
lucene4.5原始碼分析系列:分析器
分析器是lucene中非常重要的一個元件,許多包都是分析器的子包,這是因為分析器需要支援很多不同的語言。
lucene中的分析器
分析器可能會做的事情有:將文字拆分為單詞,去除標點,將字母變為小寫,去除停用詞,詞幹還原,詞形歸併,敏感詞過濾等等。lucene中預設自帶的分析器有4個:WhitespaceAnalyzer,SimpleAnalyzer,StopAnalyzer, StandardAnalyzer,分別用來過濾空白字元,過濾空白符並自動變小寫,去掉停用詞,標準化分詞。其中,最常用的是StandardAnalyzer。分析器之所以能做這麼多事,與之簡潔而強大的類設計是分不開的。
事實上,這部分就使用了一個裝飾器模式,但是由此可以做許多事情,因為filter可以不停的新增新功能。下面是類結構圖。
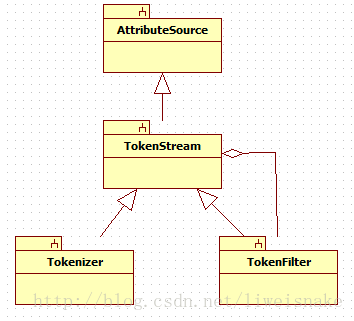
Analyzer中最重要的就是tokenStream方法,它得到一個TokenStream物件。這個方法最開始從reuseStrategy中取得一個TokenStreamComponent,reuseStrategy是重用的策略,預設有兩個實現GLOBAL_REUSE_STRATEGY和PER_FIELD_REUSE_STRATEGY,前者讓所有field共用一個TokenStreamComponent,後者每個field一個TokenStreamComponent,而實際儲存這些Component的地方是Analyzer中的storedValue。接下來初始化reader並設定到component。最後從component得到TokenStream
public final TokenStream tokenStream(final String fieldName, final Reader reader) throws IOException { TokenStreamComponents components = reuseStrategy.getReusableComponents(this, fieldName); final Reader r = initReader(fieldName, reader); if (components == null) { components = createComponents(fieldName, r); reuseStrategy.setReusableComponents(this, fieldName, components); } else { components.setReader(r); } return components.getTokenStream(); }
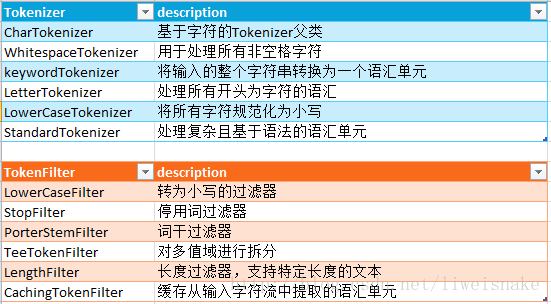
下面是lucene中一些Tokenizer和TokenFilter的列表。無論從名字還是實現都相對簡單,這裡就不過多分析了。
分詞
接下來來看看分析器的一個比較重要的功能,分詞。所謂分詞,就是為了便於倒排索引的查詢而將一個句子切分為一個一個的term,切分的最好標準就是每個詞儘量符合它在句子中語義,但實際上往往是很難達到的。大家可以試想一下,如果是一句英文的句子,那麼一種簡單的分詞方式可以用split(" "),這樣英文中的每個單詞就是一個term。但是如果是一句中文,我們能夠每個字一個term嗎?如果這樣,那搜素出來的肯定牛頭不對馬嘴。因為漢語中的單詞通常是片語,片語才是組成確定語義的單位。因而如何分詞就是需要注意的問題了。
關於中文分詞,目前大概有這樣幾種方法:
1. 基於字串匹配的分詞方法。比較著名的幾個開源專案有IkAnalyzer和paoding。
這種分詞方法簡單來講就是用待分詞的句子與詞典中的詞進行匹配,找出最合適的匹配。這種方式實現的分詞,優點是快速;但制約因素是詞典本身要好,而且不在詞典中的詞就無法匹配,因為是純粹匹配,碰上歧義時分詞器本身也不認識到底應該識別哪一個,因而消除歧義的能力較差。比如知乎上的這樣一段測試文字,中間有很多歧義的部分:“工信處女幹事每月經過下屬科室都要親口交代24口交換機等技術性器件的安裝工作”。這樣的識別對這類分詞器而言是比較大的挑戰。
分詞按照方向可以分為正向或者逆向,按照匹配的貪婪程度,可以分為最大匹配,最少次數劃分(有分詞理論),最細粒度匹配。之所以會有這些劃分,是因為基於字串匹配的演算法通常能夠解決一類問題,但是另一類會差一些。而按照這樣的劃分,能夠給予分詞一定的啟發式規則。
以上面的句子為例,如果隨意劃分,那麼開頭就會是"工信/處女/幹事...",顯然是有問題的。
按照最大匹配劃分,就是"工信處/女/幹事",但是最大匹配劃分也有問題,matrix67的文中有個例子"北京大學生前來應聘"會被劃分為"北京大學/生前/來/應聘",這也是有問題的。
所以有逆向的匹配,比如上面這句,就可以匹配成"北京/大學生/前來/應聘"。
另一種劃分方式,就是最細粒度劃分,還是以最初的歧義句子為例,它可以被最細粒度劃分為"工信/處女/幹事/每月/月經/經過...",可以看到它並沒有消除歧義,只是增加了搜尋到這個句子的詞。
以上這些方式實際上都是可以舉出反例的,其實就是讓中國人來聽,漢語也只有76%的準確度。
講講幾個開源專案IkAnalyzer, paoding和mmseg。
IkAnalyzer是用的正向迭代最細粒度切分演算法以及一個智慧分詞法,目前IkAnalyzer實際上是比較活躍的,作者也經常更新。
paoding實際上在2010年更新了一版支援lucene3.0之後就銷聲匿跡了。
mmseg的演算法也挺有意思,它有下面4條啟發式的消除歧義規則:
1)備選詞組合的長度之和最大。
2)備選詞組合的平均詞長最大;
3)備選詞組合的詞長變化最小;
4)備選詞組合中,單字詞的出現頻率統計值最高。
最開始它從左到右掃描一遍,識別出3個詞的不同組合,然後用上面4條規則匹配出最好的一個片語,然後再次用這4條規則匹配剩下的詞,這樣消歧能力有明顯的提高。參考中有篇文章介紹mmseg,不過居然是96年發表的
2. 基於統計和機器學習的分詞。比如CRF,HMM(隱式馬爾科夫模型),MEMM(最大熵隱馬模型)。
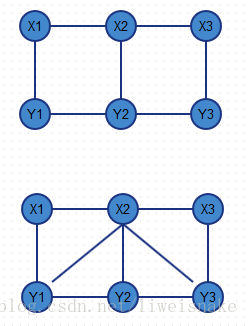
這種分詞方式在最初需要提供一個訓練集去喂,這個訓練集就是已經標註好的分詞片語,然後在分詞階段通過構建模型來計算各種可能分法的概率,通過概率來最終判斷。實際上,這是目前公認的比較準確的方式。CRF即條件隨機場(Conditional Random Field),在《數學之美》中已經對其描述過。可以想象,這個訓練集對於分詞的準確性也是非常重要的。CRF比隱馬模型好在,隱馬模型由於簡化,每個觀察值只考慮到了當前狀態,而條件隨機場則是考慮到了前後的狀態。通俗的講,隱馬模型對於現在的輸出也只考慮現在的條件;而CRF對於現在的輸出需要考慮過去,現在和未來的條件。如圖,上面是隱馬模型,對於觀測值x2,只取決於產生的狀態y2;下圖則是條件隨機場,x2不僅取決於y2,還取決於y1以及y3.
CRF最初是被用來對一個句子做句法成分分析的,比如:我愛地球,通過條件隨機場能判斷出句子成分是:主語/謂語/賓語。而這個判斷的過程是一個分類的過程。如果我們將這個分類換成一個4標記B, S, M, E的方式
- 詞首,常用B表示
- 詞中,常用M表示
- 詞尾,常用E表示
- 單子詞,常用S表示
中文分詞之trie樹 http://blog.csdn.net/wzb56_earl/article/details/7902669
數學之美--談談中文分詞