caffe中fine-tuning的那些事
如果對caffe並不是特別熟悉的話,從頭開始訓練一個模型會花費很多時間和精力,需要對整個caffe框架有一個很清楚的瞭解,難度比較高;同時,在使用資料迭代訓練自己模型時會耗費很多計算資源。對於單GPU或者沒有大的GPU計算能力的研究者會比較困難。所以,使用已經訓練好的caffe模型來進行finetuning就會是一個比較好的選擇。
所謂fine tune就是用別人訓練好(通常是ImageNet上1000類分類訓練
fine tune的好處在於不用完全重新訓練模型,從而提高效率,因為一般新訓練模型準確率都會從很低的值開始慢慢上升,但是fine tune能夠讓我們在比較少的迭代次數之後得到一個比較好的效果。在資料量不是很大的情況下,fine tune會是一個比較好的選擇。但是如果你希望定義自己的網路結構的話,就需要從頭開始了。
另外,finetuning需要的計算資源相對較少,使用的trikes相對較少,難度較低,比較適合caffe新手。在finetuning過程中熟悉caffe的各種介面和操作。
finetuning的過程和訓練的過程步驟大體相同,因此在finetuning的過程中可以對caffe訓練過程有一個詳細的瞭解,通過一步步的訓練和finetuning,在尋找最優引數過程中加深對caffe框架的理解,為自己後續自己從頭開始訓練一個caffe深度網路模型打好基礎。
話不多說,具體的fine-tuning流程如下:
一、準備好自己的訓練資料和測試資料;
二、計算資料集的均值檔案,因為資料集中特定領域的影象均值檔案會跟imagenet上比較general的資料的均值不太一樣;
前面兩步和平時我們訓練時製作自己的資料一樣;
三、複製一份該model檔案對應的prototxt檔案進行修改,因為finetuning的過程是讓原有訓練好的模型適應自己的資料,因此一般情況下,網路的模型並沒有大的變化。修改網路最後一層的網路名字(這樣預訓練模型賦值的時候就會因為名字的不同而重新訓練,達到適應新任務的目的)和輸出類別num_output,並且需要加快最後一層的引數學習速率(因為是最後一層要重新學習,所以將最後一層的weight和bias的lr_mult加快10倍),此外,和fc8相關的名字都要改掉;
四、調整solver檔案的網路引數,通常學習數率和步長,迭代次數都要適當減少,這正式微調的本質所在;基本上就是將test_iter\base_lr\stepsize\max_iter進行相應地減小;
五、啟動訓練,並且需要載入pretrained模型的引數。在caffe根目錄下執行: ./build/tools/caffe train -solver models/finetune_flickr_style/solver.prototxt -weights models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel -gpu 0
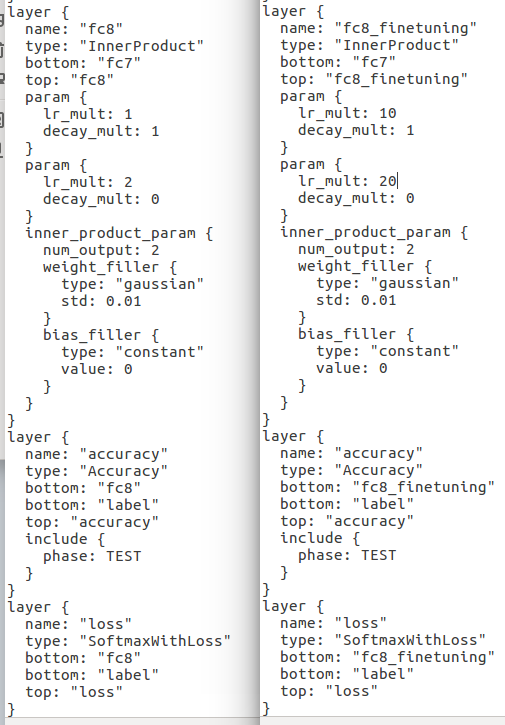
選取train函式,後面接具體的引數,分別為配置命令,配置檔案路徑,fine-tuning命令,fine-tuning依賴的基準模型檔案目錄,選用的訓練方式:gpu或者cpu,使用cpu時可以預設不寫。fine-tuning的過程與訓練過程類似,只是在呼叫caffe介面時的命令不同,因此在fine-tuning之前,仍然需要按照訓練流程準備資料:下載資料->生成trainset和testset->生成db->設定好路徑->fine-tuning。這過程主要呼叫的是我們修改好的solver來自我們修改好的solver.prototxt檔案,weights來自我們下載好的caffemodel。