nCount=1;
child = new TrieTreeNode[MAX_SIZE];
}
}TrieTree.java
package cn.edu.ujn.trieTree;
public class TrieTree {
//字典樹的插入和構建
public void createTrie(TrieTreeNode node,String str){
if (str == null || str.length() == 0) {
return;
}
char[] letters = str.toCharArray();
for (int i = 0; i < letters.length; i++) {
int pos = letters[i] - 'a'; // 用相對於a字母的值作為下標索引,也隱式地記錄了該字母的值
if (node.child[pos] == null) {
node.child[pos] = new TrieTreeNode();
}else {
node.child[pos].nCount++;
}
node.ch = letters[i];
node = node.child[pos];
}
}
//字典樹的查詢
public int findCount(TrieTreeNode node,String str){
if (str == null || str.length() == 0) {
return -1;
}
char[] letters = str.toCharArray();
for (int i = 0; i < letters.length; i++) {
int pos = letters[i] - 'a';
if (node.child[pos] == null) {
return 0;
}else {
node = node.child[pos];
}
}
return node.nCount;
}
}Test.java
package cn.edu.ujn.trieTree;
public class Test {
public static void main(String[] args) {
/**
* Problem Description 老師交給他很多單詞(只有小寫字母組成,不會有重複的單詞出現),現在老師要他統計
* 出以某個字串為字首的單詞數量(單詞本身也是自己的字首).
*/
String[] strs = { "banana", "band", "bee", "absolute", "acm" };
String[] prefix = { "ba", "b", "band", "abc" };
TrieTree tree = new TrieTree();
TrieTreeNode root = new TrieTreeNode();
for (String s : strs) {
tree.createTrie(root, s);
}
// tree.printAllWords();
for (String pre : prefix) {
int num = tree.findCount(root, pre);
System.out.println(pre + " " + num);
}
}
}小結
看過上面的程式碼,是否發現這個程式碼有什麼問題呢?儘管這個實現方式查詢的效率很高,時間複雜度是O(m),m是要查詢的單詞中包含的字母的個數。但是確浪費大量存放空指標的儲存空間。因為不可能每個節點的子節點都包含26個字母的。所以對於這個問題,字典樹存在的意義是解決快速搜尋的問題,所以採取以空間換時間的作法也毋庸置疑。
Trie樹佔用記憶體較大,例如:處理最大長度為20、全部為小寫字母的一組字串,則可能需要 2620 個節點來儲存資料。而這樣的樹實際上稀疏的十分厲害,可以採用左兒子右兄弟的方式來改善,也可以採用需要多少子節點則新增多少子節點來解決(不要類似網上的示例,每個節點初始化時就申請一個長度為26的陣列)。
Wiki上提到了採用三陣列Trie(Tripple-Array Trie)和二陣列Trie(Double-Array Trie)來解決該問題,此外還有壓縮等方式來緩解該問題。
示例優化
TrieTreeNode.java
package cn.edu.ujn.trieTreeMap;
import java.util.HashMap;
import java.util.Map;
public class TrieNode {
int nCount; //記錄該字元出現次數
Map<Character, TrieNode> childdren; // 記錄子節點
public TrieNode() {
nCount = 1;
childdren = new HashMap<Character, TrieNode>();
}
}TrieTree.java
package cn.edu.ujn.trieTreeMap;
// 利用Map動態建立節點
public class TrieTree {
// 字典樹的插入和構建
public void insert(TrieNode node, String word) {
for (int i = 0; i < word.length(); i++) {
Character c = new Character(word.charAt(i));
if (!node.childdren.containsKey(c)) {
node.childdren.put(c, new TrieNode());
}else{
node.childdren.get(c).nCount++;
}
node = node.childdren.get(c);
}
}
// 字典樹的查詢
public int search(TrieNode node, String word) {
for (int i = 0; i < word.length(); i++) {
Character c = new Character(word.charAt(i));
if (!node.childdren.containsKey(c)) {
return 0;
}
node = node.childdren.get(c);
}
return node.nCount;
}
}Test.java
package cn.edu.ujn.trieTreeMap;
public class Test {
public static void main(String[] args) {
/**
* Problem Description 老師交給他很多單詞(只有小寫字母組成,不會有重複的單詞出現),現在老師要他統計
* 出以某個字串為字首的單詞數量(單詞本身也是自己的字首).
*/
String[] strs = { "banana", "band", "bee", "absolute", "acm" };
String[] prefix = { "ba", "b", "band", "abc" };
TrieTree tree = new TrieTree();
TrieNode node = new TrieNode();
for (String s : strs) {
tree.insert(node, s);
}
// tree.printAllWords();
for (String pre : prefix) {
int num = tree.search(node, pre);
System.out.println(pre + " " + num);
}
}
}計算結果如下:

經過以上方法的改進,可避免冗餘節點的存在。將字典樹的優勢進一步放大。當然,也可以使用左兒子右兄弟的形式建立字典樹。此方法後續介紹~
檔案讀入
package cn.edu.ujn.trieTreeMap;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
public class Test {
public static void main(String[] args) {
/**
* Problem Description 老師交給他很多單詞(只有小寫字母組成,不會有重複的單詞出現),現在老師要他統計
* 出以某個字串為字首的單詞數量(單詞本身也是自己的字首).
*/
String[] strs = { "banana", "band", "bee", "absolute", "acm" };
String[] prefix = { "網易", "軟體", "band", "abc" };
TrieTree tree = new TrieTree();
TrieNode node = new TrieNode();
BufferedReader br = null;
try {
File file= new File("C://Users//SHQ//Desktop//Offer.txt");
//讀取語料庫words.txt
br = new BufferedReader(new InputStreamReader(new FileInputStream(file.getAbsolutePath()),"GBK"));
String word="";
while ((word = br.readLine()) != null) {
tree.insert(node, word);
}
}catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
/*for (String s : strs) {
tree.insert(node, s);
}*/
// tree.printAllWords();
for (String pre : prefix) {
int num = tree.search(node, pre);
System.out.println(pre + " " + num);
}
}
}計算結果如下:

Offer.txt文字內容如下:

可知計算結果正確。而且出現了中文字元,對於數字的操作同理。而利用第一種方法就無法實現固定分配記憶體。只能使用動態分配機制。
美文美圖


