
一文看懂ARM Cortex-M處理器
ARM Cortex-M處理器家族現在有8款處理器成員。在本文中,我們會比較Cortex-M系列處理器之間的產品特性,重點講述如何根據產品應用選擇正確的Cortex-M處理器。本文中會詳細的對照Cortex-M 系列處理器的指令集和高階中斷處理能力,以及 SoC系統級特性,除錯和追蹤功能和效能的比較。
1、簡介
今天, ARM Cortex-M 處理器家族有8款處理器成員。除此之外,ARM的產品系列還有很多其他的處理器成員。對很多初學者,甚至某些晶片設計經驗豐富但是不熟悉ARM系列處理器的設計者來說,也是很容易混淆這些產品的。不同的ARM 處理器有不同的指令集,系統功能和效能。本文會深入展現Cortex-M系列處理器之間的關鍵區別,以及它們和ARM其他系列處理器的不同。
1.1ARM處理器家族
多年來, ARM已經研發了相當多的不同的處理器產品。 如下圖中(圖1): ARM 處理器產品分為經典ARM處理器系列和最新的Cortex處理器系列。並且根據應用範圍的不同,ARM處理器可以分類成3個系列。
Application Processors(應用處理器)–面向移動計算,智慧手機,伺服器等市場的的高階處理器。這類處理器執行在很高的時鐘頻率(超過1GHz),支援像Linux,Android,MS Windows和移動作業系統等完整作業系統需要的記憶體管理單元(MMU)。 如果規劃開發的產品需要執行上述其中的一個作業系統,你需要選擇ARM 應用處理器.
Real-time Processors (實時處理器)
Microcontroller Processors(微控制器處理器)–微控制器處理器通常設計成面積很小和能效比很高。通常這些處理器的流水線很短,最高時鐘頻率很低(雖然市場上有此類的處理器可以執行在200Mhz之上)。 並且,新的Cortex-M處理器家族設計的非常容易使用。因此,ARM 微控制器處理器在微控制器和深度嵌入式系統市場非常成功和受歡迎。
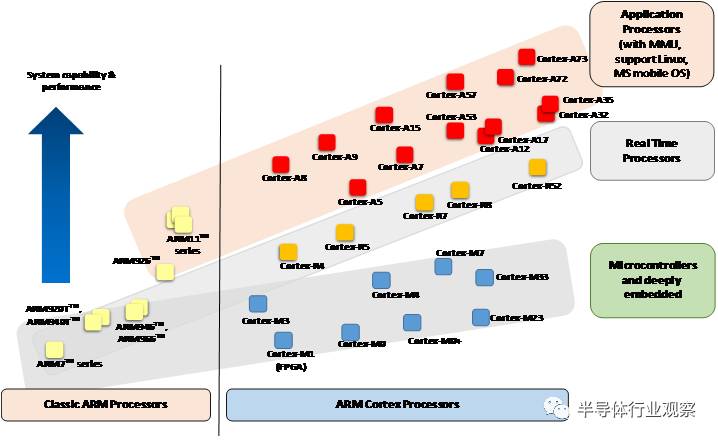
圖 1: 處理器家族
表1總結了三個處理器系列的主要特徵。
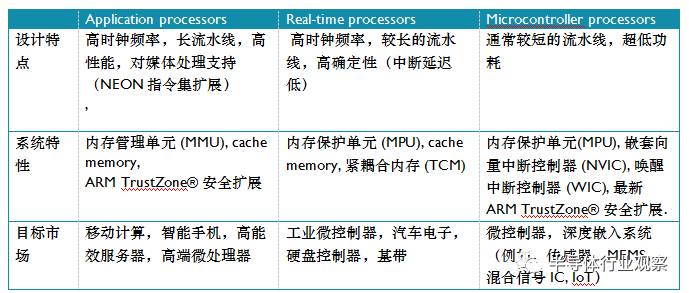
表 1: 處理器特性總結
1.2Cortex-M 處理器家族
Cortex-M處理器家族更多的集中在低效能端,但是這些處理器相比於許多微控制器使用的傳統處理器效能仍然很強大。例如,Cortex-M4和Cortex-M7處理器應用在許多高效能的微控制器產品中,最大的時鐘頻率可以達到400Mhz。
當然,效能不是選擇處理器的唯一指標。在許多應用中,低功耗和成本是關鍵的選擇指標。因此,Cortex-M處理器家族包含各種產品來滿足不同的需求:

表 2: Cortex-M 處理器家族
不同於老的經典ARM處理器(例如,ARM7TDMI, ARM9), Cortex-M處理器有一個非常不同的架構。例如:
-僅支援ARM Thumb®指令,已擴充套件到同時支援16位和32位指令Thumb-2版本
-內建的巢狀向量中斷控制負責中斷處理,自動處理中斷優先順序,中斷遮蔽,中斷巢狀和系統異常處理。
-中斷處理函式可以使用標準的C語言程式設計,巢狀中斷處理機制避免了使用軟體判斷哪一個中斷需要響應處理。同時,中斷響應速度是確定性的,低延遲的
-向量表從跳轉指令變為中斷和系統異常處理函式的起始地址。
-暫存器組和某些程式設計模式也做了改變。
這些變化意味著許多為經典ARM處理器編寫的彙編程式碼需要修改,老的專案需要修改和重新編譯才能遷移到Cortex-M的產品上。軟體移植具體的細節記錄在ARM文件:
ARM Cortex-M3 Processor Software Development for ARM7TDMI Processor Programmers
http://www.arm.com/files/pdf/Cortex-M3_programming_for_ARM7_developers.pdf
1.3Cortex-M系列處理器的共同特性
Cortex-M0, M0+, M3, M4 and M7之間有很多的相似之處,例如:
-基本程式設計模型 (章節 3.1)
-巢狀向量中斷控制器(NVIC)的中斷響應管理
-架構設計的休眠模式:睡眠模式和深度睡眠模式 (章節 4.1)
-作業系統支援特性 (章節 3.3)
-除錯功能 (章節 6)
-易用性
例如,巢狀向量中斷控制器是內建的中斷控制器
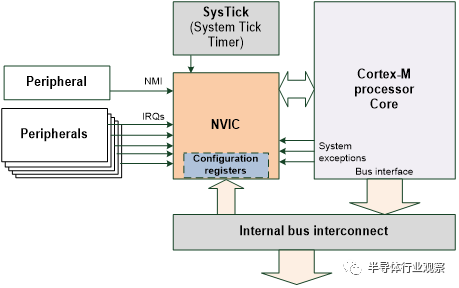
圖 2: Cortex-M處理器的巢狀向量中斷控制器
支援許多外圍裝置的中斷輸入,一個不可遮蔽的中斷請求,一個來自內建時鐘(SysTick)的中斷請求(見章節 3.3)和一定數量的系統異常請求。NVIC處理這些中斷和異常的優先順序和遮蔽管理。
NVIC以及異常處理模型的更多的內容在章節3.2描述。其他Cortex-M處理器間的異同點會在本文的其餘部分講解。
2、Cortex-M處理器指令集
2.1指令集簡介
大多數情況下,應用程式程式碼可以用C或其他高階語言編寫。但是,對Cortex-M 處理器支援指令集的基本瞭解有助於開發者針對具體應用選擇合適的Cortex-M處理器。指令集(ISA)是處理器架構的一部分,Cortex-M處理器可以分為幾個架構規範

表 3: Cortex-M 處理器ARM架構規範的規範
所有的Cortex-M 處理器都支援Thumb指令集。整套Thumb指令集擴充套件到Thumb-2版本時變得相當大。但是,不同的Cortex-M處理器支援不同的Thumb 指令集的子集,如圖3所示
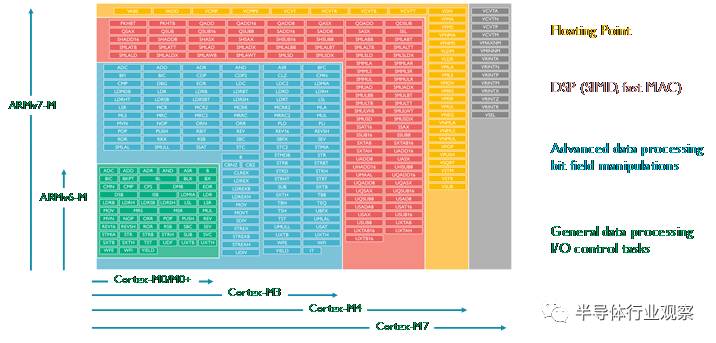

圖 3: Cortex-M 處理器的指令集
2.2Cortex-M0/M0+/M1指令集
Cortex-M0/M0+/M1處理器基於ARMv6-M架構。這是一個只支援56條指令的小指令集,大部分指令是16位指令,如圖3所示只佔很小的一部分。但是,此類處理器中的暫存器和處理的資料長度是32位的。對於大多數簡單的I/O控制任務和普通的資料處理,這些指令已經足夠了。這麼小的指令集可以用很少的電路門數來實現處理器設計,Cortex-M0 和 Cortex-M0+最小配置僅僅12K門。
然而,其中的很多指令無法使用高位暫存器(R8 到R12), 並且生成立即數的能力有限。這是平衡了超低功耗和效能需求的結果。
2.3Cortex-M3指令集
Cortex-M3處理器是基於ARMv7-M架構的處理器,支援更豐富的指令集,包括許多32位指令,這些指令可以高效的使用高位暫存器。另外,M3還支援:
-
查表跳轉指令和條件執行(使用IT指令)
-
硬體除法指令
-
乘加指令(MAC)
-
各種位操作指令
更豐富的指令集通過幾種途徑來增強效能;例如,32位Thumb指令支援了更大範圍的立即數,跳轉偏移和記憶體資料範圍的地址偏移。支援基本的DSP操作(例如,支援若干條需要多個時鐘週期執行的MAC指令,還有飽和運算指令)。最後,這些32位指令允許用單個指令對多個數據一起做桶型移位操作。
支援更豐富的指令導致了更大的面積成本和更高的功耗。典型的微控制器,Cortex-M3的電路門數是Cortex-M0 和 Cortex-M0+兩倍還多。但是,處理器的面積只是大多數現代微控制器的很小的一部分,多出來的面積和功耗經常不那麼重要。
2.4Cortex-M4指令集
Cortex-M4在很多地方和Cortex-M3相同:流水線,程式設計模型。Cortex-M4支援Cortex-M3的所有功能,並額外支援各種面向DSP應用的指令,像SIMD, 飽和運算指令,一系列單週期MAC指令(Cortex-M3只支援有限條MAC指令,並且是多週期執行的),和可選的單精度浮點運算指令。
Cortex-M4的SIMD操作可以並行處理兩個16位資料和4個8位資料。例如,圖4展示的QADD8 和 QADD16 操作:
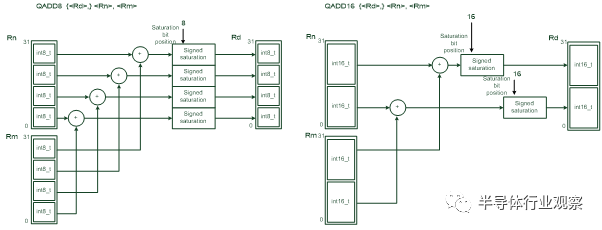
圖 4: SIMD指令例子: QADD8 and QADD16
The uses of SIMD enable much faster computation of 16-bit and 8-bit data in certain DSP operations as the calculation can be parallelized. However, in general programming, C compilers are unlikely to utilize the SIMD capability. That is why the typical benchmark results of the Cortex-M3 and Cortex-M4. However, the internal data path of the Cortex-M4 is different from Cortex-M3, which enable faster operations in a few cases (e.g. single cycle MAC, and allow write back of two registers in a single cycle).在某些DSP運算中,使用SIMD可以加速更快計算16位和8位資料,因為這些運算可以並行處理。但是,一般的程式設計中,C編譯器並不能充分利用SIMD運算能力。這是為什麼Cortex-M3 和 Cortex-M4典型benchmark的分數差不多。然而,Cortex-M4的內部資料通路和Cortex-M3的不同,某些情況下Cortex-M4可以處理的更快(例如,單週期MAC,可以在一個週期中寫回到兩個暫存器)。
2.5Cortex-M7指令集
Cortex-M7支援的指令集和Cortex-M4相似,添加了:
-
浮點資料架構是基於FPv5的,而不是Cortex-M4的FPv4,所以Cortex-M7支援額外浮點指令
-
可選的雙精度浮點資料處理指令
-
支援快取資料預取指令(PLD)
Cortex-M7的流水線和Cortex-M4的非常不同。Cortex-M7是6級雙發射流水線,可以獲得更高的效能。多數為Cortex-M4設計的軟體可以直接執行在Cortex-M7上。但是,為了充分利用流水線差異來達到最好的優化,軟體需要重新編譯,並且在許多情況下,軟體需要一些小的升級,以充分利用像Cache這樣的新功能。
2.6Cortex-M23指令集
Cortex-M23的指令集是基於ARMv8-M的Baseline子規範,它是ARMv6-M的超集。擴充套件的指令包括:
-
硬體除法指令
-
比較和跳轉指令,32位跳轉指令
-
支援TrustZone安全擴充套件的指令
-
互斥資料訪問指令(通常用於訊號量操作)
-
16位立即數生成指令
-
載入獲取及儲存釋放指令(支援C11)
在某些情況下,這些增強的指令集可以提高處理器效能,並且對包含多個處理器的SoC設計有用(例如,互斥訪問對多處理器的訊號量處理有幫助)
2.7I Cortex-M33指令集
因為Cortex-M33設計是非常可配置的,某些指令也是可選的。例如:
-
DSP指令(Cortex-M4 和Cortex-M7支援的)是可選的
-
單精度浮點運算指令是可選的,這些指令是基於FPv5的,並且比Cortex-M4多幾條。
: Cortex-M33也支援那些ARMv8-M Mainline引入的新指令:
-
支援TrustZone安全擴充套件的指令
-
載入獲取及儲存釋放指令(支援C11)
2.8指令集特性比較總結
ARMv6-M, ARMv7-M 和 ARMv8-M架構有許多指令集功能特點, 很難介紹到所有的細節。但是,下面的表格(表4)總結了那些關鍵的差異。
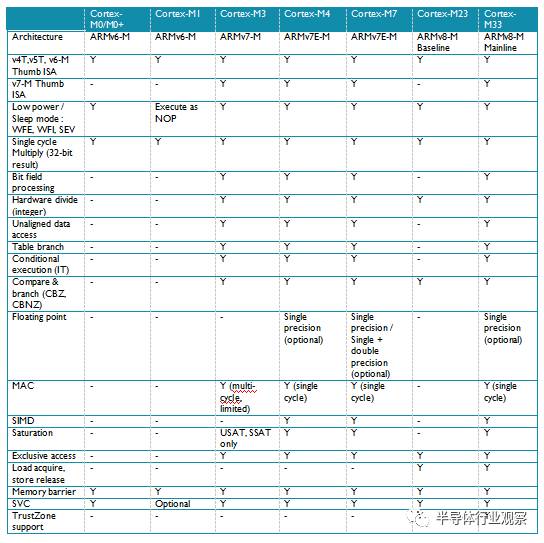
表 4: 指令集特性總結
Cortex-M處理器指令集的最重要的特點是向上相容。Cortex-M3的指令是Cortex-M0/M0+/M1的超集。所以,理論上講,如果儲存空間分配是一致的,執行在Cortex-M0/M0+/M1上的二進位制檔案可以直接執行在Cortex-M3上。同樣的原理也適用於Cortex-M4/M7和其他的Cortex-M處理器;Cortex-M0/M0+/M1/M3支援的指令也可以執行在Cortex-M4/M7上。
雖然Cortex-M0/M0+/M1/M3/M23處理器沒有浮點運算單元配置選項,但是處理器仍然可以利用軟體來做浮點資料運算。這也適用於基於Cortex-M4/M7/M33但是沒有配置浮點運算單元的產品。在這種情況下,當程式中使用了浮點數,編譯工具包會在連結階段插入需要的執行軟體庫。軟體模式的浮點運算需要更長的執行時間,並且會略微的增加程式碼大小。但是,如果浮點運算不是頻繁使用的,這種方案是適合這種應用的。
3、架構特性
3.1程式設計模型
Cortex-M處理器家族的程式設計模型是高度一致的。例如所有的Crotex-M處理器都支援R0到R15,PSR, CONTROL 和 PRIMASK。兩個特殊的暫存器— FAULTMASK 和 BASEPRI—只有Cortex-M3, Cortex-M4, Cortex-M7 和 Cortex-M33支援;浮點暫存器組和FPSCR(浮點狀態和控制暫存器)暫存器,是Cortex-M4/M7/M33可選的浮點運算單元使用的。
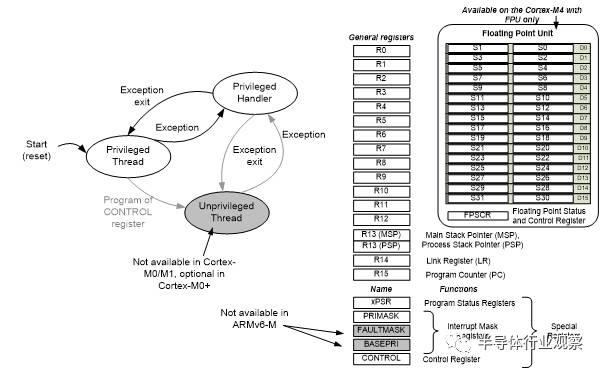
圖 5: 程式設計模型
BASEPRI暫存器允許程式阻止指定優先順序或者低的優先順序中斷和異常。對ARMv7-M來說這是很重要的,因為Cortex-M3, Cortex-M4, Cortex-M7 和 Cortex-M33有大量的優先順序等級,而ARMv6-M 和 ARMv8-M Baseline只有有限的4個優先等級。FAULTMASK通常用在複雜的錯誤處理上(檢視章節3.4)
非特權級別的實現對ARMv6-M處理器是可選的,對ARMv7-M 和ARMv8-M處理器一直支援的。對Cortex-M0+處理器,它是可選的, Cortex-M0 and Cortex-M1不支援這個功能。這意味著在各種Cortex-M處理器的CONTROL 暫存器是稍微不同的。FPU的配置也會影響到CONTROL暫存器,如圖6所示。
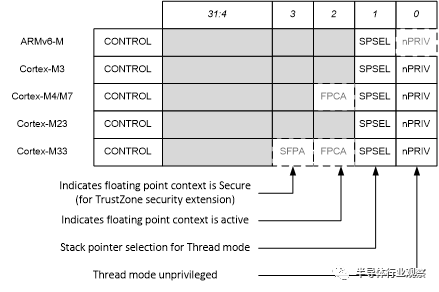
圖 6: CONTROL 暫存器
另外一個程式設計模型之間的不同是PSR暫存器(程式狀態暫存器)的細節。所有的Cortex-M處理器,PSR暫存器都被再分成應用程式狀態暫存器(APSR),執行程式狀態暫存器(EPSR)和中斷程式狀態暫存器(IPSR)。 ARMv6-M 和 ARMv8-M Baseline系列的處理器不支援APSR的Q位和EPSR的ICI/IT位。ARMv7E-M系列 ( Cortex-M4, Cortex-M7) 和ARMv8-M Mainline (配置了DSP擴充套件的Cortex-M33 )支援GE位。另外,ARMv6-M系列處理器IPSR的中斷號數字範圍很小,如圖7所示。
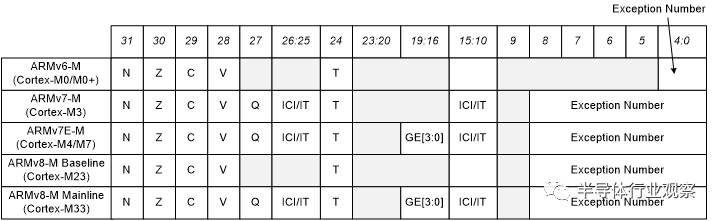
圖 7: PSR 差異
請注意Cortex-M的程式設計模型和ARM7TDMI等這些經典的ARM處理器是不一樣的。除了暫存器組不同外,經典ARM處理器中“模式”和“狀態”的定義與Cortex-M中的也是不同的。Cortex-M只有兩個模式:執行緒模式(Thread)和管理者模式(Handler),並且Cortex-M處理器一直執行在Thumb狀態(不支援ARM指令)
3.2異常處理模型和巢狀向量中斷控制器NVIC
所有的Cortex-M處理器都包含了NVIC模組,採用同樣的異常處理模型。如果一個異常中斷髮生,它的優先等級高於當前執行等級,並且沒有被任何的中斷遮蔽暫存器遮蔽,處理器會響應這個中斷/異常,把某些暫存器入棧到當前的堆疊上。這種堆疊機制下,中斷處理程式可以編寫為一個普通的C函式,許多小的中斷處理函式可以立即直接響應工作而不需要額外的堆疊處理花銷。
一些ARMv7-M/ARMv8-M Mainline系列的處理器使用的中斷和系統異常並不被ARMv6-M/ARMv8-M Baseline的產品支援,如圖8. 例如,Cortex-M0, M0+ 和M1的中斷數被限制在32個以下,沒有除錯監測異常,錯誤異常也只限於HardFault(錯誤處理細節請參看章節3.4)。相比之下,Cortex-M23, Cortex-M3, Cortex-M4 和Cortex-M7處理器可以支援到多達240個外圍裝置中斷。Cortex-M33支援最多480箇中斷。
另外一個區別是可以使用的優先等級數量:
ARMv6-M 架構 - ARMv6-M支援2級固定的(NMI 和 HardFault)和4級可程式設計的(由每個優先等級暫存器的兩個位表示)中斷/異常優先順序。這對大多數的微控制器應用來說足夠了。
ARMv7-M 架構 - ARMv7-M系列處理器的可程式設計優先順序等級數範圍,根據面積的限制,可以配置成8級(3位)到256級(8位)。ARMv7-M處理器還有一個叫做中斷優先順序分組的功能,可以把中斷優先順序暫存器再進一步分為組優先順序和子優先順序,這樣可以詳細地制定搶佔式優先順序的行為。
ARMv8-M Baseline – 類似 ARMv6-M,M23也有2位的優先順序等級暫存器。藉助可選的TrustZone安全擴充套件元件,安全軟體可以把非安全環境中的中斷的優先等級轉換到優先等級區間的下半區,這就保證了安全環境中的某些中斷/異常總是比非安全環境中的優先順序要高。
ARMv8-M Mainline – 類似於 ARMv7-M。 可以支援8到256箇中斷優先等級和中斷優先順序分組。還支援ARMv8-M Baseline具有的優先等級調整功能。
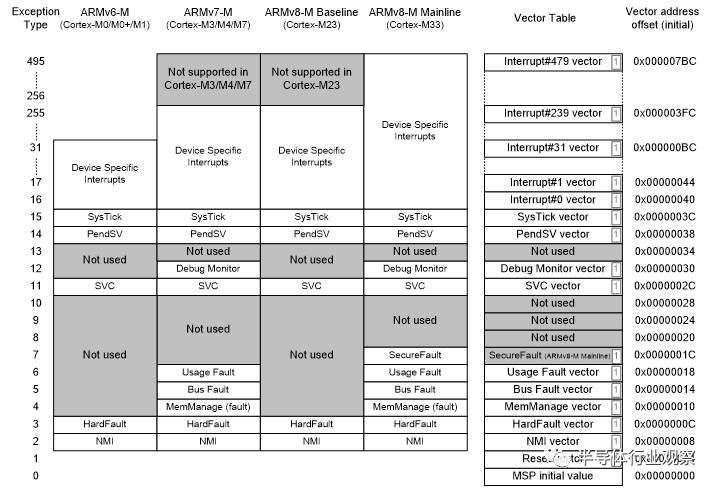
圖 8: Cortex-M 處理器異常中斷型別
所有的Cortex-M處理器在異常處理是都要依靠向量表。向量表儲存著異常處理函式的起始地址(如圖8所示)。向量表的起始地址由名為向量表偏移暫存器(VTOR)決定。
-
Cortex-M0+, Cortex-M3 and Cortex-M4 processors: by default the vector table is located in the starting of the memory map (address 0x0). Cortex-M0+, Cortex-M3 and Cortex-M4: 向量表預設放在儲存空間的起始地址(地址 0x0)。
-
In Cortex-M7, Cortex-M23 and Cortex-M33 processors: the default value for VTOR is defined by chip designers. Cortex-M23 and Cortex-M33 processors can have two separated vector tables for Secure and Non-secure exceptions/interrupts. Cortex-M7, Cortex-M23 and Cortex-M33:VTOR的初始值由晶片設計者定義。Cortex-M23 and Cortex-M33處理器面向安全和非安全的異常/中斷有兩個獨立的向量表。
-
Cortex-M0 and Cortex-M1 does not implement programmable VTOR and vector table starting address is always 0x00000000. Cortex-M0 and Cortex-M1沒有實現可程式設計的VTOR,向量表起始地址一直為0x00000000。
Cortex-M0+ 和 Cortex-M23處理器的VTOR是可選項。如果VTOR被實現了,向量表的起始地址可以通過設定VTOR來改變,這個功能對下列情況有用:
-
重定位向量表到SRAM來實現動態改變異常處理函式入口點
-
重定位向量表到SRAM來實現更快的向量讀取(如果flash儲存器很慢)
-
重定位向量表到ROM不同位置(或者Flash),不同的程式執行階段可以有不同的異常處理程式
不同的Cortex-M處理器之間的NVIC程式設計模型也有額外的不同。差異點總結在表 5中:
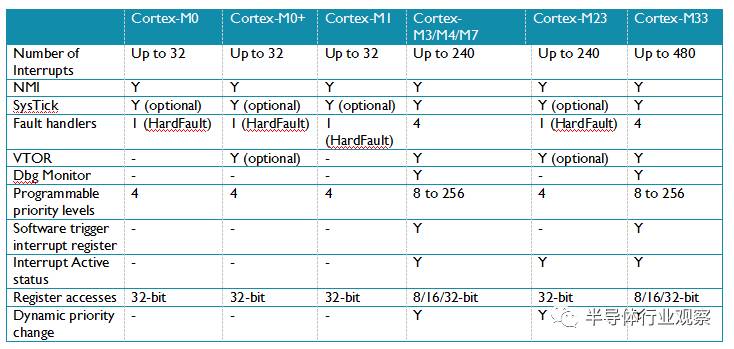
表 5: NVIC 程式設計模型和特性差異
大部分情況下,對NVIC的中斷控制特性的操作都是通過CMSIS-CORE提供的APIs處理的,他們在微控制器廠商提供的裝置驅動程式庫裡。對Cortex-M3/M4/M7/M23/M33處理器,即使中斷被使能了,它的優先順序也可以被改變。ARMv6-M處理器不支援動態優先等級調整,當你需要改變中斷優先等級是,需要暫時的關掉這個中斷。
3.3作業系統支援特性
Cortex-M處理器架構在設計時就考慮到了作業系統的支援。針對作業系統的特性有:
-
影子堆疊指標
-
系統服務呼叫(SVC)和可掛起系統呼叫(PenSV)異常
-
SysTick – 24位遞減計時器,為作業系統的計時和任務管理產生週期性的異常中斷
-
Cortex-M0+/M3/M4/M7/M23/M33支援的非特權執行和儲存保護單元(MPU)
系統服務呼叫(SVC)異常由SVC指令觸發,他可以讓執行在非特權狀態的應用任務啟動特權級的作業系統服務。可掛起系統呼叫異常在作業系統中像上下文切換這樣的非關鍵操作的排程非常有幫助。
為了能把Cortex-M1放到很小的FPGA器件中,所有用來支援作業系統的特性對Cortex-M1都是可選的。對Cortex-M0, Cortex-M0+ 和Cortex-M23處理器,系統時鐘SysTick是可選的。
通常,所有的Cortex-M處理器都支援作業系統。執行在Cortex-M0+, Cortex-M3, Cortex-M4, Cortex-M7, Cortex-M23 和 Cortex-M33的應用可以執行在非特權執行狀態,並且可以同時利用可選的儲存器管理單元(MPU)以避免記憶體非法訪問。這可以增強系統的魯棒性。
3.4TrustZone安全擴充套件
近幾年來, 物聯網(IoT)成為了嵌入式系統開發者們的熱門話題。IoT系統產品變得更加複雜,上市時間的壓力也與日俱增。嵌入式系統產品需要更好的方案來保證系統的安全,但是同時又要方便軟體開發者開發。傳統的方案是通過把軟體分成特權和非特權兩部分解決的,特權級軟體利用MPU防止非特權的應用訪問包含安全敏感資訊在內的的關鍵的系統資源。這種方案對一些IoT系統非常適合,但是在一些情況下,只有兩層劃分是不夠的。特別是那些包含很多複雜特權級別的軟體元件的系統,特權級的程式碼的一個缺陷就可以導致黑客徹底的控制這個系統
ARMv8-M架構包含了一個叫做TrustZone的安全擴充套件,TrustZone匯入了安全和非安全狀態的正交劃分。
-
普通應用是非安全態
-
軟體元件和安全相關的資源(例如,安全儲存,加密加速器,正隨機數發生器(TRNG))處在安全狀態。
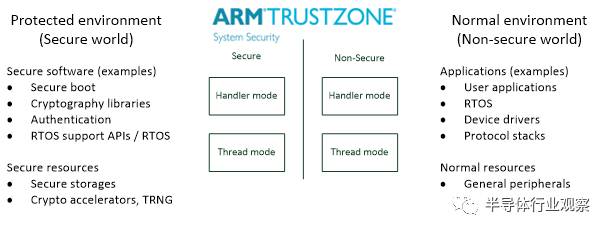
圖 9: 安全狀態和非安全狀態的隔離
非安全狀態的軟體只能訪問非安全狀態的儲存空間和外圍裝置,安全軟體可以訪問兩種狀態下的所有資源。
用這種方案,軟體開發者可以用以往的方式開發非安全環境下的應用程式。同時,他們可以藉助晶片廠商提供的安全通訊軟體庫執行安全物聯網連線。並且即使執行在非安全環境的特權級的程式有漏洞,TrustZone安全機制可以阻止黑客控制整個裝置,限制了攻擊的影響,還可以實現系統遠端恢復。此外,ARMv8-M架構也引入了堆疊邊界檢查和增強的MPU設計,促使額外安全措施的採用。
安全架構定義也擴充套件到了系統級別,每個中斷都可以被設定為安全或者非安全屬性。中斷異常處理程式也會自動儲存和恢復安全環境中的暫存器資料以防止安全資訊洩露。所以,TrustZone安全擴充套件讓系統能夠支援實時系統的需求,為IoT應用提供了堅實的安全基礎,並且容易讓軟體開發在此技術上開發應用程式。
TrustZone模組對Cortex-M23 and Cortex-M33處理器是可選的。關於ARMv8-M TrustZone更多的資訊請查詢The Next Steps in the Evolution of Embedded Processors for the Smart Connected Era。更多的TrustZone的資源請檢視community.arm.com網站上的“TrustZone for ARMv8-M Community”,
3.5錯誤處理
ARM處理器和其他架構的微控制器的一個區別是錯誤處理能力。當錯誤被檢測到時,一個錯誤異常處理程式被觸發去執行恰當的處理。觸發錯誤的情況可能是:
-
未定義的指令(例如,Flash儲存器損壞)
-
訪問非法地址空間(例如,堆疊指標崩潰)或者MPU非法訪問
-
非法操作(例如,當處理器已經在優先順序高於SVC的中斷中試圖觸發SVC異常)
錯誤處理機制使嵌入式系統能夠更快的響應各種問題。否則,如果系統宕機了,看門狗定時需要非常長的時間重啟系統。
ARMv6-M架構中,所有的錯誤事件都會觸發HardFault處理程式,它的優先順序是-1(優先順序比所有的可程式設計異常都高,但是僅低於非遮蔽中斷NMI)。 所有的錯誤事件都被認為是不可恢復的,通常我們在HardFault處理程式中僅執行錯誤報告然後進一步觸發自動復位。
ARMv8-M Baseline架構和ARMv6-M類似,只有一個錯誤異常(HardFault)。但是ARMv8-M Baseline的HardFault優先順序可以是-1或者當實現了TrustZone安全擴充套件時優先順序是-3.
ARMv7-M 和 ARMv8-M Mainline產品除了HardFault還有幾個可配置的錯誤異常:
-
Memmanage(記憶體管理錯誤)
-
匯流排錯誤(匯流排返回錯誤的響應)
-
用法錯誤(未定義指令或者其他的非法操作)
-
SecureFault(只用ARMv8-M Mainline產品支援,處理TrustZone安全擴充套件中的安全非法操作)
這些異常的優先順序可以程式設計改變,可以單獨的開啟和關掉。如果需要,它們也可以利用FAULTMASK暫存器把它們的優先順序提高到和HardFault相同的級別。ARMv7-M 和 ARMv8-M Mainline產品還有幾個錯誤狀態暫存器可以提供關於觸發錯誤異常事件的線索和錯誤地址的暫存器,用來確定觸發這個錯誤異常的訪問地址,使除錯更加容易。
ARMv7-M 和 ARMv8-M Mainline產品子規範中額外的錯誤處理程式提供了靈活的錯誤處理能力,錯誤狀態暫存器讓錯誤事件的定位和除錯更加容易。很多商業開發套件中的偵錯程式已經內嵌了使用錯誤狀態暫存器來診斷錯誤事件的功能。此外,錯誤處理程式可以在執行時做一些修復工作。
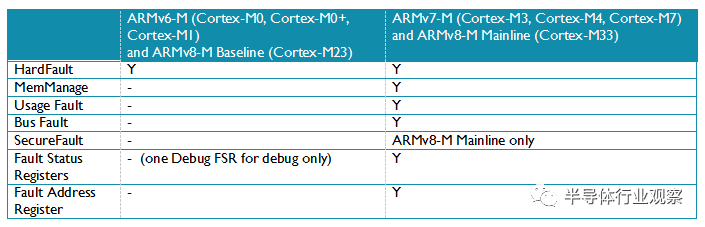
表 6: 錯誤處理特性比較總結
4、系統特性
4.1低功耗
低功耗是Cortex-M處理器的一個關鍵優點。低功耗是其架構的組成部分:
-
WFI和WFE指令
-
架構級的休眠模式定義
此外,Cortex-M支援許多其他的低功耗特性:
-
休眠和深度休眠模式:架構級支援的特性,通過裝置特定的功耗管理暫存器可以進一步擴充套件。
-
Sleep-on-exit模式:中斷驅動的應用的低功耗技術。開啟設定後,當異常處理程式結束並且沒有其他等待處理的異常中斷時,處理器自動進入到休眠模式。這樣避免了額外的執行緒模式中指令的執行從而省電,並且減少了不必要的堆疊讀寫操作。
-
喚醒中斷控制器(WIC):一個可選的特性,在特定的低功耗狀態,由一個獨立於處理器的小模組偵測中斷情況。例如,在狀態保留功耗管理(SRPG)設計中,當處理器被關電的設計。
-
時鐘關閉和架構級時鐘關閉:通過關閉處理器的暫存器或者子模組的時鐘輸入來省電
所有這些特性都被Cortex-M0, Cortex-M0+, Cortex-M3, Cortex-M4, Cortex-M7, Cortex-M23 和 Cortex-M33支援。此外,各種低功耗設計技術被用來降低處理器功耗。
因為更少的電路,Cortex-M0 and Cortex-M0+處理器比Cortex-M3, Cortex-M4 和 Cortex-M7功耗低。此外,Cortex-M0+額外優化減少了程式存取(例如跳轉備份)來保持系統層級的低功耗。
Cortex-M23沒有Cortex-M0 和 Cortex-M0+那麼小,但是在相同的配置下,仍然和Cortex-M0+能效一樣。
由於更好效能和低功耗優化,在相同配置下,Cortex-M33比Cortex-M4能效比更好。
4.2Bit-band feature位段
Cortex-M3 和Cortex-M4處理器支援一個叫做位段的可選功能,允許有兩段通過位段別名地址實現可以位定址的1MB的地址空間(一段在從地址0x20000000起始的SRAM空間。另一段是從地址0x40000000起始的外圍裝置空間)。Cortex-M0, M0+ 和 Cortex-M1不支援位段(bit-band)功能,但是可以利用ARM Cortex-M系統設計套件(CMSDK)中的匯流排級元件在系統層面實現位段(bit-band)功能。Cortex-M7不支援位段(bit-band),因為M7的Cache功能不能與位段一塊使用(Cache控制器不知道記憶體空間的別名地址)。
ARMv8-M的TrustZone 不支援位段, 這是由於位段別名需要的兩個不同的地址可能會在不同的安全域中。對於這些系統,外圍裝置資料的位操作反而可以在外圍裝置層面處理(例如,通過新增位設定和清除暫存器)。
4.3儲存器保護單元(MPU)
除了Cortex-M0, 其他的Cortex-M處理器都有可選的MPU來實現儲存空間訪問許可權和儲存空間屬性或者儲存區間的定義。執行實時作業系統的嵌入式系統, 作業系統會每個任務定義儲存空間訪問許可權和記憶體空間配置來保證每個任務都不會破壞其他的任務或者作業系統核心的地址空間。Cortex-M0+, Cortex-M3 和 Cortex-M4都有8個可程式設計區域空間和非常相似的程式設計模型。主要的區別是Cortex-M3/M4的MPU允許兩級的儲存空間屬性(例如,系統級cache型別),Cortex-M0+僅支援一級。Cortex-M7的MPU可以配置成支援8個或者16個區域,兩級的儲存空間屬性。Cortex-M0 和 Cortex-M1不支援MPU.
Cortex-M23 和 Cortex-M33也支援MPU選項,如果實現了TrustZone安全擴充套件(一個用於安全軟體程式,另一個用於非安全軟體程式)可以有最多兩個MPU。
4.4單週期I/O介面
單週期I/O介面是Cortex-M0+處理器獨特的功能,這使Cortex-M0+可以很快的執行I/O控制任務。Cortex-M大多數的處理器的匯流排介面是基於AHB Lite或者AHB 5協議的,這些介面都是流水實現匯流排協議,執行在高時鐘頻率。但是,這意味著每個傳輸需要兩個時鐘週期。單時鐘週期I/O介面添加了額外的簡單的非流水線匯流排介面,連線到像GPIO(通用輸入輸出)這樣的一部分裝置特定的外設上。結合單週期I/O和Cortex-M0+天然比較低的跳轉代價(只有兩級流水線),許多I/O控制操作都會比大多數其他微控制器架構的產品執行的更快。
5、效能考慮
5.1通用資料處理能力
在通用微控制器市場,benchmark資料經常用來衡量微控制器的效能,表7是Cortex-M處理器常用benchmark測試的效能資料:
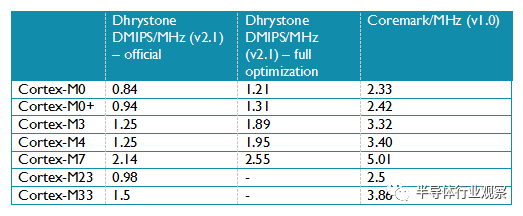
表 7: Cortex-M處理器常用benchmakr的效能分數(來源:CoreMark.org 網站 and ARM 網站)
關於Dhrystone需要注意的是用來測試的Dhrystone是由官方源程式在沒有啟用inline and 和multi-file compilation編譯選項的情況編譯出來的(官方分數)。但是,很多微控制器廠商引用的是完全優化編譯的Dhrystone測試出來的資料。
但是,benchmark工具的效能測試資料可能無法準確反應你的應用能達到的效能。例如,單週期I/O介面和DSP應用中使用SIMD,或者Cortex-M4/M7中使用FPU的加速效果並沒有在這些測試資料中體現出來。
通常,Cortex-M3 和 Cortex-M4由於以下原因提供了更高的資料處理效能:
-
更豐富的指令集
-
哈佛匯流排架構
-
寫快取(單週期寫操作)
-
跳轉目標的預測取指
Cortex-M33也是基於哈佛匯流排的架構,有豐富的指令集。但是不像Cortex-M3 和 Cortex-M4,Cortex-M33處理器流水線是重新設計的高效流水線,支援有限的指令雙發射(可以在一個時鐘週期中執行最多兩條指令)。
Cortex-M7支援更高的效能,這是因為M7擁有雙發射六級流水線並支援分支預測。而且,通過支援指令和資料Cache,和即便使用慢速記憶體(例如,嵌入式Flash)也能避免效能損失的緊耦合記憶體,來實現更高的系統級效能。
但是,某些I/O操作密集的任務在Cortex-M0+上執行更快,這是因為:
-
更短的流水線(跳轉只需要兩個週期)
-
單週期I/O埠
當然也有裝置相關的因素。例如,系統級設計,記憶體的速度也會影響到系統的效能。
你自己的應用程式經常是你需要的最好的benchmark。CoreMark分數是另外一個處理器兩倍的處理器並不意味著執行你的應用也快一倍。對I/O密集操作的應用來說,裝置相關的系統級架構對效能有巨大的影響。
5.2中斷延遲
效能相關的另外一個指標是中斷延遲。這通常用從中斷請求到中斷服務程式第一條指令執行的時鐘週期數來衡量。表8列出了Cortex-M處理器在零等待記憶體系統條件下的中斷延遲比較。
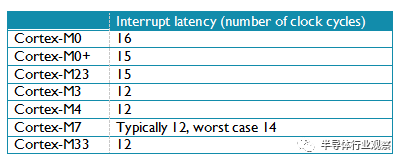
表 8: 零等待記憶體系統條件下的中斷延遲比較
事實上,真正的中斷延遲受到記憶體系統等待狀態的影響。例如,許多執行頻率超過100Mhz的微控制器搭配的是非常慢的Flash儲存器(例如30到50MHz)。雖然使用了Flash訪問加速硬體來提高效能,中斷延遲仍然受到Flash儲存系統等待狀態的影響。所以完全有可能執行在零等待記憶體系統Cortex-M0/M0+系統比Cortex-M3/M4/M7有更短的中斷延遲。
當評估效能的時候,不要忘記把中斷處理程式的執行時間考慮在內。某些8位或者16位處理器架構可能中斷延遲很短,但是會花費數倍的時鐘週期完成中斷處理。非常短的中斷響應時間和很短的中斷處理時間才是實際有效的。