
Hive程式設計指南-JDBC連線、指令碼執行
一、Hive連線
1.1、通過shell
1、hive 命令列模式,直接輸入#/hive/bin/hive的執行程式,或者輸入#hive --service cli
#hive --service hwi
用於通過瀏覽器來訪問hive
http://hadoop0:9999/hwi/
3、 hive 遠端服務 (埠號10000) 啟動方式
#hive --service hiveserver
注意:hiveserver不能和hwi服務同時啟動使用。
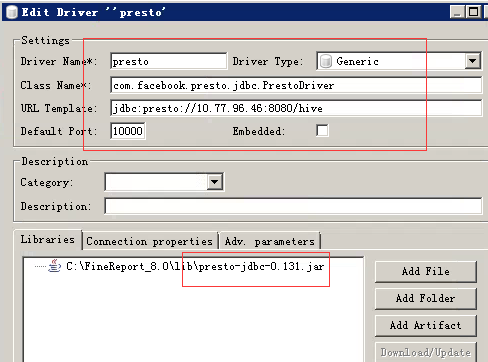
4、使用dbveare工具
需要將presto的jar新增進來並配置連線
1.2 通過java程式碼
使用java程式碼來連線hive時,驅動可以選擇使用jdbc,也可以選擇使用presto
HiveServer使用thrift服務來為客戶端提供遠端連線的訪問埠,在JDBC連線Hive之前必須先啟動HiveServer。
hive --service hiveserver hiveserver預設埠是10000,可以使用hive --service hiveserver -p 10002,更改預設啟動埠,此埠也是JDBC連線埠。
1、直接通過jdbc
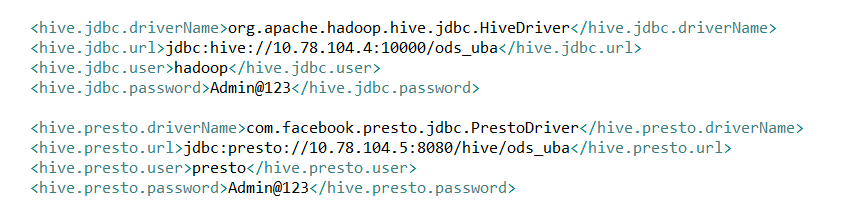
其中對應的配置檔案:package com.lin.bdp.common.utils; import java.lang.reflect.Field; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import java.sql.SQLException; import java.sql.Statement; import java.util.ArrayList; import java.util.List; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.lin.bdp.common.vo.Visitor; /** * * 功能概要:hive客戶端工具 * * @author linbingwen * @since 2016年10月20日 */ public class HiveJdbcClient { private static final Logger logger = LoggerFactory.getLogger(HiveJdbcClient.class); public static final char UNDERLINE = '_'; private static String driverName; private static String url; private static String user; private static String password; private static class LazyHolder { private static final HiveJdbcClient INSTANCE = new HiveJdbcClient(); } public static final HiveJdbcClient getInstance() { return LazyHolder.INSTANCE; } /** * 初始化引數 * @author linbingwen * @since 2016年10月20日 */ private void init() { driverName = ConfigLoader.getProperty("hive.jdbc.driverName"); url = ConfigLoader.getProperty("hive.jdbc.url"); user = ConfigLoader.getProperty("hive.jdbc.user"); password = ConfigLoader.getProperty("hive.jdbc.password"); } private void initPresto() { driverName ="com.facebook.presto.jdbc.PrestoDriver"; url = "jdbc:presto://10.78.104.5:8080/hive/ods_uba"; user = "presto"; password = "[email protected]"; } private HiveJdbcClient() { init(); } /** * 獲取連線 * @author linbingwen * @since 2016年10月20日 * @return * @throws ClassNotFoundException * @throws SQLException */ private Connection getConnection() throws ClassNotFoundException, SQLException { Class.forName(driverName); Connection conn = DriverManager.getConnection(url, user, password); return conn; } /** * 按條件查詢 * @author linbingwen * @since 2016年10月20日 * @param clazz * @param sql * @return * @throws Exception */ public <T> List<T> find(Class<T> clazz, String sql) throws Exception { if (sql == null || sql.length() == 0) { logger.warn("查詢sql語句不能為空"); return new ArrayList<T>(); } Connection connection = null; PreparedStatement preState = null; ResultSet rs = null; try { connection = getConnection(); Statement stmt = connection.createStatement(); rs = stmt.executeQuery(sql); return (List<T>) handler(clazz, rs); } catch (Exception e) { logger.error("sql = {}執行出錯,Exception = {}", sql, e.getLocalizedMessage()); throw e; } finally { release(connection,preState,rs); } } /** * 釋放資源 * * @author linbingwen * @since 2016年8月31日 * @param conn * @param st * @param rs */ private void release(Connection conn, Statement st, ResultSet rs) { if (rs != null) { try { rs.close(); } catch (Exception e) { e.printStackTrace(); } rs = null; } if (st != null) { try { st.close(); } catch (Exception e) { e.printStackTrace(); } st = null; } if (conn != null) { try { conn.close(); } catch (Exception e) { e.printStackTrace(); } } } /** * 下劃線欄位轉成陀峰欄位 * @author linbingwen * @since 2016年10月20日 * @param param * @return */ private String underlineToCamel(String param) { if (param == null || param.isEmpty()) { return null; } int len = param.length(); StringBuilder sb = new StringBuilder(len); for (int i = 0; i < len; i++) { char c = param.charAt(i); if (c == UNDERLINE) { if (++i < len) { sb.append(Character.toUpperCase(param.charAt(i))); } } else { sb.append(c); } } return sb.toString(); } /** * 組裝list物件 * @author linbingwen * @since 2016年10月20日 * @param clazz * @param rs * @return * @throws Exception */ private Object handler(Class clazz, ResultSet rs) throws Exception { List list = new ArrayList(); try { while (rs.next()) { Object bean = clazz.newInstance(); ResultSetMetaData meta = rs.getMetaData(); int count = meta.getColumnCount(); for (int i = 0; i < count; i++) { String columnName = meta.getColumnName(i + 1); String name = columnName; if (columnName.contains(".")) { String[] split = columnName.split("\\."); if (split.length != 2) { throw new Exception("輸入的表名不正確!"); } name =split[1]; } Object value = rs.getObject(columnName); name = underlineToCamel(name.toLowerCase()); try { Field f = bean.getClass().getDeclaredField(name); if (f != null) { f.setAccessible(true); f.set(bean, value); } } catch (NoSuchFieldException e) { logger.error("表中欄位:{}在類:{}沒有對應的屬性", name, clazz); } catch (IllegalArgumentException e) { logger.error("表中欄位:{}在類:{}對應屬性型別不一到", name, clazz); } } list.add(bean); } } catch (Exception e) { throw e; } logger.info("hiveHandler successed the total size is:{}",list.size()); return list; } @Override public String toString() { return "HiveJdbcClient driverName:" + driverName + " url:" + url + " user:" + user + " password:" + password; } public List<Table> export() throws ClassNotFoundException, SQLException { String showtablesSQL = "show tables"; List<Table> tableList = new ArrayList<Table>(); List<String> tableNameList = new ArrayList<String>(); Connection conn = getConnection(); Statement stmt = null; ResultSet tableRs = null; // 存庫元資料 ResultSet colRs = null;//儲存表元資料 try { stmt = conn.createStatement(); stmt.executeQuery("use ods_uba"); //獲取表名 tableRs = stmt.executeQuery(showtablesSQL); while (tableRs.next()) { String table = tableRs.getString(1); tableNameList.add(table); } //獲取表結構 com.lin.bdp.common.utils.Field field = null; Table table = null; for (int i = 0; i < tableNameList.size(); i++) { String descTableSQL = "describe "; List<com.lin.bdp.common.utils.Field> fieldList = new ArrayList<com.lin.bdp.common.utils.Field>(); descTableSQL = descTableSQL + tableNameList.get(i).trim();//拼接sql colRs = stmt.executeQuery(descTableSQL); while (colRs.next()) { field = new com.lin.bdp.common.utils.Field(); field.setColumnName(colRs.getString(1)); field.setTypeName(colRs.getString(2));//測試大小 fieldList.add(field); } table = new Table(); table.setTableName(tableNameList.get(i).trim()); table.setField(fieldList); System.out.println(table); tableList.add(table); } } catch (SQLException ex) { } finally { if (colRs != null) { try { colRs.close(); } catch (SQLException ex) { } } if (tableRs != null) { try { tableRs.close(); } catch (SQLException ex) { } } if (conn != null) { try { conn.close(); } catch (SQLException ex) { } } } return tableList; } public static void main(String[] args) { HiveJdbcClient hiveJdbcClient = HiveJdbcClient.getInstance(); try { hiveJdbcClient.export(); } catch (Exception e) { e.printStackTrace(); } System.exit(0); } }
對應的field.java
public class Field {
private String columnName;
private String typeName;
private int columnSize;
private int decimal_digits;
private int nullable;
public Field() {
}
public Field(String columnName, String typeName, int columnSize, int decimal_digits, int nullable) {
this.columnName = columnName;
this.typeName = typeName;
this.columnSize = columnSize;
this.decimal_digits = decimal_digits;
this.nullable = nullable;
}
public String getColumnName() {
return columnName;
}
public void setColumnName(String columnName) {
this.columnName = columnName;
}
public String getTypeName() {
return typeName;
}
public void setTypeName(String typeName) {
this.typeName = typeName;
}
public int getColumnSize() {
return columnSize;
}
public void setColumnSize(int columnSize) {
this.columnSize = columnSize;
}
public int getDecimal_digits() {
return decimal_digits;
}
public void setDecimal_digits(int decimal_digits) {
this.decimal_digits = decimal_digits;
}
public int getNullable() {
return nullable;
}
public void setNullable(int nullable) {
this.nullable = nullable;
}
@Override
public String toString() {
return "Field{" + "columnName=" + columnName + ", typeName=" + typeName + ", columnSize=" + columnSize + ", decimal_digits=" + decimal_digits + ", nullable=" + nullable + '}';
}
}
對應的table.java
package com.lin.bdp.common.utils;
import java.util.List;
public class Table {
private String tableName;
private List<Field> field;
public Table() {
}
public Table(String tableName, List<Field> field) {
this.tableName = tableName;
this.field = field;
}
public String getTableName() {
return tableName;
}
public void setTableName(String tableName) {
this.tableName = tableName;
}
public List<Field> getField() {
return field;
}
public void setField(List<Field> field) {
this.field = field;
}
@Override
public String toString() {
return "Table{" + "tableName=" + tableName + ", field=" + field + '}';
}
}2、直接通過presto
package com.lin.bdp.common.utils;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
public class HivePrestoClient {
public static void main(String[] args) throws SQLException, ClassNotFoundException{
//jdbc:presto://cdh1:8080/hive/sales
Class.forName("com.facebook.presto.jdbc.PrestoDriver");
Connection connection = DriverManager.getConnection("jdbc:presto://10.78.104.5:8080/hive/ods_uba","presto","[email protected]");
// connection.setCatalog("hive");
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery("select * from ods_uba.visitor_lin limit 10");
// ResultSet rs = stmt.executeQuery("select count(*) uuid,lst_visit_chnl lst_visit_chnl from ods_uba.visitor_lin group by lst_visit_chnl");
while (rs.next()) {
ResultSetMetaData meta = rs.getMetaData();
int count = meta.getColumnCount();
for (int i = 0; i < count; i++) {
String name = meta.getColumnName(i + 1);
Object value = rs.getObject(name);
System.out.println(name + ":" + value);
}
}
rs.close();
connection.close();
System.out.println("exit");
// System.exit(0);
}
}在presto的安裝目錄下,etc/config.properties 包含 Presto Server 相關的配置,每一個 Presto Server 可以通時作為 coordinator 和 worker 使用。
http-server.http.port=80803、用到的相關jar包
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-jdbc</artifactId>
<version>0.75</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>0.7.1-cdh3u6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>0.7.1-cdh3u6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>0.7.1-cdh3u6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop.hive</groupId>
<artifactId>hive-service</artifactId>
<version>0.7.1-cdh3u6</version>
</dependency>二、Hive指令碼執行
Hive也可以直接執行sql指令碼,或者通過shell指令碼來呼叫sql指令碼ive指令碼的執行方式大致有三種:
1. hive控制檯執行
比較簡單,不再多說;2. hive -e "SQL"執行
hive -e "use ods_uba;ALTER TABLE lin DROP PARTITION (opdt='2016-02-04');當然也可以將這一行程式碼放在一個shell指令碼中來執行:
如下是刪除表裡一天分割槽的記錄(分割槽以opdt = 'yyyy-mm-dd')形式存在
#!/bin/sh
source ~/.bashrc
#清資料
doClean(){
partition=$(echo "$path/opdt=$statisDate")
echo "hdfs dfs -rm -r -f $partition"
hive -e "use ods_uba;ALTER TABLE $tableName DROP PARTITION (opdt='$statisDate');"
hdfs dfs -rm -r -f $partition
}
#統計日期預設取昨天
diffday=15
statisDate=`date +"%Y-%m-%d" -d "-"${diffday}"day"`
path=/hive/warehouse/ods_uba.db/$1
#首先判斷是否有輸入日期,以及輸入日期是否合法,如果合法,取輸入的日期。不合法報錯,輸入日期為空,取昨天
if [ $# -eq 0 ]; then
echo "您沒有輸入引數,請至少輸入表名kafka_appchnl_source_log/kafka_web_source_log"
elif [ $# -eq 1 ]; then
echo "您輸入的第一個引數為: $1 "
tableName=$1
if [[ "$tableName" == "kafka_appchnl_source_log" ]] || [[ "$tableName" == "kafka_web_source_log" ]]; then
echo "要清除的表名是:$tableName,路徑:$path,清除分割槽的日期:$statisDate"
doClean $tableName $path $statisDate
else
echo "您輸入的表名有錯,請輸入表名kafka_appchnl_source_log/kafka_web_source_log"
fi
elif [ $# -eq 2 ]; then
echo "您輸入的第一個引數為: $1,第二個引數 :$2"
tableName=$1
statisDate=$2
if [[ "$tableName" == "kafka_appchnl_source_log" ]] || [[ "$tableName" == "kafka_web_source_log" ]]; then
echo "要清除的表名是:$tableName,路徑:$path"
if [ ${#statisDate} -eq 10 ];then
echo "清除分割槽的日期:$statisDate"
doClean $tableName $path $statisDate
else
echo "您輸入日期不合法,請輸入yyyy-mm-dd型別引數"
fi
else
echo "您輸入的表名有錯,請輸入表名kafka_appchnl_source_log/kafka_web_source_log"
fi
else
echo "您輸入引數多於2個,請重新輸入"
fi
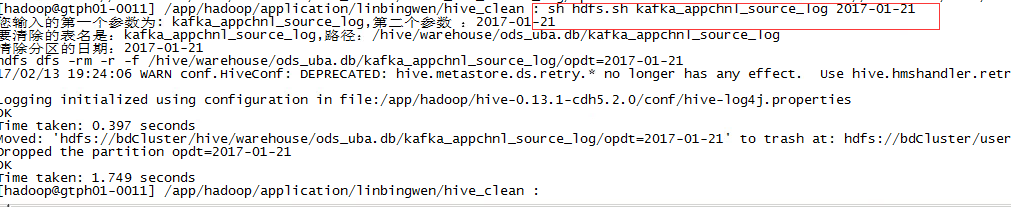
執行指令碼:
3. hive -f SQL檔案執行
如果sql都放在.sql檔案中呢?那就用hive -f
新建一個clean.sql內容如下:
use ods_uba;
ALTER TABLE ${hiveconf:tableName} DROP PARTITION (partition_time='${hiveconf:partitionTime}');執行如下語句就可以刪除一個分割槽
hive -hiveconf tableName=lin -hiveconf partitionTime='2016-01-23' -f clean.sql這裡hiveconf可以用來傳遞引數
最後,也可以將shell指令碼和sql指令碼結合一起用。
新建一個如下doClean.sh
#!/bin/sh
. ~/.bashrc
#清資料,注意要傳入一個yyyy-mm-dd型別引數
cleanData(){
echo "您要清理資料的日期為:$statisDate"
#生成每小時的查詢條件
for i in `seq 24`
do
num=$(echo $i)
doClean $tableName $statisDate $num
done
}
#清資料
doClean(){
echo "輸入日期:$statisDate,輸入序列號:$num"
timeZone=$(printf "%02d\n" $(expr "$num" - "1"))
partitionTime=$(echo "$statisDate-$timeZone")
echo "清資料的表名:$tableName 分割槽欄位:$partitionTime"
hive -hiveconf tableName=$tableName -hiveconf partitionTime=$partitionTime -f clean.sql
}
#統計日期預設取昨天
diffday=1
statisDate=`date +"%Y-%m-%d" -d "-"${diffday}"day"`
#首先判斷是否有輸入日期,以及輸入日期是否合法,如果合法,取輸入的日期。不合法報錯,輸入日期為空,取昨天
if [ $# -eq 0 ]; then
echo "您沒有輸入引數,請至少輸入表名visit_log/evt_log/chnl_req"
elif [ $# -eq 1 ]; then
echo "您輸入的第一個引數為: $1 "
tableName=$1
if [[ "$tableName" == "visit_log" ]] || [[ "$tableName" == "evt_log" ]] || [[ "$tableName" == "chnl_req" ]]; then
echo "要清除的表名是:$tableName,清除分割槽的日期:$statisDate"
cleanData $tableName $statisDate
else
echo "您輸入的表名有錯,請輸入表名visit_log/evt_log/chnl_req"
fi
elif [ $# -eq 2 ]; then
echo "您輸入的第一個引數為: $1,第二個引數 :$2"
tableName=$1
statisDate=$2
if [[ "$tableName" == "visit_log" ]] || [[ "$tableName" == "evt_log" ]] || [[ "$tableName" == "chnl_req" ]]; then
echo "要清除的表名是:$tableName"
if [ ${#statisDate} -eq 10 ];then
echo "清除分割槽的日期:$statisDate"
cleanData $tableName $statisDate
else
echo "您輸入日期不合法,請輸入yyyy-mm-dd型別引數"
fi
else
echo "您輸入的表名有錯,請輸入表名visit_log/evt_log/chnl_req"
fi
else
echo "您輸入引數多於2個,請重新輸入"
fi
這裡將一天分成了24個區,所以要刪除一天的資料需要刪除24個分割槽,分割槽以(yyyy-mm-dd-ss)
執行時使用:

相關推薦
Hive程式設計指南-JDBC連線、指令碼執行
摘要:本文主要講了如何通過java來連線Hive,以及如何執行hive指令碼一、Hive連線1.1、通過shell1、hive 命令列模式,直接輸入#/hive/bin/hive的執行程式,或者輸入#hive --service cli2、 hive web介面
Hive Shell 命令之二(表中資料的操作,出自Hive程式設計指南)
一、 互動模式: show tables; #檢視所有表名 show tables 'ad*' #檢視以'ad'開頭的表名 set 命令 #設定變數與檢視變數; set -v #檢視所有的變數 set hive.stats.atomic #檢視hive.sta
hive程式設計指南學習筆記之二:hive資料庫及其中的表查詢
show databases; /*
hive程式設計指南學習筆記之一:建表語句以及分隔符定義
/*建立包括基本資料型別string\float,以及集合資料型別array、map 、struct的表,並指定表中的列、元素、map中鍵值之間的分隔符 很好的一個例子。 */ create table employees ( name string, &nbs
Hive程式設計指南-學習筆記(一) 資料型別和分隔符
一、Hive概述 Hive定義了類似SQL的查詢語言——HiveQL,使用者編寫HiveQL語句執行MapReduce任務,查詢儲存在Hadoop叢集中的資料。 HiveQL與MySQL最接近,但還是有顯著性差異的。Hive不支援行級插入、更新操作和刪除操作。Hive不支
Hive程式設計指南-學習筆記(二) 資料定義
一、資料庫 1、建立資料庫:CREATE DATABASE hive; 如果已經存在,會丟擲異常,下面的語句不丟擲異常:CREATE DATABASE IF NOT EXISTS hive; 資料庫的預設位置是hdfs上:/user/hive/warehouse,修改預
Hive程式設計指南-學習筆記(三) 資料操作
一、向管理表中裝載資料 Hive沒有行級別的資料插入、更新和刪除操作,往表中裝載資料的唯一途徑就是使用一種“大量”的資料裝載操作。 LOAD:向表中裝載資料 (1)把目錄‘/usr/local/data’下的資料檔案中的資料裝載進usr表,並覆蓋原有資料:LOAD DA
python併發程式設計之多程序、多執行緒、非同步和協程
一、多執行緒 多執行緒就是允許一個程序記憶體在多個控制權,以便讓多個函式同時處於啟用狀態,從而讓多個函式的操作同時執行。即使是單CPU的計算機,也可以通過不停地在不同執行緒的指令間切換,從而造成多執行緒同時執行的效果。 多執行緒相當於一個併發(concunrr
嵌入式初學者學習嵌入式必看必看書籍列表,有電子檔的同學可以共享出來,謝謝 Linux基礎 1、《Linux與Unix Shell 程式設計指南》 2、《嵌入式Linux應用程式開發詳解》
嵌入式初學者參考書目 無論學習哪方面的程式設計,都需要掌握基礎知識和程式語言,其中《深入理解計算機作業系統》是比較重要的。下面是一些計算機關於嵌入式方面的推薦,有些是借鑑他人的歸納。 Linux基礎 1、《Linux與Unix Shell 程式設計指南》 2、《嵌入式Linux應用程式開發詳
《Hive程式設計指南》筆記
準備工作 配置mysql資料庫為元資料庫 vi hive2.2/conf/hive-site.xml 初始化hive $HIVE_HOME/bin/schematool -dbType -initSchema 啟動hive HIVEHOME/bin/hi
《hive程式設計指南》閱讀筆記摘要(一)
第一二章 基礎知識、基礎操作 hive的缺點 1、hive不支援記錄級別的增刪改操作,但是使用者可以通過查詢生成新表或者將查詢結果匯入到檔案中。 2、Hive的查詢延時很嚴重,因為MapReduce job的啟動過程消耗很長時間,所以不能用在互動查詢系統中。 3、hive不
IOS併發程式設計指南:Dispatch Queue任務執行與Dispatch Source
導讀: 本文為讀《Concurrency Programming Guide》筆記第三篇,在對OS X和iOS應用開發中實現任務非同步執行的技術、注意事項、Operation與Dispatch Queues實踐解析後,作者付宇軒(@DevTalking)著重分享了讓Disp
刪除資料夾、指令碼執行cmd命令、解壓縮zip
import shutil shutil.rmtree(絕對路徑),將刪除這整個資料夾 如何在python指令碼執行cmd命令? import os os.system(command) 其中,command是cmd命令。 如何解壓縮zip檔案?
Hive程式設計指南-Spark操作Hive
摘要:本文將要說明如何使用Spark來對Hive進行操作1、打jar包,提交Spark任務 通過提交spark任務的方式,如下面的scala程式碼。之後需要將成程式碼打包成一個jar包,然後提交到spark中去.一般情況下生產上建議使用這種方法,可
《hive程式設計指南》閱讀筆記摘要(九)
第10章 調優一個hive任務會包含有一個或多個階段stage,不同的stage間有依賴關係。 一、分析複雜的或者執行效率低的查詢時,可以使用explain語句,如 explain select .....; 二、explain extended可以產生更多的輸出資訊 ex
jdbc連線mysql資料庫執行sql語句ResultSet結果集一直為空
問題描述:ResultSet rs=sqlstatement.executeQuery(sql); 執行後查詢語句後rs一直為空,但是將sql語句放到資料庫中進行查詢卻能得到結果. 解決:sql=“s
Hive程式設計指南---動態分割槽插入
Hive如果需要建立非常多的分割槽,那麼使用者就需要寫很多的SQL,Hive提供了一個動態分割槽功能,其可以基於查詢引數推斷需要建立的分割槽名稱 INSERT OVERWRITE TABEL employee PARTITION(country,state) SELECT
《Hive程式設計指南》讀書筆記 | 一文看懂Hive的資料型別和檔案格式
Hive支援關係型資料庫中的大多數基本資料型別,同時也支援關係型資料庫中很少出現的3種集合資料型別。和大多數資料庫相比,Hive具有一個獨特的功能,那就是其對於資料在檔案中的編碼方式具有非常大的靈活性。大多數資料庫對資料具有完全的控制,其包括對資料儲存到磁碟的過程的控制,也包括對資料生命週期的控制。而Hi
【JDBC程式設計】Java 連線 MySQL資料庫基礎、入門和進階
Content: 常用的JDBC API 資料庫環境的搭建 建立資料庫連線 資料庫訪問優化 一. 常用的JDBC API 1. DriverManager類 : 資料庫管理類,用於管理一組JDBC驅動程式的基本服務。應用程式和資料
kylin調優,專案中錯誤總結,知識點總結,kylin jdbc driver + 資料庫連線池druid + Mybatis專案中的整合,shell指令碼執行kylin restapi 案例
關於本篇文章的說明: 本篇文章為筆者辛苦勞作用了一整天總結出來的文件,大家閱讀轉發的時候請不要吝嗇寫上筆者:塗作權 和 原文地址。 由於筆者所在環境沒有人用過kylin,筆者也是自學官網,閱讀書籍 將kylin用於實際專案,期間遇到了很多很多關於kylin使用的問題。為了讓後面的人在