
Hbase Shell API與過濾器實踐
(一)Hbase Shell
1、hbase提供了一個shell的終端給使用者互動
#$HBASE_HOME/bin/hbase shell

2、如果退出執行quit命令
>quit
3、檢視資料庫狀態(status)

– 表示有3臺機器活著,0臺機器down掉,當前負載0.67(數字越大,負載越大)
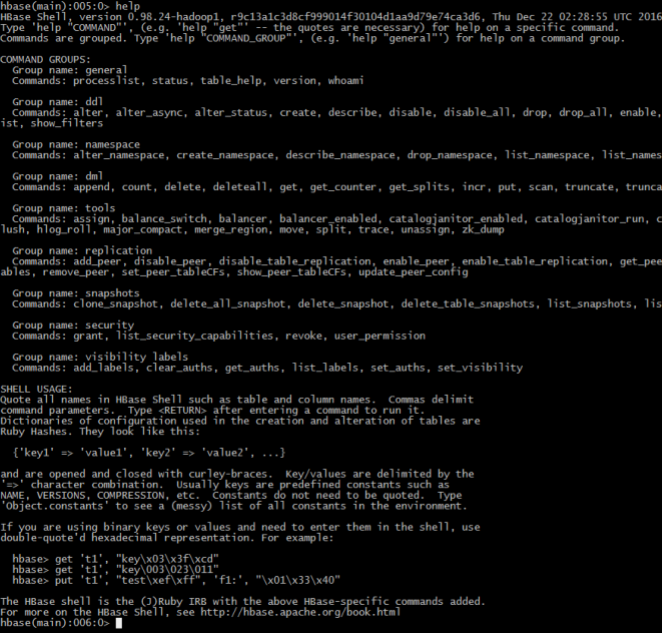
4、執行help查詢幫助
– General:普通命令組– Ddl:資料定義語言命令組
– Dml:資料操作語言命令組
– Tools:工具組
– Replication:複製命令組
– SHELL USAGE:shell語法
5、 命令create / list / describe
– 表名:music_table
– 列簇1:meta_data
– 列簇2: 'action

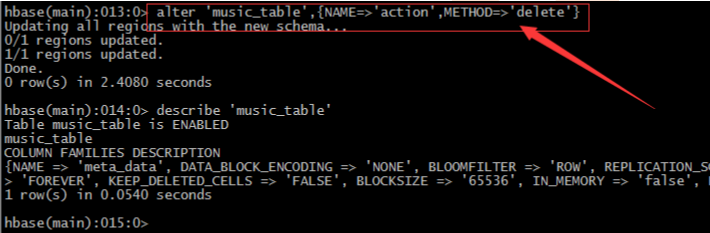
6、命令alter / disable / enable
– 凡是要修改表的結構hbase規定,必須先禁用表->修改表->啟用表 直接修改會報錯– 刪除表中的列簇:alter 'music_table',{NAME=>'action',METHOD=>'delete'}
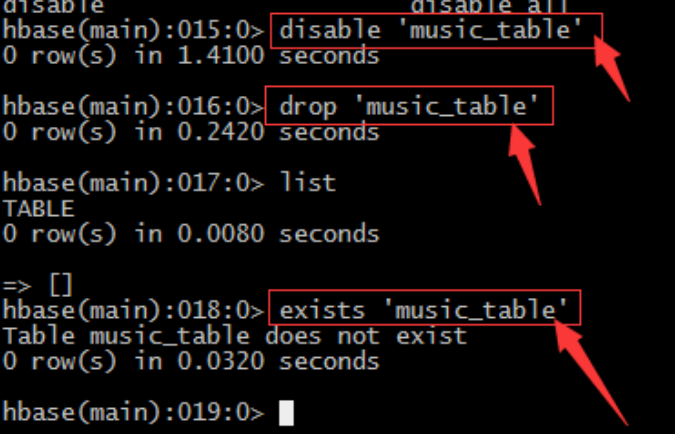
7、命令drop / exists
– 同樣對錶進行任何的操作都需要先禁用表->修改->啟用表,刪除同樣– 禁用表: disable 'music_table‘
– 刪除表:drop 'music_table‘
– 利用list或exists命令判斷表是否存在
8、命令is_enabled
– 判斷表是否enable或者disable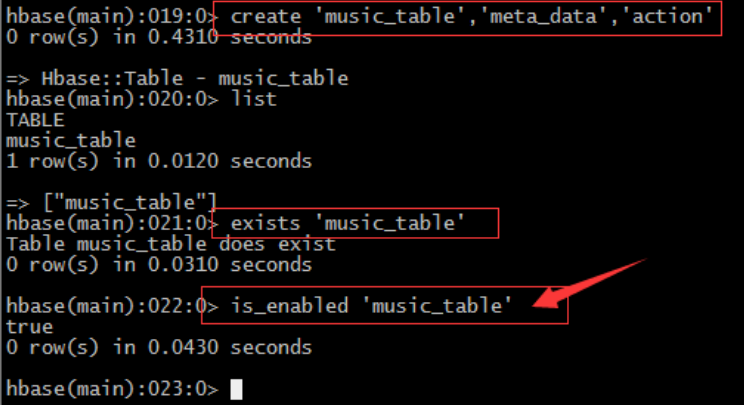
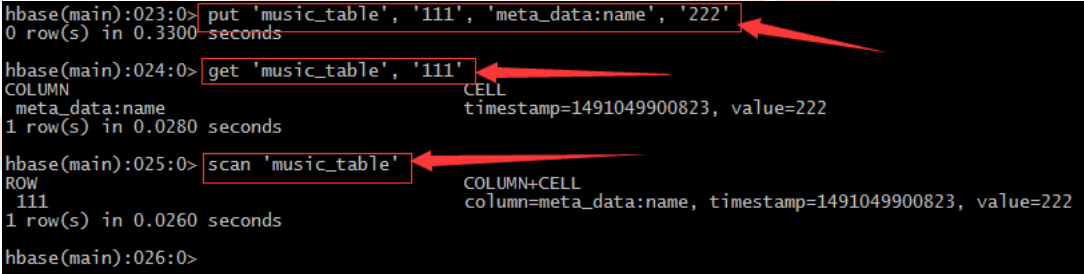
9、 插入命令put
– 對於hbase來說insert update其實沒有什麼區別,都是插入原理– 在hbase中沒有資料型別概念,都是“字元型別”,至於含義在程式中體現
– 每插入一條記錄都會自動建立一個時間戳,由系統自動生成。也可手動“強行指定”

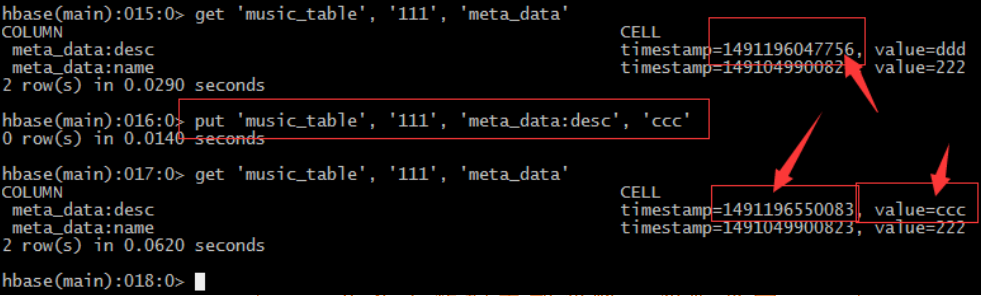
• 指定版本
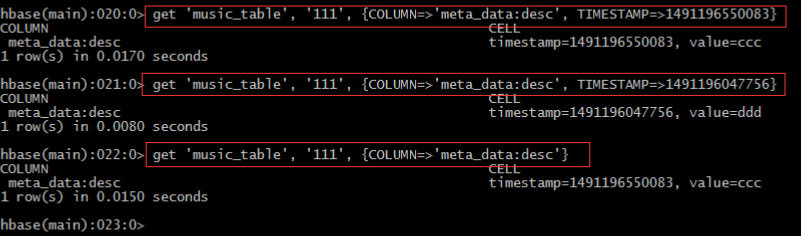
• 修改版本儲存個數:
– alter 'music_table',{NAME=>'meta_data', VERSIONS=>3}

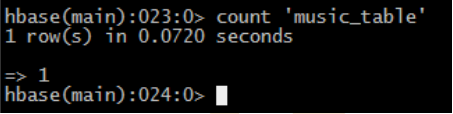
• 檢視有多少條記錄count
– count 'music_table'
• 刪除delete
– 刪除指定列簇
– 刪除整行

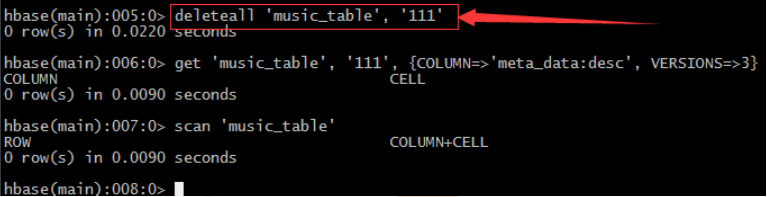
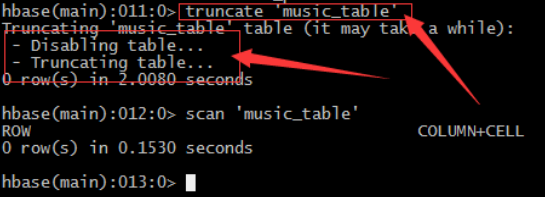
• 截斷表truncate
– 注意:truncate表的處理過程:由於Hadoop的HDFS檔案系統不允許直接修改,所以只能先刪除表在重新建立已達到清空表的目的
• Split
– 手動
• split 'music_table', 'bc31bc83af45aab95d5d8a62962b23f5'
– 建表時預設
• create 'test_table', 'f1', SPLITS=> ['a', 'b', 'c']
• Compact
– merge_region '759a217c34ad5203801866dab4b6b209','939affd918502d5e46792367a0a4a59a', true
– major_compact 'music_table'
名稱 | 命令表示式 |
建立表 | create '表名', '列族名1','列族名2','列族名N' |
檢視所有表 | list |
描述表 | describe ‘表名’ |
判斷表存在 | exists '表名' |
判斷是否禁用啟用表 | is_enabled '表名' is_disabled ‘表名’ |
新增記錄 | put ‘表名’, ‘rowKey’, ‘列族 : 列‘ , '值' |
檢視記錄rowkey下的所有資料 | get '表名' , 'rowKey' |
查看錶中的記錄總數 | count '表名' |
獲取某個列族 | get '表名','rowkey','列族' |
獲取某個列族的某個列 | get '表名','rowkey','列族:列’ |
刪除記錄 | delete ‘表名’ ,‘行名’ , ‘列族:列' |
刪除整行 | deleteall '表名','rowkey' |
刪除一張表 | 先要遮蔽該表,才能對該表進行刪除 第一步 disable ‘表名’ ,第二步 drop '表名' |
清空表 | truncate '表名' |
檢視所有記錄 | scan "表名" |
檢視某個表某個列中所有資料 | scan "表名" , {COLUMNS=>'列族名:列名'} |
更新記錄 | 就是重寫一遍,進行覆蓋,hbase沒有修改,都是追加 |
依賴zookeeper
1、 儲存Hmaster的地址和backup-master地址hmaster:
a) 管理HregionServer
b) 做增刪改查表的節點
c) 管理HregionServer中的表分配
2、 儲存表-ROOT-的地址
hbase預設的根表,檢索表。
3、 HRegionServer列表
表的增刪改查資料。
和hdfs互動,存取資料。
(二)Hbase的Python操
• 安裝Thrift:
– ]# wget http://archive.apache.org/dist/thrift/0.8.0/thrift-0.8.0.tar.gz
– ]# tar xzf thrift-0.8.0.tar.gz
– ]# yum install automake libtool flex bison pkgconfig gcc-c++ boost-devel libevent-devel zlib-devel python-devel ruby-devel openssl-devel
– ]# yum install boost-devel.x86_64
– ]# yum install libevent-devel.x86_64– [[email protected] thrift-0.8.0]# pwd
– /home/badou/hbase_test/thrift-0.8.0
– ]# ./configure --with-cpp=no --with-ruby=no
– ]# make
– ]# make install– 下載hbase原始碼:
– ]# wget http://mirrors.hust.edu.cn/apache/hbase/0.98.24/hbase-0.98.24-src.tar.gz
– [[email protected] hbase-0.98.24]# find . -name Hbase.thrift
– ./hbase-thrift/src/main/resources/org/apache/hadoop/hbase/thrift/Hbase.thrift
– [[email protected] hbase-0.98.24]# cd ./hbase-
thrift/src/main/resources/org/apache/hadoop/hbase/thrift
– ]# thrift -gen py Hbase.thrift
– ]# cp -raf gen-py/hbase/ /home/badou/hbase_test– ]# hbase-daemon.sh start thrift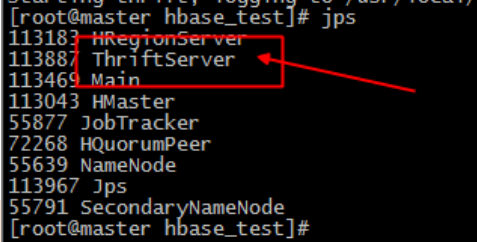
• 例項1:建立表
• 例項2:插入資料
• 例項3:讀取指定row key記錄
• 例項4:讀取多條記錄
• Hive讀取HBase表,通過MR,最終使用HiveHBaseTableInputFormat來讀取數據,在getSplit()方法中對 HBase表進行切分,切分原則是根據該表對應的HRegion,將每一個Region作為一個InputSplit,即,該表有多少個Region,就有多少個Map Task;
• 每個Region的大小由引數hbase.hregion.max.filesize控制,預設10G,這樣會使得每個map task處理的資料檔案太大,map task效能自然很差;
• 為HBase表預分配Region,使得每個Region的大小在合理的範圍;
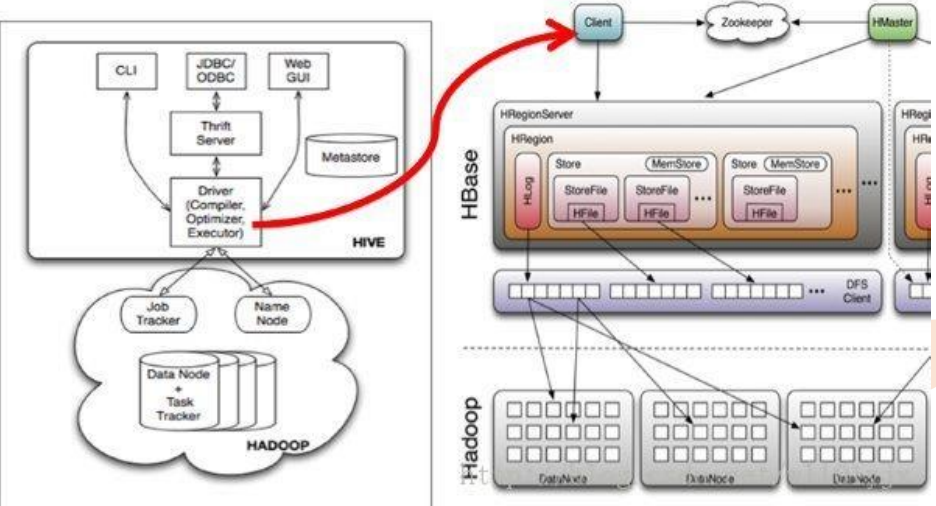
• 建立Hbase表:
– create 'classes','user'
• 加入資料:
– put 'classes','001','user:name','jack'
– put 'classes','001','user:age','20'
– put 'classes','002','user:name','liza'
– put 'classes','002','user:age','18'
• 建立Hive表並驗證:
– create external table classes(id int, name string, age int)
– STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
– WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,user:name,user:age")
– TBLPROPERTIES("hbase.table.name" = "classes");
• 再新增資料到Hbase:
– put 'classes','003','user:age','1820183291839132'
(三)MapReduce操作Hbase
1、實現方法
Hbase對MapReduce提供支援,它實現了TableMapper類和TableReducer類,我們只需要繼承這兩個類即可。1、寫個mapper繼承TableMapper<Text,IntWritable>
引數:Text:mapper的輸出key型別;IntWritable:mapper的輸出value型別。
其中的map方法如下:
map(ImmutableBytesWritablekey, Result value,Context context)
引數:key:rowKey;value: Result ,一行資料; context上下文
2、寫個reduce繼承TableReducer<Text,IntWritable, ImmutableBytesWritable>
引數:Text:reducer的輸入key; IntWritable:reduce的輸入value;
ImmutableBytesWritable:reduce輸出到hbase中的rowKey型別。
其中的reduce方法如下:
reduce(Textkey, Iterable<IntWritable> values,Context context)
引數: key:reduce的輸入key;values:reduce的輸入value;
2、準備表
1、建立資料來源表‘word’,包含一個列族‘content’向表中新增資料,在列族中放入列‘info’,並將短文資料放入該列中,如此插入多行,行鍵為不同的資料即可
2、建立輸出表‘stat’,包含一個列族‘content’
3、通過Mr操作Hbase的‘word’表,對‘content:info’中的短文做詞頻統計,並將統計結果寫入‘stat’表的‘content:info中’,行鍵為單詞
3、實現
package com.itcast.hbase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
/**
* mapreduce操作hbase
* @author wilson
*
*/
public class HBaseMr {
/**
* 建立hbase配置
*/
static Configuration config = null;
static {
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "slave1,slave2,slave3");
config.set("hbase.zookeeper.property.clientPort", "2181");
}
/**
* 表資訊
*/
public static final String tableName = "word";//表名1
public static final String colf = "content";//列族
public static final String col = "info";//列
public static final String tableName2 = "stat";//表名2
/**
* 初始化表結構,及其資料
*/
public static void initTB() {
HTable table=null;
HBaseAdmin admin=null;
try {
admin = new HBaseAdmin(config);//建立表管理
/*刪除表*/
if (admin.tableExists(tableName)||admin.tableExists(tableName2)) {
System.out.println("table is already exists!");
admin.disableTable(tableName);
admin.deleteTable(tableName);
admin.disableTable(tableName2);
admin.deleteTable(tableName2);
}
/*建立表*/
HTableDescriptor desc = new HTableDescriptor(tableName);
HColumnDescriptor family = new HColumnDescriptor(colf);
desc.addFamily(family);
admin.createTable(desc);
HTableDescriptor desc2 = new HTableDescriptor(tableName2);
HColumnDescriptor family2 = new HColumnDescriptor(colf);
desc2.addFamily(family2);
admin.createTable(desc2);
/*插入資料*/
table = new HTable(config,tableName);
table.setAutoFlush(false);
table.setWriteBufferSize(5);
List<Put> lp = new ArrayList<Put>();
Put p1 = new Put(Bytes.toBytes("1"));
p1.add(colf.getBytes(), col.getBytes(), ("The Apache Hadoop software library is a framework").getBytes());
lp.add(p1);
Put p2 = new Put(Bytes.toBytes("2"));p2.add(colf.getBytes(),col.getBytes(),("The common utilities that support the other Hadoop modules").getBytes());
lp.add(p2);
Put p3 = new Put(Bytes.toBytes("3"));
p3.add(colf.getBytes(), col.getBytes(),("Hadoop by reading the documentation").getBytes());
lp.add(p3);
Put p4 = new Put(Bytes.toBytes("4"));
p4.add(colf.getBytes(), col.getBytes(),("Hadoop from the release page").getBytes());
lp.add(p4);
Put p5 = new Put(Bytes.toBytes("5"));
p5.add(colf.getBytes(), col.getBytes(),("Hadoop on the mailing list").getBytes());
lp.add(p5);
table.put(lp);
table.flushCommits();
lp.clear();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if(table!=null){
table.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* MyMapper 繼承 TableMapper
* TableMapper<Text,IntWritable>
* Text:輸出的key型別,
* IntWritable:輸出的value型別
*/
public static class MyMapper extends TableMapper<Text, IntWritable> {
private static IntWritable one = new IntWritable(1);
private static Text word = new Text();
@Override
//輸入的型別為:key:rowKey; value:一行資料的結果集Result
protected void map(ImmutableBytesWritable key, Result value,
Context context) throws IOException, InterruptedException {
//獲取一行資料中的colf:col
String words = Bytes.toString(value.getValue(Bytes.toBytes(colf), Bytes.toBytes(col)));// 表裡面只有一個列族,所以我就直接獲取每一行的值
//按空格分割
String itr[] = words.toString().split(" ");
//迴圈輸出word和1
for (int i = 0; i < itr.length; i++) {
word.set(itr[i]);
context.write(word, one);
}
}
}
/**
* MyReducer 繼承 TableReducer
* TableReducer<Text,IntWritable>
* Text:輸入的key型別,
* IntWritable:輸入的value型別,
* ImmutableBytesWritable:輸出型別,表示rowkey的型別
*/
public static class MyReducer extends
TableReducer<Text, IntWritable, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
//對mapper的資料求和
int sum = 0;
for (IntWritable val : values) {//疊加
sum += val.get();
}
// 建立put,設定rowkey為單詞
Put put = new Put(Bytes.toBytes(key.toString()));
// 封裝資料
put.add(Bytes.toBytes(colf), Bytes.toBytes(col),Bytes.toBytes(String.valueOf(sum)));
//寫到hbase,需要指定rowkey、put
context.write(new ImmutableBytesWritable(Bytes.toBytes(key.toString())),put);
}
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
config.set("df.default.name", "hdfs://master:9000/");//設定hdfs的預設路徑
config.set("hadoop.job.ugi", "hadoop,hadoop");//使用者名稱,組
config.set("mapred.job.tracker", "master:9001");//設定jobtracker在哪
//初始化表
initTB();//初始化表
//建立job
Job job = new Job(config, "HBaseMr");//job
job.setJarByClass(HBaseMr.class);//主類
//建立scan
Scan scan = new Scan();
//可以指定查詢某一列
scan.addColumn(Bytes.toBytes(colf), Bytes.toBytes(col));
//建立查詢hbase的mapper,設定表名、scan、mapper類、mapper的輸出key、mapper的輸出value
TableMapReduceUtil.initTableMapperJob(tableName, scan, MyMapper.class,Text.class, IntWritable.class, job);
//建立寫入hbase的reducer,指定表名、reducer類、job
TableMapReduceUtil.initTableReducerJob(tableName2, MyReducer.class, job);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}(四)Hbase基礎API與過濾器
1、配置
HBaseConfiguration包:org.apache.hadoop.hbase.HBaseConfiguration
作用:通過此類可以對HBase進行配置
用法例項:
Configuration config = HBaseConfiguration.create();
說明: HBaseConfiguration.create() 預設會從classpath 中查詢 hbase-site.xml 中的配置資訊,初始化 Configuration。
使用方法:
static Configuration config = null;
static {
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "slave1,slave2,slave3");
config.set("hbase.zookeeper.property.clientPort", "2181");
}
2、表管理類
HBaseAdmin包:org.apache.hadoop.hbase.client.HBaseAdmin
作用:提供介面關係HBase 資料庫中的表資訊
用法:
HBaseAdmin admin = new HBaseAdmin(config);
3、表描述類
HTableDescriptor包:org.apache.hadoop.hbase.HTableDescriptor
作用:HTableDescriptor 類包含了表的名字以及表的列族資訊、表的schema(設計)
用法:
HTableDescriptor htd =newHTableDescriptor(tablename);
htd.addFamily(newHColumnDescriptor(“myFamily”));
4、列族的描述類
HColumnDescriptor包:org.apache.hadoop.hbase.HColumnDescriptor
作用:HColumnDescriptor 維護列族的資訊
用法:
htd.addFamily(newHColumnDescriptor(“myFamily”));
5、建立表的操作
CreateTable(一般我們用shell建立表)
static Configuration config = null;
static {
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "slave1,slave2,slave3");
config.set("hbase.zookeeper.property.clientPort", "2181");
}
HBaseAdmin admin = new HBaseAdmin(config);
HTableDescriptor desc = new HTableDescriptor(tableName);
HColumnDescriptor family1 = new HColumnDescriptor(“f1”);
HColumnDescriptor family2 = new HColumnDescriptor(“f2”);
desc.addFamily(family1);
desc.addFamily(family2);
admin.createTable(desc);
6、刪除表
HBaseAdmin admin = new HBaseAdmin(config);
admin.disableTable(tableName);
admin.deleteTable(tableName);7、建立一個表的類
HTable包:org.apache.hadoop.hbase.client.HTable
作用:HTable 和 HBase 的表通訊
用法:
// 普通獲取表
HTable table = newHTable(config,Bytes.toBytes(tablename);
// 通過連線池獲取表
Connection connection =ConnectionFactory.createConnection(config);
HTableInterface table = connection.getTable(TableName.valueOf("user"));8、插入單條資料
Put包:org.apache.hadoop.hbase.client.Put
作用:插入資料
用法:
Put put = new Put(row);
p.add(family,qualifier,value);
說明:向表 tablename 新增“family,qualifier,value”指定的值。
示例程式碼:
Connection connection =ConnectionFactory.createConnection(config);
HTableInterface table = connection.getTable(TableName.valueOf("user"));
Put put = new Put(Bytes.toBytes(rowKey));
put.add(Bytes.toBytes(family),Bytes.toBytes(qualifier),Bytes.toBytes(value));
table.put(put);9、批量插入
List<Put> list = new ArrayList<Put>();
Put put = new Put(Bytes.toBytes(rowKey));//獲取put,用於插入
put.add(Bytes.toBytes(family), Bytes.toBytes(qualifier),Bytes.toBytes(value));//封裝資訊
list.add(put);
table.put(list);//新增記錄
10、刪除資料
Delete包:org.apache.hadoop.hbase.client.Delete
作用:刪除給定rowkey的資料
用法:
Delete del= newDelete(Bytes.toBytes(rowKey));
table.delete(del);
程式碼例項
Connection connection =ConnectionFactory.createConnection(config);
HTableInterface table = connection.getTable(TableName.valueOf("user"));
Delete del= newDelete(Bytes.toBytes(rowKey));
table.delete(del);11、單條查詢
Get包:org.apache.hadoop.hbase.client.Get
作用:獲取單個行的資料
用法:
HTable table = new HTable(config,Bytes.toBytes(tablename));
Get get = new Get(Bytes.toBytes(row));
Result result = table.get(get);
說明:獲取 tablename 表中 row 行的對應資料
程式碼示例:
Connection connection =ConnectionFactory.createConnection(config);
HTableInterface table = connection.getTable(TableName.valueOf("user"));
Get get = new Get(rowKey.getBytes());
Result row = table.get(get);
for (KeyValue kv : row.raw()) {
System.out.print(newString(kv.getRow()) + " ");
System.out.print(newString(kv.getFamily()) + ":");
System.out.print(newString(kv.getQualifier()) + " = ");
System.out.print(newString(kv.getValue()));
System.out.print("timestamp = " + kv.getTimestamp() + "\n");
}12、批量查詢
ResultScanner包:org.apache.hadoop.hbase.client.ResultScanner
作用:獲取值的介面
用法:
ResultScanner scanner = table.getScanner(scan);
For(Result rowResult : scanner){
Bytes[] str = rowResult.getValue(family,column);
}
說明:迴圈獲取行中列值。
程式碼示例:
Connection connection =ConnectionFactory.createConnection(config);
HTableInterface table = connection.getTable(TableName.valueOf("user"));
Scan scan = new Scan();
scan.setStartRow("a1".getBytes());
scan.setStopRow("a20".getBytes());
ResultScanner scanner =table.getScanner(scan);
for (Result row : scanner) {
System.out.println("\nRowkey:" + new String(row.getRow()));
for(KeyValue kv : row.raw()) {
System.out.print(new String(kv.getRow()) +" ");
System.out.print(newString(kv.getFamily()) + ":");
System.out.print(newString(kv.getQualifier()) + " = ");
System.out.print(newString(kv.getValue()));
System.out.print(" timestamp = "+ kv.getTimestamp() + "\n");
}
}13、Hbase過濾器
13.1、FilterList
FilterList 代表一個過濾器列表,可以新增多個過濾器進行查詢,多個過濾器之間的關係有:與關係(符合所有):FilterList.Operator.MUST_PASS_ALL
或關係(符合任一):FilterList.Operator.MUST_PASS_ONE
使用方法:
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ONE);
Scan s1 = new Scan();
filterList.addFilter(new SingleColumnValueFilter(Bytes.toBytes(“f1”), Bytes.toBytes(“c1”), CompareOp.EQUAL,Bytes.toBytes(“v1”) ) );
filterList.addFilter(new SingleColumnValueFilter(Bytes.toBytes(“f1”), Bytes.toBytes(“c2”), CompareOp.EQUAL,Bytes.toBytes(“v2”) ) );
// 新增下面這一行後,則只返回指定的cell,同一行中的其他cell不返回
s1.addColumn(Bytes.toBytes(“f1”), Bytes.toBytes(“c1”));
s1.setFilter(filterList); //設定filter
ResultScanner ResultScannerFilterList = table.getScanner(s1); //返回結果列表13.2 過濾器的種類
過濾器的種類:列植過濾器—SingleColumnValueFilter
過濾列植的相等、不等、範圍等
列名字首過濾器—ColumnPrefixFilter
過濾指定字首的列名
多個列名字首過濾器—MultipleColumnPrefixFilter
過濾多個指定字首的列名
rowKey過濾器—RowFilter
通過正則,過濾rowKey值。
13.3 列植過濾器—SingleColumnValueFilter
SingleColumnValueFilter 列值判斷相等 (CompareOp.EQUAL ),
不等(CompareOp.NOT_EQUAL),
範圍 (e.g., CompareOp.GREATER)…………
下面示例檢查列值和字串'values' 相等...
SingleColumnValueFilter f = new SingleColumnValueFilter(Bytes.toBytes("cFamily"),Bytes.toBytes("column"),CompareFilter.CompareOp.EQUAL,Bytes.toBytes("values"));
s1.setFilter(f);注意:如果過濾器過濾的列在資料表中有的行中不存在,那麼這個過濾器對此行無法過濾。
13.4 列名字首過濾器—ColumnPrefixFilter
過濾器—ColumnPrefixFilterColumnPrefixFilter 用於指定列名字首值相等
ColumnPrefixFilter f = newColumnPrefixFilter(Bytes.toBytes("values"));
s1.setFilter(f);
13.5 多個列名字首過濾器—MultipleColumnPrefixFilter
MultipleColumnPrefixFilter 和ColumnPrefixFilter 行為差不多,但可以指定多個字首
byte[][] prefixes = new byte[][]{Bytes.toBytes("value1"),Bytes.toBytes("value2")};
Filter f = new MultipleColumnPrefixFilter(prefixes);
s1.setFilter(f);13.6 rowKey過濾器——RowFilter
RowFilter 是rowkey過濾器通常根據rowkey來指定範圍時,使用scan掃描器的StartRow和StopRow方法比較好。
Filter f = new RowFilter(CompareFilter.CompareOp.EQUAL, newRegexStringComparator("^1234")); //匹配以1234開頭的rowkey
s1.setFilter(f);相關推薦
Hbase Shell API與過濾器實踐
(一)Hbase Shell1、hbase提供了一個shell的終端給使用者互動#$HBASE_HOME/bin/hbase shell2、如果退出執行quit命令>quit3、檢視資料庫狀態(status)– 表示有3臺機器活著,0臺機器down掉,當前負載0.67(
[大資料]連載No19 Hbase Shell和API的增刪改查+與MapperReducer讀寫操作
本次總結如下1、Hbase Shell的常用命令2、Java APi 對hbase的增刪改查3、Mapper Reducer從hbase讀寫數資料,計算單詞數量,並寫回hbase登入hbase Shell[[email protected] ~]#/home/sof
Flask restful api與blueprint結合實踐
() restfu 模板 Coding init 刪除數據 __main__ reg blueprint 所需依賴: Flask Flask-RESTful Python2.7 備註:flask-restful不能和flask的render_template
HBase技術與應用實踐 | HBase2.0重新定義小物件實時存取
本次分享來自中國HBase技術社群第七屆MeetUp成都站,分享嘉賓天引 阿里巴巴 技術專家專注在大資料領域,擁有多年分散式、高併發、大規模系統的研發與實踐經驗,先後參與HBase、Phoenix、Lindorm等產品的核心引擎研發,目前負責阿里上萬節點的HBase As a Service的發展與落地。 分
HBase Shell常用過濾器
建立表 create ‘test1’, ‘lf’, ‘sf’ lf: column family of LONG values (binary value); sf: column family of STRING values; 匯入資料 put ‘te
在hbase shell中過濾器的簡單使用
在hbase shell中查詢資料,可以在hbase shell中直接使用過濾器: # hbase shell > scan 'testByCrq', FILTER=>"ValueFilter(=,'substring:111')" 如上命令
HBase(3)-安裝與Shell操作
一. 安裝 1. 啟動Zookeeper叢集 2. 啟動Hadoop叢集 3. 上傳並解壓HBase tar -zxvf hbase-1.3.1-bin.tar.gz -C /opt/module 4. 修改配置檔案 #修改habse-env.sh export JAVA_HOM
HBase--通過Java API與HBase互動(增刪改)
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop
Hbase Java API簡單實踐(附原始碼解釋)
註釋 標註1 標註2 標註3 標註4 執行截圖: 參考資源 詳細程式碼及連結 maven依賴:hbase-client,slf4j-api,slf4j-nop(不需要hbase-server包) resource中加入
【原創 Hadoop&Spark 動手實踐 3】Hadoop2.7.3 MapReduce理論與動手實踐
pack license 讀取 rgs 理論 程序員開發 -s 接口 pri 開始聊MapReduce,MapReduce是Hadoop的計算框架,我學Hadoop是從Hive開始入手,再到hdfs,當我學習hdfs時候,就感覺到hdfs和mapreduce關系的緊密。這個
linux命令基礎:shell操作符與鍵盤通配符
完整 操作 執行 shel 接收 str abc test 括號 通配符 通配符是一類鍵盤字符 。 當查找文件夾時;當不知道真正字符或者不想鍵入完整名字時,常常使用通配符代替一個或多個真正字符。 * 代替0個或多個字符。 ?
Javascript設計模式與開發實踐詳解(二:策略模式) http://www.jianshu.com/p/ef53781f6ef2
的人 思想 ram gis pan pro msg have 改變 上一章我們介紹了單例模式及JavaScript惰性單例模式應用這一次我主要介紹策略模式策略模式是定義一系列的算法,把它們一個個封裝起來,並且讓他們可以互相替換。比方說在現實中很多時候也有很多途徑到達同一個
攔截器與過濾器的區別
攔截器 過濾器 interceptor filter 攔截器過濾器關鍵詞AOP、代理模式、反射機制、spring 函數回調、servlet、web原理反射機制函數回調容器不依賴servlet依賴servlet作用範圍只能對action請求起作用可以訪問action上下文、值棧裏的對象可以對所有
HBase shell
時間 itblog 接口 amp 修飾符 import computer turn dsl HBase 為用戶提供了一個非常方便的使用方式, 我們稱之為“HBase Shell”。HBase Shell 提供了大多數的 HBase 命令, 通過 HBase Shell 用戶
微服務架構的兩大解耦利器與最佳實踐
架構 微服務 沈劍 這幾年,微服務架構這個術語漸成熱門詞匯,但它不是一個全新架構,更不是一個包治百病的架構。那麽,微服務架構究竟能夠解決什麽問題,又帶來哪些痛點?本文將與大家談談這個問題,以及微服務架構的兩大解耦利器配置中心和消息總線的最佳實踐。微服務架構解決的問題與帶來的痛點一互聯網高可用架構為
HBase學習總結(1):HBase的下載與安裝
oot 停止 微信公眾號 profile jdk1 variable jdk oop lib (HBase是一種數據庫:Hadoop數據庫,它是一種NoSQL存儲系統,專門設計用來高速隨機讀寫大規模數據。本文介紹HBase的下載與安裝的整個過程。) 一
字符流的實現與過濾器
而不是 字節數 output pri read 編碼方式 需要 處理文本 字節序 首先,inputstream定義了字節流的輸入,outputstream定義了字節流的輸出。 但是我們常常要處理文本文件(不是音頻視頻)也即是字符,而不是不可理解的字節(字符流的底層仍然是字節
《深入理解Java虛擬機:JVM高級屬性與最佳實踐》讀書筆記(更新中)
pen 內存區域 深度 span 進化 ria 最短 描述 core 第一章:走進Java 概述 Java技術體系 Java發展史 Java虛擬機發展史 1996年 JDK1.0,出現Sun Classic VM HotSpot VM, 它是 Sun JDK 和 Open
[4] 算法之路 - 插入排序之Shell間隔與Sedgewick間隔
取出 然而 int edge lsh 分享 間隔 使用 des 題目 插入排序法由未排序的後半部前端取出一個值。插入已排序前半部的適當位置。概念簡單但速度不快。 排序要加快的基本原則之中的一個: 是讓後一次的排序進行時,盡量利用前一次排序後的結
Hbase shell基本操作
records 例子 每次 edi operation sim pin binary file 1、啟動cd <hbase_home>/bin$ ./start-hbase.sh 2、啟動hbase shell # find hadoop-hbase dfs