
[WebKit] JavaScriptCore解析--基礎篇(二)直譯器基礎與JSC核心元件
這一篇主要說明直譯器的基本工作過程和JSC的核心元件的實現。
作為一個語言,就像人在的平時交流時一樣,當接收到資訊後,包含兩個過程:先理解再行動。理解的過程就是語言解析的過程,行動就是根據解析的結果執行對應的行為。在計算機領域,理解就是編譯或解釋,這個已經被研究的很透徹了,並且有了工具來輔助。而執行則千變萬化,也是效能優化的重心。下面就來看看JSC是如何來理解、執行JavaScript指令碼的。
直譯器工作過程
JavaScriptCore基本的工作過程如下:
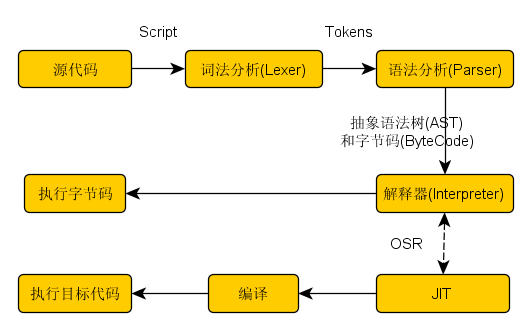
對於一個直譯器,首先必須要明確所支援的語言, JSC所支援的是。
詞法分析和語法分析就是理解的過程,將輸入的文字轉為一種它可以理解的語義形式(抽象語法樹), 或者更進一步的生成供後續使用的中間程式碼(位元組碼,ByteCode)。
直譯器就是負責執行解析輸出的結果。正因為執行是優化的重心,所以有JIT來提高執行效能。根據資料,V8還會優化Parser的輸出,省去了bytecode, 當直譯器有能力直接基於AST執行。
詞法分析及語法分析,最著名的工具就是lex/yacc,以及後繼者flex/bison()。它們為很多軟體提供了語言或文字解析的功能,相當強大,也很有趣。雖然JavaScriptCore並沒有使用它們,而是自行編寫實現的,但基本思路是相似的。
詞法分析(lexer),其實就是一個掃描器,依據語言的定義,提取出原始檔中的內容變為一個個語法可以識別的token,比如關鍵字,操作符,常量等。在一個檔案中定義好規則就可以了。
語法分析(paser), 它的功能就是根據語法(token的順序組合),識別出不同的語義(目標操作)。
比如:
i=3;
經過lexer可能被識別為以下的tokens:
VARIABLE EQUAL CONSTANT END
經過parser一分析,就瞭解這是一個"賦值操作,向變數i賦值常量3"。隨後再呼叫對應的操作加以執行。
如果你對lexer和parser還不太熟悉,可參考的資料很多,這裡有一個基本的入門指引:。
關於直譯器和JIT的說明在第3節。
執行的基礎環境(Register-based VM)
JSC解析生成的程式碼放到一個虛擬機器上來執行(廣義上講JSC主身就是一個虛擬機器)。JSC使用的是一個基於暫存器的虛擬機器(register-based VM),另一種實現方式是基於棧的虛擬機器(stack-based VM)。兩者的差異可以簡單的理解為指令集傳遞引數的方式,是使用暫存器,還是使用棧。
相對於基於棧的虛擬機器,因為不需要頻繁的壓、出棧,以及對三元操作的支援,register-based VM的效率更高,但可移植性相對弱一些。
所謂的三元操作符,其中add就是一個三元操作,
add dst, src1, src2
功能是將src1與src2相加,將結果儲存在dst中。dst, src1,src2都是暫存器。
為了方便和<<深入理解Java虛擬機器>>中的示例進行對比,也利用JSC輸出以下指令碼的ByteCode如下:
[ 0] enter
[ 1] mov r0, Cell: 0133FC40(@k0)
[ 4] put_by_id r0, a(@id0), Int32: 100(@k1)
[ 13] mov r0, Cell: 0133FC40(@k0)
[ 16] put_by_id r0, b(@id1), Int32: 200(@k2)
[ 25] mov r0, Cell: 0133FC40(@k0)
[ 28] put_by_id r0, c(@id2), Int32: 300(@k3)
[ 37] resolve_global r0, a(@id0)
[ 43] resolve_global r1, b(@id1)
[ 49] add r0, r0, r1
[ 54] resolve_global r1, c(@id2)
[ 60] mul r0, r0, r1
[ 65] ret r0*參考: (WebKit沒有及時更新,只做為參考,最新的內容還是要看程式碼.)
而基於棧的虛擬機器的生成的位元組碼如下:
0: bipush 100
2: istore_1
3: sipush 200
6: istore_2
7: sipush 300
10: istore_3
11: iload_1
12: iload_2
13: iadd
14: iload_3
15: imul
16: ireturn可以幫助理解它們之間的差異。
核心元件
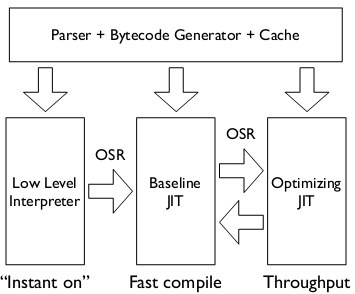
JavaScriptCore 是一個正在演進的虛擬機器(virtual machine), 包含了以下模組: lexer, parser, start-up interpreter (LLInt), baseline JIT, and an optimizing JIT (DFG).
Lexer 負責詞法解析(, 就是將指令碼分解為一系列的tokens. JavaScriptCore的 lexer是手動撰寫的,大部分程式碼在parser/Lexer.h 和 parser/Lexer.cpp 中.
Parser 處理語法分析(), 也就是基於來自Lexer的tokens建立語法樹(syntax tree). JavaScriptCore 使用的是一個手動編寫的遞迴下降解析器(recursive descent parser), 程式碼位於parser/JSParser.h 和 parser/JSParser.cpp .
LLInt, 全稱為Low Level Interpreter, 負責執行由Paser生成的位元組碼(bytecodes). 程式碼在llint/ 目錄裡, 使用一個可移植的彙編實現,也被為offlineasm (程式碼在offlineasm/目錄下), 它可以編譯為x86和ARMv7的彙編以及C程式碼。LLInt除了詞法解析和語法解釋外,JIT編譯器所執行的呼叫、棧、以及暫存器轉換都是基本沒有啟動開銷(start-up cost)的。比如,呼叫一個LLInt函式就和呼叫一個已經被編譯原始程式碼的函式相似, 除非機器碼的入口正是一個共用的LLInt Prologue(公共函式頭,shared LLInt prologue). LLInt還包括了一些優化,比如使用inline cacheing來加速屬性訪問.
Baseline JIT 在函式被呼叫了6次,或者某段程式碼迴圈了100次後(也可能是一些組合,比如3次帶有50次列舉的呼叫)就會觸發Baseline JIT。這些數字只是大概的估計,實際上的啟發(heuristics)過程是依賴於函式大小和當時記憶體狀況的。當JIT卡在一個迴圈時,它會執行On-Stack-Replace(OSR)將函式的所有呼叫者重新指向新的編譯程式碼。Baseline JIT同時也是函式進一步優化的後備,如果無法優化程式碼時,它還會通過OSR調整到Baseline JIT. BaseLine JIT的程式碼在 jit/ . 基線JIT也為inline caching執行幾乎所有的堆訪問。
無論是LLInt和Baseline JIT者會收集一些輕量級的效能資訊,以便擇機到更高一層級(DFG)執行。收集的資訊包括最近從引數、堆,以及返回值中的資料。另外,所有inline caching也做了些處理,以方便DFG進行型別判斷,例如,通過查詢inline cache的狀態,可以檢測到使用特定類理進行堆訪問的頻率。這個可以用於決定是否進入DFG (文中稱這個行為叫speculation, 有點賭一把的意思,能優化獲得更高的效能最好,不然就退回來)。在下一節中著重講述JavaScriptCore型別推斷。
DFG JIT 在函式被呼叫了至少60次,或者程式碼迴圈了1000次,就會觸發DFG JIT。同樣,這些都是近似數,整個過程也是趨向於啟發式的。DFG積極地基於前面(baseline JIT&Interpreter)收集的資料進行型別推測,這樣就可以儘早獲得型別資訊(forward-propagate type information),從而減少了大量的型別檢查。DFG也會自行進行推測,比如為了啟用inlining, 可能會將從heap中載入的內容識別出一個已知的函式物件。如果推測失敗,DFG取消優化(Deoptimization),也稱為"OSR exit". Deoptimization可能是同步的(某個型別檢測分支正在執行),也可能是非同步的(比如runtime觀察到某個值變化了,並且與DFG的假設是衝突的),後者也被稱為"watchpointing"。 Baseline JIT和DFG JIT共用一個雙向的OSR:Baseline可以在一個函式被頻繁呼叫時OSR進入DFG, 而DFG則會在deoptimization時OSR回到Baseline JIT. 反覆的OSR退出(OSR exits)還有一個統計功能: DFG OSR退出會像記錄發生頻率一樣記錄下退出的理由(比如對值的型別推測失敗), 如果退出一定次數後,就會引發重新優化(reoptimization), 函式的呼叫者會重新被定位到Baseline JIT,然後會收集更多的統計資訊,也許根據需要再次呼叫DFG。重新優化使用了指數式的回退策略(exponential back-off,會越來越來)來應對一些奇葩程式碼。DFG程式碼在dfg/.
任何時候,函式, eval程式碼塊,以及全域性程式碼(global code)都可能會由LLInt, Baseline JIT和DFG三者同時執行。一個極端的例子是遞迴函式,因為有多個stack frames,就可能一個執行在LLInt下,另一個執行在Baseline JIT裡,其它的可能正執行在DFG裡。更為極端的情況是當重新優化在執行過程被觸發時,就會出現一個stack frame正在執行原來舊的DFG編譯,而另一個則正執行新的DFG編譯。為此三者設計成維護相同的執行語義(execution semantics), 它們的混合使用也是為了帶來明顯的效能提升。
*如果想要觀察它們的工作,可以在WebKit中的子工程jsc的jsc.cpp中,使用JSC::Options新增一部分log輸出.
參考閱讀:
系列索引: