
Kafka系列 —— 入門及應用場景 & 部署 & 簡單測試
Kafka系列為自己學習與使用Kafka中遇到的問題與總結。本系列將介紹如下內容:
- Kafka入門及應用場景 & 部署 & 簡單測試
- Kafka核心概念
- Kafka常用命令
- Kafka監控
- Kafka消費語義分析
- Flume + Kafka + SparkStreaming打造通用的流處理基礎平臺
- 生產案例分享
是一個長期更新的系列,希望自己能夠堅持:)
入門及應用場景
官網描述所發生的改變

分散式的流式平臺;原來叫訊息平臺,這是因為現在kafka加入了stream,所以有了說法上的改變
3個特性

一個流式平臺有以下3個特性:
- 釋出和訂閱流式的訊息,類似於訊息佇列
- 以高容錯的方式儲存訊息
- 處理流式訊息
2種應用場景

Kafka一般有2種應用場景:
- 離線場景:資料寫到Kafka,後面寫個應用程式然後每個批次去消費它,也是可以的美圖就是這樣在做,資料接到Kafka之後,然後基於MapReduce構建ETL操作,將資料落到HDFS上
一般來說,使用Kafka對接實時處理框架比較多 - 構建實時的流式應用,指的是Kafka stream,在生產中用的不是很多
常見的應用場景:作為訊息中介軟體,一般部署在流式元件的前一個,主要為了避免高峰期計算來的壓力
部署
Zookeeper簡介&部署
簡介
Zookeeper官網:http://zookeeper.apache.org/
作用:Zookeeper是一個協調服務,一般會用zk來做HA
版本:生產上Zookeeper的版本是3.4.6
機器數量:生產叢集小於100臺,Zookeeper部署7臺
生產叢集大於100臺,Zookeeper部署7臺 或 9臺
注意:並不是Zookeeper的機器越多越好,因為在選舉的時候如果機器很多,選舉肯定是很繁忙的(個人經驗)
遇到問題可以去檢視zookeeper.out,有具體的報錯資訊,可以進行排查
也可以使用ps –ef|grep zookeeper去檢視程序是否存活
部署
使用
HDFS HA、YARN HA都依賴於Zookeeper,Kafka、HBase也依賴於Zookeeper
進入到客戶端的相關操作:
- zkCli.sh進入到當前機器的客戶端介面,localhost模式
- 指定其中一臺zookeeper地址進入
命令:ZooKeeper -server host:port

- 命令幫助,進入console,輸入help
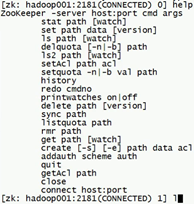
- 幾個簡單的命令介紹:
ls /
ls /zookeeper
rmr path
jdk和scala部署
jdk的部署路徑:/usr/java
JDBC的部署路徑:/usr/share/java
原因:CDH環境中server端和agent端會優先讀取這個路徑,如果不這樣配置會很麻煩
使用CDH建議這樣配置
Scala版本:2.11.8
Kafka部署
版本介紹
Kafka版本:0.8.x 0.10.x
主要是這兩個分支,為什麼是這兩個,結合SparkStreaming官網:
https://spark.apache.org/docs/2.2.0/streaming-kafka-integration.html
選用版本:kafka_2.11-0.10.0.1.tgz
原因:後續SparkStreaming對接Kafka使用direct模式
部署步驟
叢集部署
需要修改的配置檔案:$KAFKA_HOMR/config/server.properties
broker.id=1
port=9092
host.name=xxxx
log.dirs=/opt/software/kafka/logs
zookeeper.connect=xxxx:2181,xxxx:2181,xxxx:2181/kafka
3臺機器,對應修改broker.id和host.name即可
且在每臺機器上去建立對應的log.dirs路徑即可
環境變數配置
配置在/etc/profile下,具體步驟略
簡單測試
啟動/停止
每臺機器執行:
nohup kafka-server-start.sh config/server.properties &
後臺啟動,以防Kafka程序掛掉
停止命令:
bin/kafka-server-stop.sh
模擬實驗
Kafka建立完成之後,在zookeeper中的目錄是怎麼樣的呢?如下圖:

該操作是沒有指定 /kafka 目錄的情況,因此都是散亂的目錄;指定後就都在 /kafka 下了
修改server.properties:
zookeeper.connect=xxxx:2181,xxxx:2181,xxxx:2181/kafka
這樣操作後,會將對應的資訊寫到zookeeper中的/kafka目錄下
建立topic:

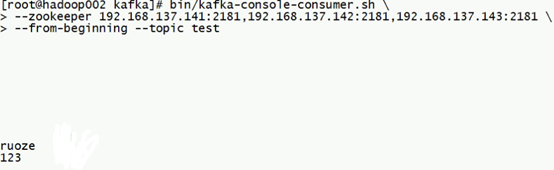
開啟生產者:

開啟消費者:

在生產者的console下輸入,即開始向Kafka中寫入資料:

消費者開始消費:
常見的架構
Kafka部署完成的程序,實質上是一個broker
一般的流程:producer --> broker cluster --> consumer
一般的架構:Flume --> Kafka --> Spark Streaming
以生產為例:

xx日誌和xx日誌用的同一套Kafka叢集,針對不同的日誌設立不同的topic
可以抽象的將topic理解為資料夾,如果指定了topic為yy,那麼所有對應的資料都會在yy下面;而計算程式在程式碼中就會指定到對應的topic中去讀取資料,進行消費
具體含義下面的文章中會介紹