
京東2019校招筆試題-演算法工程師 選擇題知識點彙總
剛剛結束了京東的筆試,發現很多知識點都不太瞭解,所以在這篇文章做一個彙總學習。
目錄
1 哈夫曼樹
給定n個權值作為n個葉子結點,構造一棵二叉樹,若該樹的帶權路徑長度達到最小,稱這樣的二叉樹為最優二叉樹,也稱為哈夫曼樹(Huffman Tree)。哈夫曼樹是帶權路徑長度最短的樹,權值較大的結點離根較近。
參考百度百科
題目考察的要點是如何計算哈夫曼樹的帶權路徑長度。
1)路徑長度:一個結點到另一個結點的分支數目。如下圖所示(根節點到D之間的路徑長度為4):
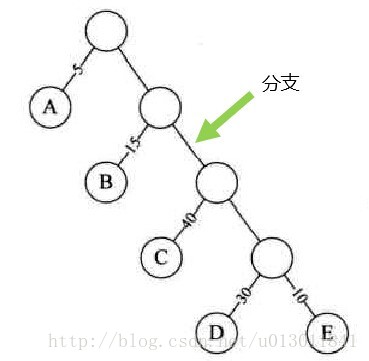
2)樹的路徑長度:根節點到每一個結點的路徑長度之和。如下圖所示(樹的路徑長度為1+2+3+4+1+2+3+4 = 20):
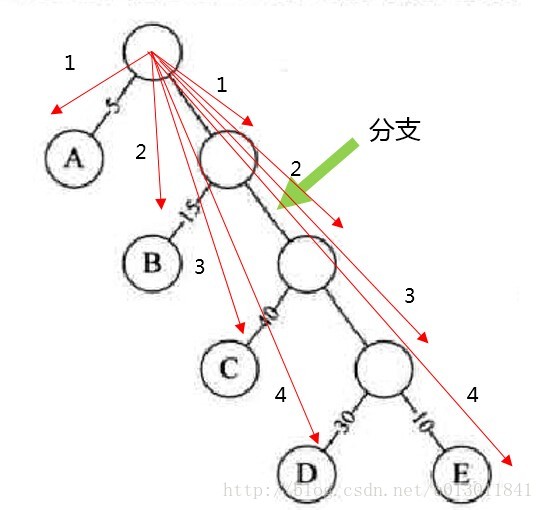
3)帶權路徑長度:上圖所示的例子中,帶權路徑的長度為5*1+15*2+40*3+30*4+10*4=315
4)哈夫曼樹:帶權路徑長度最小的二叉樹。
5)構造哈夫曼樹
1、根據給定的n個權值{w[1],w[2],…,w[n]}構成n棵二叉樹的集合F={T[1],T[2],…T[n]},其中每棵二叉樹T[i];中只有一個帶權為w[i]的根結點,其左右子樹均為空。
2、在F中選取兩棵根結點的權值最小的樹作為左右子樹構造一棵新的二叉樹,且置新的二叉樹的根結點的權值為其左右子樹上根結點的權值之和。
3、在F中刪除這兩棵樹,同時將新得到的二義樹加入F中。
4重複2和3步驟,直到F只含一棵樹為止。這棵樹便是哈夫曼樹。
用畫圖表示上面的步驟:
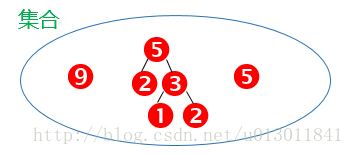
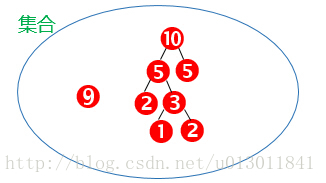
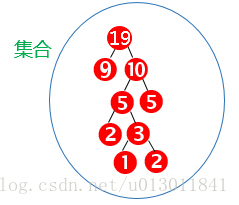
結果為:
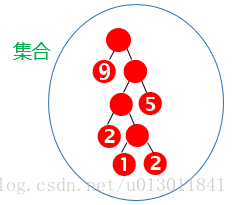
2 迴圈連結串列
參考內容為維基百科。
連結串列的種類包括:
1)單向連結串列:(又名單鏈表、線性連結串列)是連結串列的一種,其特點是連結串列的連結方向是單向的,對連結串列的訪問要通過從頭部開始,依序往下讀取。

它的結構可以分為資料域和指標域,資料域儲存資料,指標域指向下一個儲存節點的地址。
2)雙向連結串列:也叫雙鏈表,它的每個資料結點中都有兩個指標,分別指向直接後繼和直接前驅。所以,從雙向連結串列中的任意一個結點開始,都可以很方便地訪問它的前驅結點和後繼結點。
3)迴圈連結串列:一種鏈式儲存結構,它的最後一個結點指向頭結點,形成一個環。因此,從迴圈連結串列中的任何一個結點出發都能找到任何其他結點。
更詳細的線性表(順序儲存+鏈式儲存結構)可以參考這篇文章,此處不再贅述。
3 堆
3.1 大頂堆、小頂堆
堆可以看做一個滿足特殊條件的完全二叉樹。它滿足雙親結點大於等於孩子結點(大頂堆),或者雙親結點小於等於孩子結點(小頂堆)。
- 父節點i的左子節點在位置
;
- 父節點i的右子節點在位置
;
- 子節點i的父節點在位置
;

二叉樹的相關內容可以參考這篇文章,此處不再贅述。
3.2 堆排序
大頂堆產生順序序列,小頂堆產生生逆序序列。此處以大頂堆為例進行說明。
1)將初始待排序關鍵字序列(R[1],R[2]....R[n])構建成大頂堆,此堆為初始的無序區;
2)將堆頂元素R[1]與最後一個元素R[n]交換,此時得到新的無序區(R[1],R[2],......R[n-1])和新的有序區(R[n]),且滿足R[1,2...n-1]<=R[n];
3)由於交換後新的堆頂R[1]可能違反堆的性質,因此需要對當前無序區(R[1],R[2],......R[n-1])調整為新堆,然後再次將R[1]與無序區最後一個元素交換,得到新的無序區(R[1],R[2]....R[n-2])和新的有序區(R[n-1],R[n])。不斷重複此過程直到有序區的元素個數為n-1,則整個排序過程完成。
接下來以陣列{16,7,3,20,17,8}為例,解釋上面的步驟:
①由無序陣列建立與其等價的完全二叉樹

②構造初始堆(每次調整都是從父節點、左子節點、右子節點三者中選擇最大者跟父節點進行交換)

此時由於16與20的交換,我們需要繼續比較、交換16及其子節點,然後得到初始堆:

③構建無序區和有序區
初始堆的R[1]一定是最大的,所以我們首先把它和最後一位R[n-1]交換。此時無序區為R[1, 2…n-1],有序區為R[n]:

此時3(父節點)不再是父節點、左子節點、右子節點中最大的了,所以3和17交換:


此時3作為父節點還是比它的子節點要小,我們進一步讓它與16交換:

然後我們就可以讓17與3交換,使得17進入有序區:

接下來就是不斷重複③中的上述步驟,使得無序區結點不斷減少,有序區則不斷增加,直到有序區有n-1個結點:


最後一次交換後,排序結束:

3.3 堆排序時間複雜度分析
為了從R[1...n]中選擇最大記錄,需比較n-1次,然後從R[1...n-2]中選擇最大記錄需比較n-2次。事實上這n-2次比較中有很多已經在前面的n-1次比較中已經做過,而樹形選擇排序恰好利用樹形的特點儲存了部分前面的比較結果,因此可以減少比較次數。對於n個關鍵字序列,最壞情況下每個節點需比較log2(n)次,因此其最壞情況下時間複雜度為nlogn。堆排序為不穩定排序,不適合記錄較少的排序。
4 唯一確定二叉樹
京東的原題有點類似牛客網上的這道題:

答案選AC,原因是:
前序(先序):根左右
中序: 左根右
後序: 左右根
一定要有中序,這樣才能區分左右子樹,否則得到的是左右子樹的混合。
5 SQL繫結變數
5.1 動態&靜態SQL
語句中主變數的個數與資料型別在預編譯時都是確定的,我們稱這類嵌入式SQL語句為靜態SQL語句。反之則為動態SQL。他們的區別為:
靜態sql的執行計劃(DB2稱存取路徑)是在執行前就確定好的。
動態sql的執行計劃(DB2稱存取路徑)是在執行時動態生成的。由於是在執行時動態生成執行計劃,因此生成的執行計劃(DB2稱存取路徑)相對更優,但考慮到生成執行計劃(DB2稱存取路徑)的開銷,有可能應用程式的執行時間相對會比靜態sql長些 。
5.2 繫結變數
感覺百度百科說的挺好的,也包含例子:

6 遞迴和遞推的區別
從理論上說,所有的遞迴函式都可以轉換為迭代函式,反之亦然,然而代價通常都是比較高的。當遞迴次數較多時,記憶體佔用也會隨之增加。
遞推與遞迴:
1,從程式上看,遞迴表現為自己呼叫自己,遞推則沒有這樣的形式。
2,遞迴是從問題的最終目標出發,逐漸將複雜問題化為簡單問題,最終求得問題
是逆向的。遞推是從簡單問題出發,一步步的向前發展,最終求得問題。是正向的。
3,遞迴中,問題的n要求是計算之前就知道的,而遞推可以在計算中確定,不要求計算前就知道n。
4,一般來說,遞推的效率高於遞迴(當然是遞推可以計算的情況下)
作者:kickers18
連結:https://www.zhihu.com/question/20651054/answer/260181892
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
7 Python中range&xrange的區別
xrange用法與range完全相同,所不同的是生成的不是一個數組,而是一個生成器。
要生成很大的數字序列的時候,用xrange會比range效能優很多,因為不需要一上來就開闢一塊很大的記憶體空間。
8 隱含狄利克雷分佈(LDA)
參考維基百科LDA詞條。