
Carte+kettle+mysql效能問題定位分析記錄
通過Carte服務對kettle轉換進行壓力測試,以20併發為基準,通過不斷的優化,對比測試結果如下:
| 20併發測試結果(持續7分鐘) | 無Redis | 加Redis | 優化Carte記憶體 使用配置 |
加CPU和記憶體 (壓15小時) |
| Total Throughput (bytes) 總吞吐量 |
5,079,582 | 111,814,589 | 703,321,332 | |
| Average Throughput (bytes/second) 吞吐率 |
11,624 | 264,963 | 1,798,776 | |
| Total Hits 總點選量 | 1,458 | 7,245 | 17,615 | |
| Average Hits per Second 點選率 | 3.336 | 17.168 | 45.051 | |
| Average Response Time 平均響應時間 |
22.608秒 | 4.366秒 | 1.645秒 | 1.378秒 |
| 90 Percent Response Time 90%請求響應時間 |
35.614秒 | 22.959秒 | 3.828秒 | 2.351秒 |
| executeTrans Transaction Pass 交換事務處理量(事務吞吐量) |
290 | 1449 | 3523 | |
| Carte伺服器平均CPU使用率 | 5.7% (Carte引數優化前為90%) |
10~30% | 85%~90% (壓力過大) |
45%~70% |
| Carte伺服器記憶體使用率 | 70~80% (飽和) |
70~80% (飽和) |
70~80% (飽和) | 50%~60% |
|
MySql 平均CPU使用率 |
60% (MySql快取優化前為100%) |
40% | 2% (MySql無壓力) |
2% |
以上測試結果包括的具體優化過程有:Mysql開啟查詢快取、Carte日誌快取時間配置、加Redes、優化Carte記憶體使用配置(將max_log_timeout_minutes和Object_timeout_minutes都縮小配置為1分鐘)、加CPU和加記憶體、優化配置JVM配置調優(根據記憶體大小重新將spoon.sh檔案中的JVM堆記憶體引數-Xms -Xmx優化設定)。
確認優化結果有效後(能夠穩定執行15小時),再以20併發進行更長時間穩定性測試,持續壓力測試到20天后出現崩潰,由於崩潰的時間點和引起崩潰原因一時難以定位,重新改變壓力測試的策略(測試前開發人員再做一些優化,主要是解除和排除日誌中出現的一些異常錯誤,如轉換過程丟擲的異常;並同時開啟轉換使用唯一連線
測試指令碼日夜不間斷跑測,到第二天早上看監控結果,就發現系統真的崩潰了。
一、通過Loadrunner能夠看到執行13個小時後出現異常崩潰
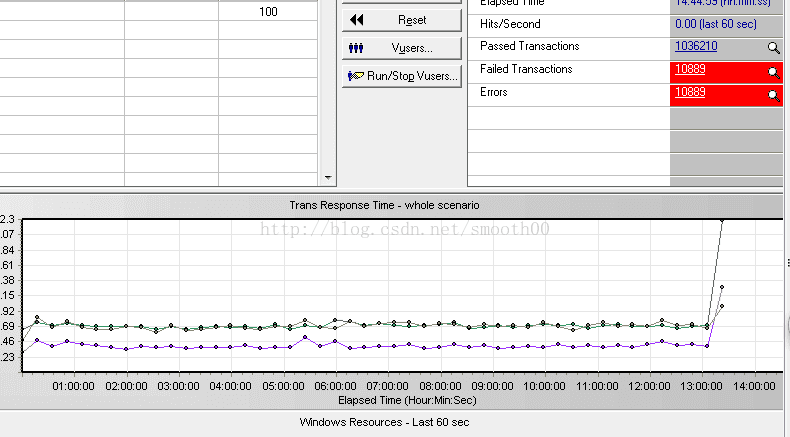
二、通過Carte服務的CPU監控,能夠看到早上7點鐘前出現壓力突然上升,並且無法降低
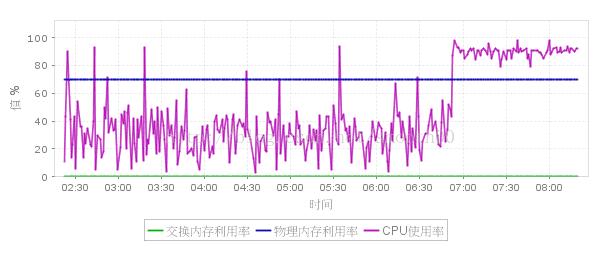
三、獲取JVM監控的歷史報告(JVM監控已異常斷開連線),從連線時間、執行緒數、堆記憶體(無法回收記憶體)的變化情況,也能看出7點左右出現反常情況
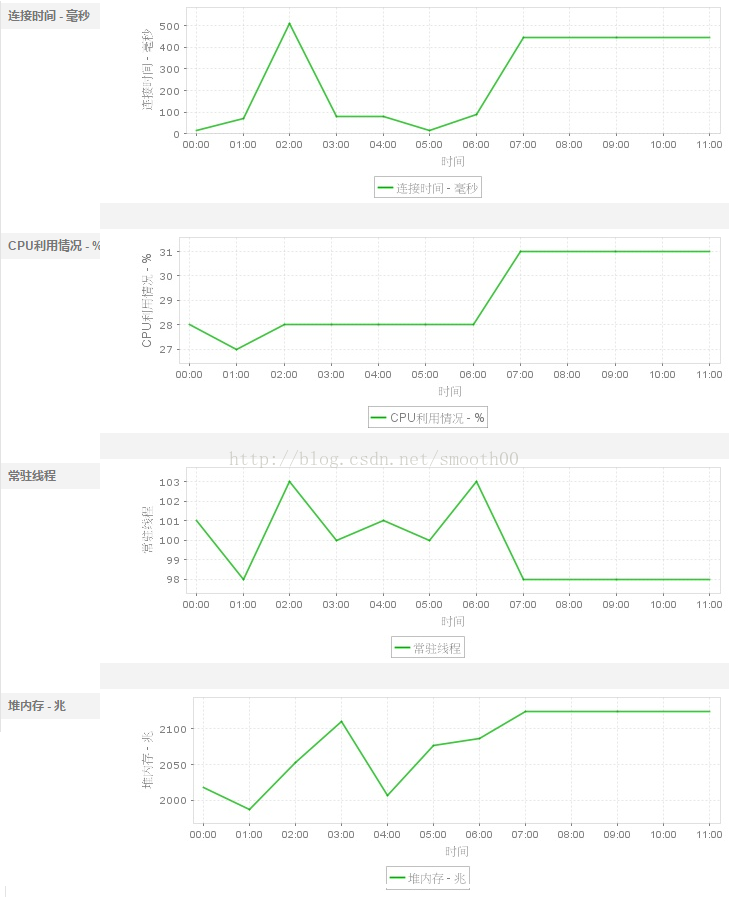
四、通過監控MySQL(有兩個mysql,一個是資源庫,一切正常,一個是交換庫出現異常),發現7點左右出現大量斷開的連線
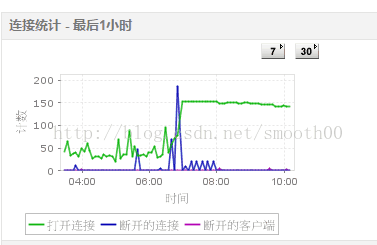
五、對交換庫的監控,發現快到7點時,壓力突然降低,這與上面的異常相符合
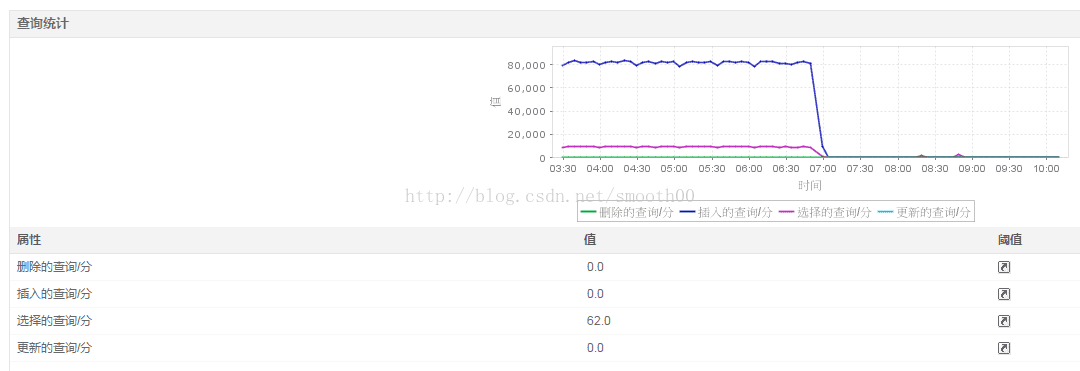
六、日誌定位問題
通過上面的監控,可以判斷,系統在7點前15分鐘左右,應該出現故障,這就需要通過日誌定位這個時段,以找到具體原因
最後在Carte服務的日誌中找到答案,第一次出現連線錯誤的時間點是06:44:50.273,報的是Too many connections
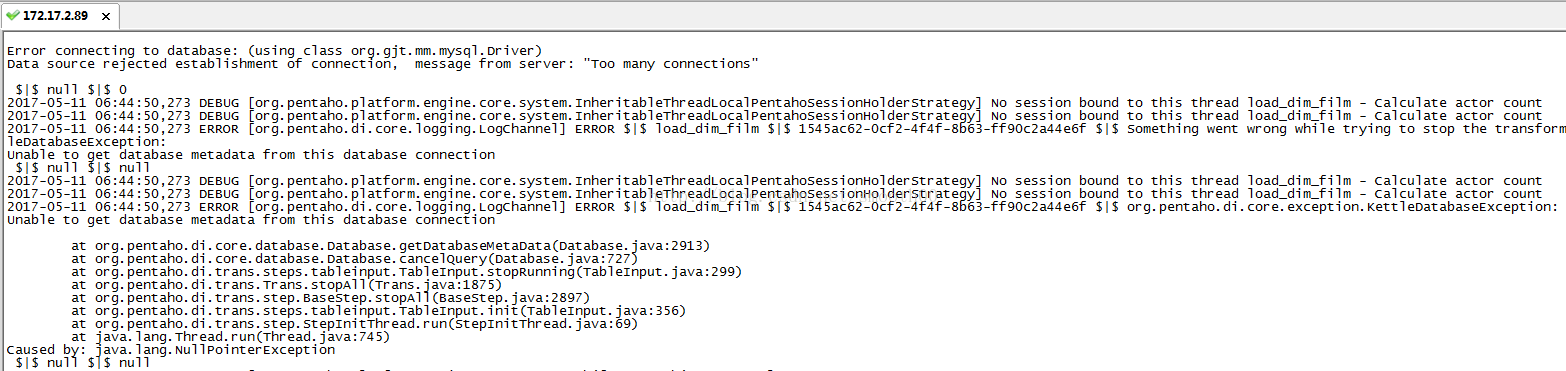
然後錯誤越來越頻繁,最後導致 jvm記憶體溢位而崩潰,
從上面日誌能明顯看到導致jvm效率下降和記憶體問題的一個間接原因是 轉換步驟中對轉換資料庫的連線異常:Error connecting to database: (using class org.gjt.mm.mysql.Driver)
Data source rejected establishment of connection, message from server: "Too many connections " Error...........
大量異常需要消耗效率和記憶體,所以之前併發數是20的時候,這個效率下降是緩慢的,現在換成100併發就很快出現問題了。所以即使carte不崩潰,轉換也已經不能正常執行,因為db的瓶頸,轉換中的sql指令碼以及表輸入或表輸出等操作已經不能連線db 。 七、優化資料連線
1、開啟kettle轉換的資料庫連線池
對每個測試的轉換,將其DB連線全都勾選“使用連線池” (初始大小5,最大25) 。
2、加大MySQL最大連線數,由預設100改為1000(max_connections)
再次測試,這時候壓了15分鐘就崩潰,通過日誌檢視,發現不存在資料庫數異常的問題了,而且通過監控發現數據庫連線正常,達到最大併發連線後沒有出現中斷連線
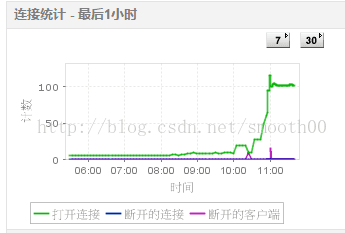
但是這次出現了新的現象,通過JVM監控發現有2千多個活動執行緒(正常峰值也就兩百多),包括轉換的執行緒(大部分處於監視狀態)。
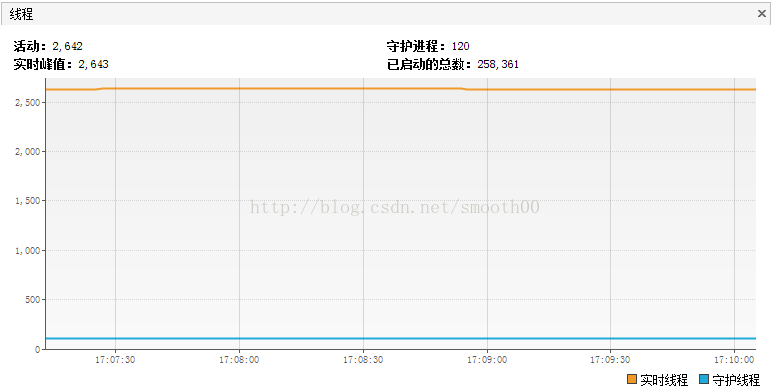
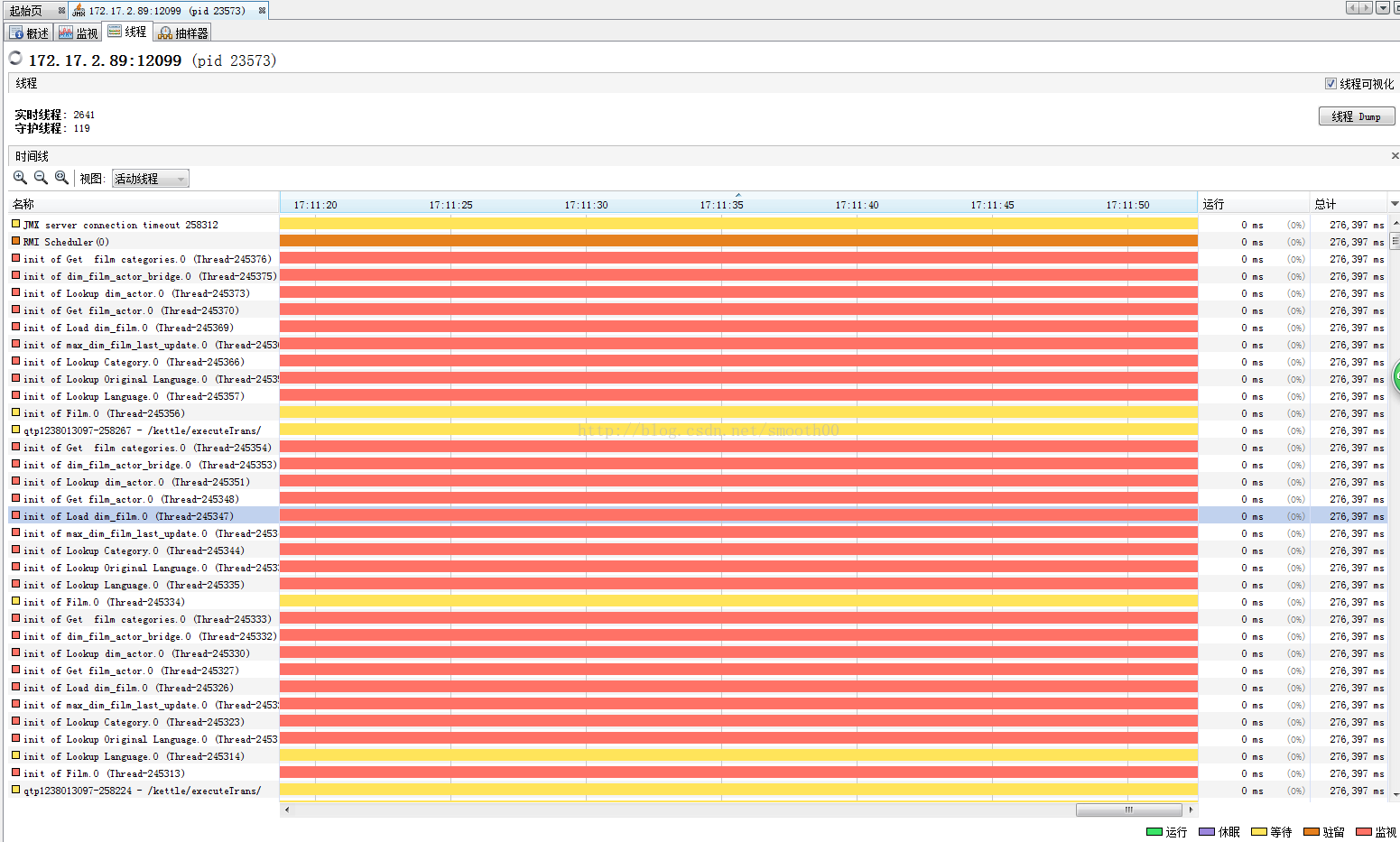
補充說明:關於五種狀態的執行緒說明
執行(Running):我們最喜歡的狀態。說明該執行緒正在執行程式碼,沒有問題。
休眠(Sleeping):呼叫了Thread.sleep後的狀態,說明執行緒正停在某個Thread.sleep處
等待(Wait):手動呼叫了wait方法,或者某些IO操作,在阻塞中等待資料。
駐留(Resident):常駐執行緒,相當於守護執行緒。
監視(Monitor):這裡就是我想找的問題了。它表示執行緒想執行一段synchronized中的程式碼,但是發現已經有其它執行緒正在執行,自己被block了,只能無奈地等待。如果這種狀態多,說明程式需要好好優化。
重現一下測試過程,發現到崩潰前,執行緒活動數突然間大量增長,如下所示:
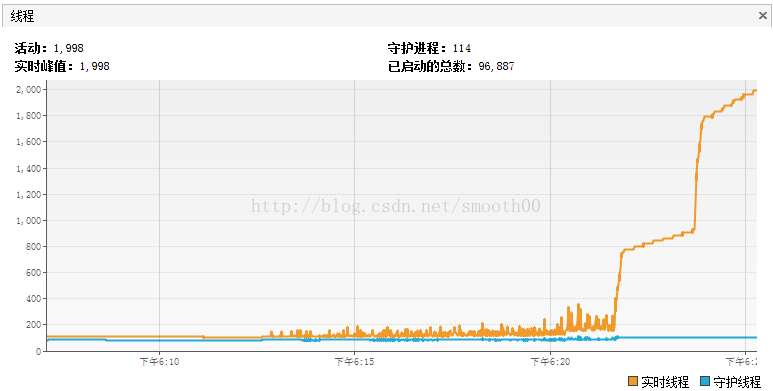
通過threaddump分析,發現jetty 服務出現問題,有大量的執行緒死鎖,經過開發人員的分析,是因為連線池出現大量爭用,最後導致死鎖,如下:
"qtp1238013097-258267 - /kettle/executeTrans/" - Thread [email protected]
java.lang.Thread.State: WAITING
at java.lang.Object.wait(Native Method)
- waiting on <50979aad> (a java.lang.Thread)
at java.lang.Thread.join(Thread.java:1245)
at java.lang.Thread.join(Thread.java:1319)
at org.pentaho.di.trans.Trans.prepareExecution(Trans.java:1075)
at org.pentaho.di.www.ExecuteTransServlet.executeTrans(ExecuteTransServlet.java:447)
at org.pentaho.di.www.ExecuteTransServlet.doGet(ExecuteTransServlet.java:354)
at org.pentaho.di.www.BaseHttpServlet.doPost(BaseHttpServlet.java:103)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:595)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:668)
at org.eclipse.jetty.servlet.ServletHolder.handle(ServletHolder.java:684)
at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:503)
at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:229)
at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1086)
at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:429)
at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:193)
at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1020)
at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:135)
at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:255)
at org.eclipse.jetty.server.handler.HandlerList.handle(HandlerList.java:52)
at org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:522)
at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:116)
at org.eclipse.jetty.server.Server.handle(Server.java:366)
at org.eclipse.jetty.server.AbstractHttpConnection.handleRequest(AbstractHttpConnection.java:494)
at org.eclipse.jetty.server.AbstractHttpConnection.content(AbstractHttpConnection.java:982)
at org.eclipse.jetty.server.AbstractHttpConnection$RequestHandler.content(AbstractHttpConnection.java:1043)
at org.eclipse.jetty.http.HttpParser.parseNext(HttpParser.java:865)
at org.eclipse.jetty.http.HttpParser.parseAvailable(HttpParser.java:240)
at org.eclipse.jetty.server.AsyncHttpConnection.handle(AsyncHttpConnection.java:82)
at org.eclipse.jetty.io.nio.SelectChannelEndPoint.handle(SelectChannelEndPoint.java:696)
at org.eclipse.jetty.io.nio.SelectChannelEndPoint$1.run(SelectChannelEndPoint.java:53)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:608)
at org.eclipse.jetty.util.thread.QueuedThreadPool$3.run(QueuedThreadPool.java:543)
at java.lang.Thread.run(Thread.java:745)
Locked ownable synchronizers:
- None
"init of Get film categories.0 (Thread-245354)" - Thread [email protected]
java.lang.Thread.State: BLOCKED
at org.pentaho.di.trans.steps.databasejoin.DatabaseJoin.init(DatabaseJoin.java:216)
- waiting to lock <376dc4ad> (a org.pentaho.di.trans.Trans) owned by "init of Film.0 (Thread-245334)" [email protected]
at org.pentaho.di.trans.step.StepInitThread.run(StepInitThread.java:69)
at java.lang.Thread.run(Thread.java:745)
Locked ownable synchronizers:
- None
"init of dim_film_actor_bridge.0 (Thread-245353)" - Thread [email protected]
java.lang.Thread.State: BLOCKED
at org.pentaho.di.trans.steps.insertupdate.InsertUpdate.init(InsertUpdate.java:476)
- waiting to lock <376dc4ad> (a org.pentaho.di.trans.Trans) owned by "init of Film.0 (Thread-245334)" [email protected]
at org.pentaho.di.trans.step.StepInitThread.run(StepInitThread.java:69)
at java.lang.Thread.run(Thread.java:745)
Locked ownable synchronizers:
- None
"init of Lookup dim_actor.0 (Thread-245351)" - Thread [email protected]
java.lang.Thread.State: BLOCKED
at org.pentaho.di.trans.steps.databaselookup.DatabaseLookup.connectDatabase(DatabaseLookup.java:637)
- waiting to lock <376dc4ad> (a org.pentaho.di.trans.Trans) owned by "init of Film.0 (Thread-245334)" [email protected]
at org.pentaho.di.trans.steps.databaselookup.DatabaseLookup.init(DatabaseLookup.java:577)
at org.pentaho.di.trans.step.StepInitThread.run(StepInitThread.java:69)
at java.lang.Thread.run(Thread.java:745)
Locked ownable synchronizers:
- None
"init of Get film_actor.0 (Thread-245348)" - Thread [email protected]
java.lang.Thread.State: BLOCKED
at org.pentaho.di.trans.steps.databasejoin.DatabaseJoin.init(DatabaseJoin.java:216)
- waiting to lock <376dc4ad> (a org.pentaho.di.trans.Trans) owned by "init of Film.0 (Thread-245334)" [email protected]
at org.pentaho.di.trans.step.StepInitThread.run(StepInitThread.java:69)
at java.lang.Thread.run(Thread.java:745)
Locked ownable synchronizers:
- None猜測可能是由於轉換勾選了“使用唯一連線”
開發給的解釋為:這個問題是由於死鎖造成的,jetty執行緒的鎖是表面現象,實際是轉換步驟執行緒死鎖,每個轉換使用唯一連線的情況下,當每個轉換的步驟往下進行時,不斷索取連線資源。如果有時刻T剛好所有轉換都在進行,並且剛好每個轉換下面還有步驟需要獲取連線,(這種情況不難出現),執行緒X佔用連線B,但索要連線A, 執行緒Y佔用連線A, 但要連線B,(可以想象多個執行緒是互相交叉的)就會等待對方執行緒釋放資源,就出現死鎖狀態,jetty伺服器於是出現阻塞。
如果轉換中出現連線兩個資料庫時,還需要研究一下怎麼才能使得資源最大化。
這個問題必須後續分析和解決(這也說明前面的優化跟最後的開啟連線池優化存在衝突),這個問題留到下週來進行驗證。
八、優化失敗回滾部分設定
按照上週開發的解釋,將轉換中的“使用唯一連線”勾選去掉,再次執行100併發,這次發現不到100使用者時(大概80多併發時)點選率就直線下降,到100併發時直接崩潰,效能比上週的結果還差。對比了一下使用唯一連線和不使用唯一連線的執行緒數分佈情況如下:

圖8.1 轉換使用唯一連線後測試崩潰統計的執行緒數
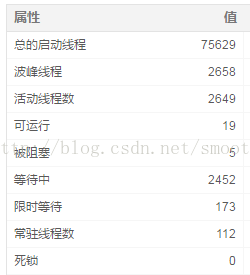
圖8.2 轉換不使用唯一連線後測試崩潰統計的執行緒數
可以發現使用唯一連線後匯流排程要多的多(因為執行的時間比後者長),而且大部分的活動執行緒是被阻塞的,這與不使用唯一連線的測試結果不一樣(不使用唯一連線後大部分的活動程序 處在等待中,極少部分是被阻塞,而且系統只運行了8分鐘後就崩潰了,這比前者還早了7分鐘,可以看出不勾選“使用唯一連線”效果更差)。
這也說明在當前配置情況下,轉換中勾選唯一連線和不勾選唯一連線的結果都一樣會讓系統很快崩潰,實質上會有些差別(執行緒狀態數分佈不同),但這已不重要了,重要的是步驟七針對資料連線的優化是無效的,並帶來了副作用,繼續優化下去可能進入死衚衕,因此需要進行測試回滾(回到第七步、優化資料連線),將優化資料連線的策略做一下更改,改為只加大MySQL最大連線數(設為1500),不再開啟轉換的連線池(完全依靠mysql自身的連線控制策略),同時保留轉換使用唯一連線(好處是一個轉換過程只開啟一個連線,避免轉換中的每個步驟都開啟連線,會導致過快的消耗DB連線數)。
然後進行100併發執行測試,目前執行良好(各項指標正常,carte伺服器的CPU 30%左右,記憶體 69%左右;交換庫CPU 16%~75%,記憶體 21%),需要繼續觀察(計劃執行30天)。從目前JVM執行情況來看,比較穩定:
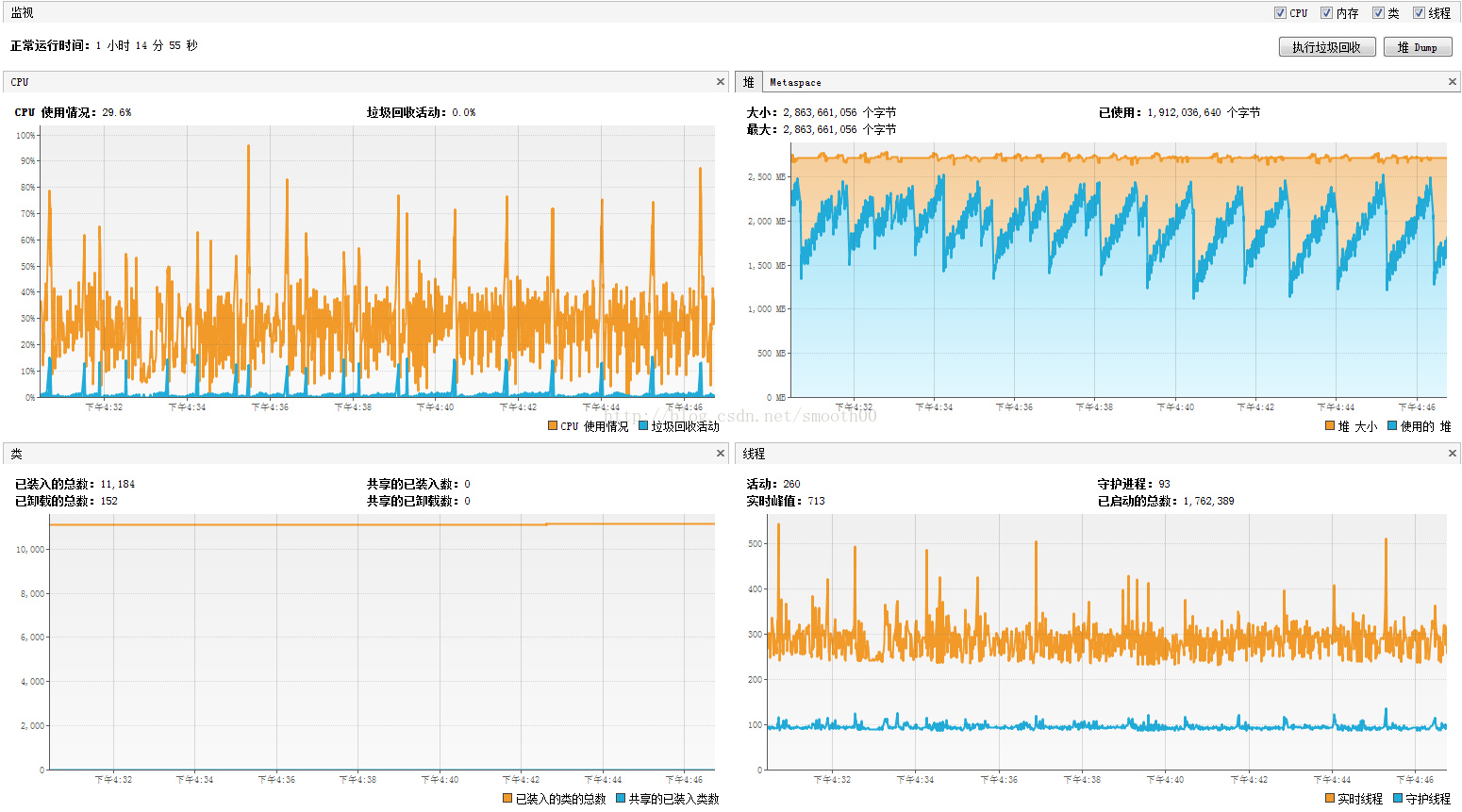
另外我們可能也需要換個思路來提升該資料交換平臺的穩定性和效能了,留待後續思考。
九、分析網路穩定性問題
經過以上有效調優後,系統執行一個晚上,發現Loadrunner還是報出了少量錯誤(No Route to Host):
Action.c(22): Error -27796: Failed to connect to server "172.17.2.89:8081": [10065] No Route to Host cartekettle Action 22 2017/6/3 2:21:01 3493 CarteKettle_2:310 localhost
猜測可能是跟網路延遲有關,通過優化連線數,加大Carte的連線超時時間,以及將loadrunner的超時錯誤時間放大,都無法避免這個錯誤。只能通過監控客戶端與服務端的ping丟包情況(通過統制ping.vbs 指令碼,以cscript ping.vbs 172.17.2.89 -t -l 1000 -w 5000>ping89.txt輸出ping錯誤日誌),結果發現真是由網路中斷引起的,說明測試環境的網路是不穩定的。
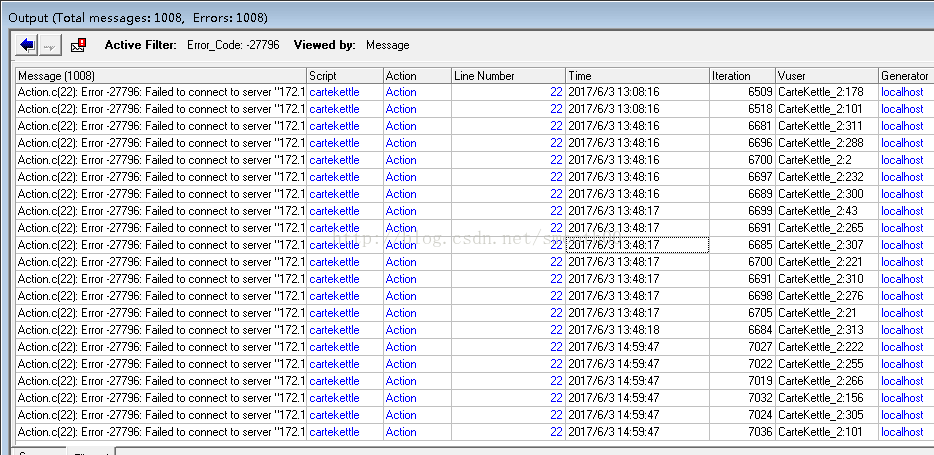
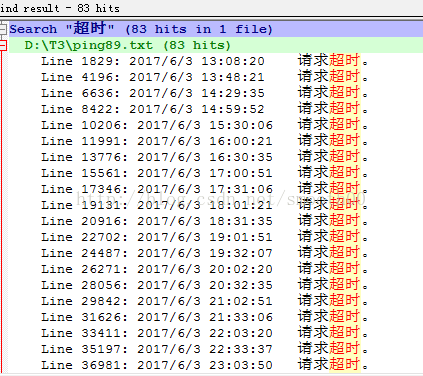
說明在網路穩定性方面,需要做好重連線,這得由呼叫carte服務的客戶端來決定,之後這塊邏輯可能需要在排程上去考慮。
十、後續思考:
由於本次測試過程,已經對mysql進行了優化(加了redis快取,提升了讀寫速度,減少了IO操作),同時對carte和kettle也進行了JVM配置調優,修改carte配置檔案(將max_log_timeout_minutes和Object_timeout_minutes配置為最小值,及時回收記憶體,減少記憶體溢位的概率),同時對轉換也進行了優化(使用唯一連線,減少轉換中多步驟的DB連線資源佔用)。但這些手段雖然提升了當前資料交換系統的效能和穩定性,但面對DB本身的瓶頸還是需要後續進一步的優化和效能提升。
下一步就要考慮mysql的叢集化部署,包括通過mycat叢集(提升mysql的高可用+讀寫分離)應用,並且在業務層面上,適當的開展分表分庫以減輕mysql的單節點壓力,具體對於mycat的配置和測試參見另一篇文章:http://blog.csdn.net/smooth00/article/details/71082046
接著就是要考慮部署Carte服務叢集,進一步提升資料交換平臺的高可用和高穩定性,以滿足長時間的穩定執行和資料的大批量實時交換要求。
相關推薦
Carte+kettle+mysql效能問題定位分析記錄
通過Carte服務對kettle轉換進行壓力測試,以20併發為基準,通過不斷的優化,對比測試結果如下: 20併發測試結果(持續7分鐘) 無Redis 加Redis 優化Carte記憶體 使用配置 加CPU和記憶體 (壓15小時) Total Throughput (byte
MySQL效能測試分析
測試環境 作業系統:Linux AS release 4,核心2.6.9-42.ELsmp #1 SMP CPU:Intel(R) Xeon(TM) CPU 3.00GHz,4核 記憶體:1G,主要執行MySQL服務 硬碟:cciss 37G 檔案系統:ext3,支援大檔案
mysql資料庫如何定位分析哪些sql語句查詢比較慢
查詢執行語句比較慢的設定方法: show full processlist; show variables like '%query%'; //檢視query相關的引數設定 set global long_query_time = 2; &nbs
MySQL Insert語句單個批次數量過多導致的CPU效能問題分析
【問題】 最近有臺伺服器比較頻繁的CPU報警,表現的特徵有CPU sys佔比偏高,大量慢查詢,大量併發執行緒堆積。後面開發對insert的相關業務限流後,伺服器效能恢復正常。 【異常期間執行緒處理情況】 下圖是當時生產環境異常時抓取的資訊,該事務正在執行insert,已經執行5秒,執行緒
Android 效能分析記錄
TraceView介面資訊介紹。 TraceView介面包括時間面板和方法面板 (1) 時間面板(Timeline Panel)時間面板展示了每個執行緒的執行情況,其中的[1]main即為ui主執行緒。移動到某個位置可以檢視該點對應的方法的執行資訊,點選方法面板則會選中相應的方法。可以左鍵按
MySQL效能分析和優化-part 1
MySQL效能優化 平時我們在使用MySQL的時候,怎麼評估系統的執行狀態,怎麼快速定位系統瓶頸,又如何快速解決問題呢? 本文總結了多年來MySQL優化的經驗,系統介紹MySQL優化的方法。 OS效能分析 使用top觀察top cpu/memory程序 使用mpstat觀察每
MySQL效能分析之Profile
在MySQL資料庫中,可以通過配置profiling引數來啟用SQL剖析。該引數開啟後,後續執行的SQL語句都將記錄其資源開銷,諸如IO,上下文切換,CPU,Memory等,根據這些開銷分析當前SQL瓶頸從而進行優化與調整。 MySQL版本 mysql> show vari
關聯與下鑽:快速定位MySQL效能瓶頸的制勝手段
本文根據DBAplus社群〖2018年1月6日北京開源與架構技術沙龍〗現場演講內容整理而成。 講師介紹 李季鵬 新炬網路資料庫專家 專注於MySQL資料庫效能管理及相關解決方案,目前主要從事
mysql效能分析利器 EXPALIN
在SQL語句之前加上EXPLAIN關鍵字就可以獲取這條SQL語句執行的計劃 那麼返回的這些欄位是什麼呢? 我們先關心一下比較重要的幾個欄位: 1. select_type 查詢型別 1)simple 簡單查詢,沒有UNION和子查詢 2)priamry 主查詢,有UNION或子查詢的最外層查詢
mysql的sql語句的效能診斷分析
1> explain SQL,類似於Oracle中explain語句 例如:explain select * from nad_aditem; 2> select benchmark(count,sql);計算sql語句執行count次所花費的時間 例如: mysql> se
效能調優之MySQL篇三:MySQL配置定位以及優化
1、優化方式 一般的優化方法有:硬體優化,配置優化,sql優化,表結構優化。下面僅僅介紹配置優化,具體優化設定可以參考本人另外一篇部落格,傳送門:https://www.cnblogs.com/langhuagungun/p/9507206.html 2、mysql配置分析 1)常見瓶頸 90%系統瓶
效能調優之MySQL篇四:MySQL配置定位以及優化
一、CPU最大效能模式 cpu利用特點 5.1 最高可用4個核 5.5 最高可用24核 5.6 最高可用64核心 一次query對應一個邏輯CPU 你仔細檢查的話,有些伺服器上會有的一個有趣的現象:你cat /proc/cpuinfo時,會發現CPU的頻率竟然跟它標
MySQL伺服器SSD效能問題分析與測試
【問題】 我們有臺HP的伺服器,SSD在寫IOPS約5000時,%util達到80%以上,那麼這塊SSD的效能究竟有沒有問題,為解決這個問題做了下面測試。 【工具】 blktrace是linux下用來排查IO效能的工具。它可以記錄IO經歷的各個步驟,並計算出IO請求在各個階段的消耗,下面是關鍵的一些
MySQL 快速定位效能問題
一、效能檢視幾款小工具: Top 檢視:觀察 load average :1分鐘,5分鐘,15分鐘的平均負載值 1. us% 使用者使用的 CPU 佔比,如果 us% 太高, 極有可能索引使用不當。 2. sy% 系統核心使用的
mysql 效能分析Explain使用
mysql 效能分析Explain使用1 說明 介紹 能幹嘛 如何使用 包含資訊 id select_type table type possible_keys key
MySQL效能瓶頸排查定位
排查過程收到線上某業務後端的MySQL例項負載比較高的告警資訊,於是登入伺服器檢查確認。1. 首先我們進行OS層面的檢查確認登入伺服器後,我們的目的是首先要確認當前到底是哪些程序引起的負載高,以及這些程序卡在什麼地方,瓶頸是什麼。通常來說,伺服器上最容易成為瓶頸的是磁碟I/O
MYSQL——效能瓶頸定位
查詢與索引優化分析 在優化MySQL時,通常需要對資料庫進行分析,常見的分析手段有慢查詢日誌,EXPLAIN 分析查詢,profiling分析以及show命令查詢系統狀態及系統變數,通過定位分析效能的
mysql效能分析show profile/show profiles
MySQL效能分析show profiles show profile 和 show profiles 語句可以展示當前會話(退出session後,profiling重置為0) 中執行語句的資源使用情況。 Profiling 功能由MySQL會話變數 : profiling控制,預設是OFF.關
MySQL慢查詢日誌記錄和分析
一、引言 在日常的開發中,有時候會收到使用者或者產品經理反饋說網站的響應速度有點慢,即使是管理系統頁面也會出現這種情況。導致網頁響應速度慢的原因有很多,比如:資料表的某些欄位沒有建立索引,或者說是建立了索引,但索引失效,又或者說肯能因為最近來了一個新人同事,把某一條的SQL語句寫的執
MySQL效能調優——鎖定機制與鎖優化分析
——針對多執行緒的併發訪問,任何一個數據庫都有其鎖定機制,它的優劣直接關係著資料的一致完整性與資料庫系統的高併發處理效能。鎖定機制也因此成了各種資料庫的核心技術之一。不同資料庫儲存引擎的鎖定機制是不同