
【實戰分享】又拍雲 OpenResty / Nginx 服務優化實踐
2018 年 11 月 17 日,由 OpenResty 主辦的 OpenResty Con 2018 在杭州舉行。本次 OpenResty Con 的主題涉及 OpenResty 的新開源特性、業界最佳實踐、效能優化、Trace、 API 閘道器等方面。
又拍雲受邀參加 OpenResty Con 2018,又拍雲系統開發工程師張超在大會上做了《又拍雲 OpenResty / Nginx 服務優化實踐》的開場演講。
又拍雲在自身業務中大量使用了 Nginx、OpenResty,使用兩者開發了雲處理、雲端儲存業務平臺,並在又拍雲 CDN 平臺中使用 ngx_lua 作為反向代理服務, CDN 平臺的 API、檔案上傳服務通過 ngx_lua 對大檔案進行流式上傳,利用 ngx_lua 對網路線路進行動態的排程,自動選擇最合適的線路進行上傳加速。同時,又拍雲在 Github 上也一直儲存、更新著又拍雲所報告和修復的關於 Nginx 和 OpenResty 的 bug,是 OpenResty 重要的貢獻者。

△ 又拍雲系統開發工程師張超
張超,又拍雲系統開發工程師,負責又拍雲 CDN 平臺反向代理層元件的開發和維護。Nginx、OpenResty 等開源軟體愛好者。本次分享著重介紹了又拍雲 CDN 平臺在不斷的更新迭代中總結出的關於 OpenResty 和 Nginx 服務優化的經驗,包括構建容器化的生產環境效能分析環境、整合 SSL 硬體加速至 OpenResty 及其陷阱等案例。
分享主要分三塊展開:
- 關於效能分析、 Tips 以及使用 Nginx 編碼的注意點,使應用程式碼能夠獲得更好的執行效能;
- 又拍雲對 DNS 的解析管理;
- SSL 硬體加速的實踐,側重介紹在使用過程中與 LuaJIT 的衝突及解決思路。
以下是分享實錄:
又拍雲和 OpenResty 的那些事
又拍雲從 2013 年就開始關注並且使用 OpenResty ,是最早使用 OpenResty 的廠商之一。
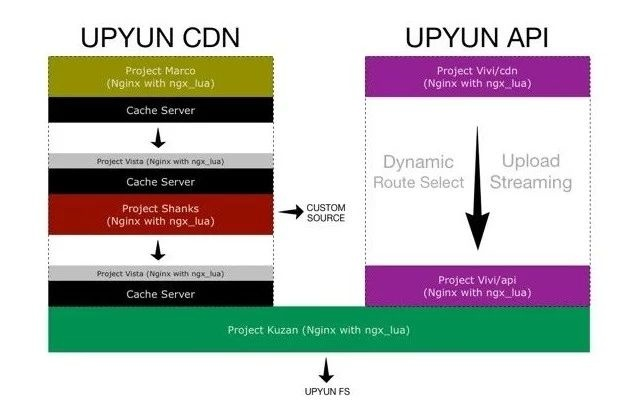
△ 又拍雲 CDN 架構與 API、雲處理架構
上圖左邊是又拍雲 CDN 的簡單架構圖,右邊是又拍雲的 API、雲處理方面的架構圖。圖中除了 Cache Server,其他所有的服務全部是基於 OpenResty 實現的,包括又拍雲端儲存的閘道器。去年,又拍雲引入了 Kong,將它作為公司的 API 服務,日誌上報、流量上報、監控資料上報等服務的統一入口閘道器,並做了統一的認證,給我們省了不少的事情。
upyun-resty 這個 github 倉庫記錄了又拍雲所開源的 lua-resty 庫、C 模組以及又拍雲所報告和修復的關於 OpenResty 和 Nginx 的 bugs。
從 2013 到 2018 年,又拍雲的業務發展愈加全面,不得不去做更深入的一些優化。業務發展到了一定階段,必然會遇到效能瓶頸,而這些問題就交由我們這些工程師們來解決。
效能分析、Tips
我們經常會在線上或本地開發機器上執行 top、pidstat 等命令,這些命令會報告一些系統和程序的資源使用情況,這就是資源分析。資源分析主要聚焦於資源利用率、飽和度以及錯誤數,這就是經典的 USE 分析方法。這個分析方法由 Brendan Gregg 大神提出,非常有用。通過資源分析可以非常直觀的看到業務應用在線上跑著,會吃掉多少的記憶體,佔用多少的 CPU,產生多少磁碟吞吐等。
第二個是針對應用程式本身所展開的工作負載分析,工具也比較多,包括 perf,systemtap,bcc/ebpf 等工具。通過 systemtap、bcc/ebpf 可以將資料進行彙總,利用工具畫出火焰圖。負載分析主要是針對應用程式自身的表現,比如 OpenResty,在作為一個反向代理伺服器或者閘道器存在時,大家比較關心它的指標就是請求延時和狀態碼,像 501、502、504 狀態碼的比例。
當我們需要展開分析時,會發現線上環境,工具等條件不足,甚至連基本的編譯工具都沒有,這時候像 systemtap 這樣的工具就沒法用了。又拍雲也遇到了這樣的問題,因此我們採用了容器化,把所有的工具全部扔到了容器裡,包括一些基本的編譯器,連結器,常用的 perf、systemtap、gdb、mozilla rr 等工具。大家可能會覺得容器的許可權會不會有問題,當然首先這個容器必須是以特權模式去執行,另外還需要把宿主機的核心標頭檔案進行對映,並且必須使用宿主機的 pid namespace,否則在容器裡面沒有辦法去追蹤宿主機上的程序。

△ 容器案例
上圖例子中執行的容器使用的是 upyun_stap 的映象,跑起來後可以在這個容器裡面做任何的事情,但是它對核心是有一定的要求,如果想使用 systemtap,核心就必須把一些相關的選項開啟。這是我們一個小的思路,如果遇到環境工具不足的情況,可以考慮採用容器化的方法。
ngx_lua 程式設計怎樣挑選合適的 API 獲得更好的程式設計體驗
介紹一下 ngx.ctx 和 ngx.var,這兩個 API 一般用於儲存和請求相關的資料,它們的資料都是關聯到某個請求。ngx.ctx 本質上就是一個 Lua table,後者 ngx.var 實際上是一個獲取 Nginx 變數的介面,通過它可以設定和獲取變數。相比較而言, ngx.ctx 是更好的選擇,首先 Lua table 的實現非常快,雲風曾在一篇文章裡提過,Lua table 查詢一次的耗時,幾乎等於對 key 進行一次 Hash 的過程。其次 ngx.var 返回的是 Nginx 變數的值,它的返回值只能是字串,型別比較單調,如果存一些結構化的資料,就不得不去進行序列化,從而會帶來一定的開銷,並且在 ngx.var 的介面內部還有一些 Hash 的計算、記憶體的分配等。

△ Tips
分享一個 Tips,我們可以適當的 cache 一下 ngx.ctx,去避免相對比較昂貴的 metamethod 元方法呼叫。比如上面這個程式碼片段,先把 ngx.ctx 進行 local,然後再對它進行一些複雜和取用,這樣就避免了額外的 metamethod 呼叫。
ngx.ctx 也有一些缺陷,最大的缺陷就是生命週期只能侷限在一個 Nginx location 當中。換言之,如果業務比較複雜,Nginx 發生了內部重定向,儲存於 ngx.ctx 內的資料都會被丟失,所有模組的上下文都會被清掉,因為 ngx.ctx 實際上是存在 ngx_lua 模組的上下文當中。所以在發生一次內部呼叫之後,資料就再也獲取不到了。這個問題去年我們在 github 也問過,後來用 Lua 實現了一個折中的方案,我們模擬了 ngx.ctx 的實現過程,將它儲存在我們自己所建立的表裡,然後將它的索引值儲存到變數中,因為變數的生命週期是不受 location 影響,而是貫穿整個請求的,不管請求中間發生過多少次的內部跳轉,變數都是一直存在的。

△ 方法案例
舉一個例子,上圖從 location / t1 跳轉到了 t2,資料還是可以從 location /t 2 中獲取出來。通過這個方法,就可以保證即使發生了內部跳轉,依舊可以獲取資料。
HTTP headers 操作
介紹大家在用 OpenResty 的時候,必然是離不開操作 HTTP 頭部的,主要的介面就是 ngx.req.get_headers,這個介面會返回所有的請求頭,如果說沒有給它指定 raw 引數,所有的名字都是小寫的形式存在的。如果你傳入的請求頭名稱不是全小寫的,第一次是獲取不到的,它會把這個全部轉換成小寫,再去訪問一次。因此在這個過程中,我們會訪問表兩次,而且中間有一次經過了元方法的呼叫,在針對這個事情上有一個比較好的辦法,那就是手動的把它的元表去掉,然後在訪問的時候全部使用小寫的形式。這樣就可以省掉元方法的呼叫,可能一次元方法、兩次元方法,看不出什麼效果,但是當一個請求裡面可能操作比較多的請求頭,同時 qps 比較高的時候,就能體現出一定的差距來。
然後是日誌處理,我們大多都會採用 Nginx access log 模組去管理訪問日誌。它最大的弊端就是和磁碟、檔案系統進行了互動,那麼就有可能受到檔案系統或磁碟的影響,如果磁碟抽風或磁碟利用率滿了,反過來就會影響到 Nginx 的程序。因為 OpenResty 和 Nginx 在寫磁碟的時候,是同步寫的,如果 access_log buffer 的引數設定不合理,會產生多次的 write() 系統呼叫,對應用程式本身是非常不利的。建議大家可以使用 lua-resty-logger-socket 元件,又拍雲也使用了這個工具,將日誌傳送到同一個機房同一個網段的其他服務,由其他的服務去上報日誌,這樣可以避免 CDN 服務和磁碟直接進行互動,最大程度保障服務不會收到磁碟本身的影響。因為一塊磁碟有時候不僅一個服務在用,其他的服務也在用,如果其他的服務產生太多的磁碟寫入,就會反過來影響到 CDN 服務。
養成良好的程式設計習慣
- 不要濫用全域性變數:在 ngx_lua 程式設計中,全域性變數是在一張表裡,雖然 Lua table 設計的很好,每次訪問都僅僅是一次表查詢,雖然速度很快,但是和本地變數的讀取還是有差距的,所以全域性變數能不用就不用。
- 避免低效的字串拼接操作:舉一個臭名昭著的例子,在 for 迴圈裡去拼接字串,會產生大量的記憶體分配,大量的記憶體拷貝,帶來 GC 開銷。
- 避免太多的 table resize 操作:大家在程式設計時,需要一個表就創建出一個空表,往裡面寫資料,這個過程中會發生一些 table resize,表內部的 hash part 大小會發生改變。比較好的辦法就是使用 table.new 建立預先定義好大小的表。
- 使用 LuaJIT 和 lua-resty-core 的搭配,避免使用官方的 Lua 直譯器:LuaJIT 非常的強悍,所以也應該儘可能的去使用 JITable 的函式,同樣 LuaJIT 的 ffi 實現也非常的優秀,比使用原生的 Lua C stack 的互動方式更加的方便、高效。
DNS 解析管理
大家可能對 Nginx 本身的域名解析的理解上存在一些偏差,這裡會介紹一下 Nginx 執行時所使用的 DNS 解析器的一些缺點,以及分享又拍雲基於 ngx_lua 所做的解決方案。

△ 案例
圖中虛擬主機的後端是寫在 upstream group 裡面,只有一個 server 指向 http://upyun.com 域名,大家會覺得這樣寫完就沒事了。某一天 http://upyun.com 指向的那臺機器崩掉了,匆匆忙忙去改解析,卻發現沒有生效,然後服務還是出現一 堆 502。因為這樣的一個域名,在 Nginx 或者 OpenResty 剛剛啟動的過程中,就已經解析完了,worker 程序在處理請求的過程中不會對域名的解析發生任何改變,其實解析在處理 server 指令的時候就已經完成了,這第一個誤區。這種情況下只能手動去重啟服務,如果服務像 CDN 那麼多,會比較耗時和麻煩。第二如果不用 upstream 直接帶過去也是不行的,兩者實際上沒有太多的差別,Nginx 內部也會創造一個 upstream group,然後把域名解析好。所以這兩種方法,總的來說只會解析一次,使用的是 getaddrinfo 或者 gethostbyname,呼叫系統配置的 nameserver 去進行配置。
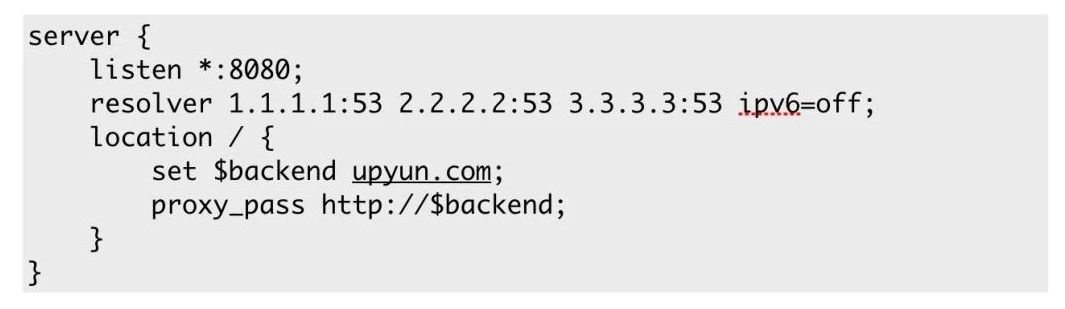
分享一個比較好的方法,可以強迫你的服務進行解析,就是在 proxy_pass 指令裡使用變數,把整個解析過程推遲到執行時。proxy_pass 後面的那一串是一個複雜值,會進行一個變數的解釋,最後再對域名進行解析,這時候會使用到 Nginx 的 resolver,比如上面所定義的,定義了三個 nameserver。然而 Nginx 的執行時 DNS resolver 的問題也挺多的,DNS resolver 雖然支援輪詢,也支援 cache,可以簡單的快取在記憶體中,但是不支援配置備用 name server,所有配置好的 nameserver 之後都會被使用。同樣 DNS resolver 也沒有實現故障轉移,最關鍵的是不支援在故障時使用陳舊資料。因為出現故障時,有資料肯定好過沒資料,即使解析是舊的,也能擋住一定的危害。

solver的執行情況
我們對 DNS resolver 不是非常的滿意,又拍雲的業務也都是用 Ngx_lua 所編寫的,索性就直接弄了一個 lua-resty-domain 的庫,它主要承擔的是域名的管理。它基於 OpenResty 官方的 lua-resty-dns (DNS 解析器的庫) 同時結合 Cloudflare 開源的 lua-resty-shcache (一個快取元件的庫),也結合了又拍雲所開源的 lua-resty-checkups(主要是做心跳和負載均衡的庫)。全部結合起來以後,lua-resty-domain 能夠做到複雜的 load balancing,包括簡單的輪詢、帶權輪詢和一致性 Hash,或者是其他的一些負載均衡的辦法。lua-resty-domain 支援心跳功能,就是向目標的 nameserver 發起解析請求,看它的解析情況,以及是否超時等。 lua-resty-domain 也支援故障轉移,如果所有主 nameserver 都掛掉了,會去使用備用的。因為結合了 lua-resty-shcache 所以也支援 cache 功能,可以把解析出來的資料存在共享記憶體當中。最關鍵的是,lua-resty-domain 能在所有的 nameserver 掛掉的時候,提供一些陳舊資料,保證業務不會受到影響。綜合來說,這是一個比較好的解決方案。

△ lua-resty-domain 配置
在 cluster 塊中定義了一主一備的 nameserver,能在 DNS 解析方面提供一個高可用的解決方案。DNS 是每個服務裡面不可獲缺的一部分,比如使用了公共的 DNS 的時候,無法保證公共DNS 時刻沒有問題, 比如某個時刻 DNS 伺服器負載較高,解析延時上升反而影響到了業務,這就划不來了。所以萬事還是要從自己做起,做好一個完美的解決方案,儘可能的避免這樣的影響。

除了使用 lua-resty-dns 庫,ngx_lua 的 Cosocket,內部也提供了簡單的域名解析功能,使用的也是 Nginx 的 resolver,但我們不太想用。所以我們參考了一下 Kong,把 ngx.socket.tcp 的 connect 方法重寫了一下,先呼叫 lua-resty-domain 進行解析,再將解析出來的地址傳遞給原來的方法,強迫它使用我們所定義好的域名解析功能。雖然這些程式碼沒有特別容錯,但是足夠表述出這種思想,這是一個非常好的 idea。
SSL 硬體加速實踐 BUG 解析
SSL Acceleration 會把應用中所涉及到的加解密、簽名等佔用 CPU 的任務全部 offload 到像 Intel QAT card 這種具備計算能力的硬體上去,從而降低應用程式的負載。 Acceleration 這個詞比較有迷惑性,並不是說計算本身得到加速,而是說這種技術能夠讓應用程式的吞吐得到提升。尤其結合非同步模式,採用非同步的方式把任務全部都交付給硬體後,應用就可以處理其他請求了,這樣使得應用程式的吞吐得到了一個質的提升。
CDN 廠商最關注的就是 CDN 和頻寬的比例,CDN 跑到 80%、90%,但是頻寬一直上不去的話就完全利用不起來機房的頻寬,這對成本來說是不利的。如果在同等的 CPU 消耗情況下,能產生的頻寬和吞吐量上去了,對成本會比較有利。又拍雲所採用的就是 OpenResty+Asynchronous OpenSSL+Intel QAT 的組合方案。
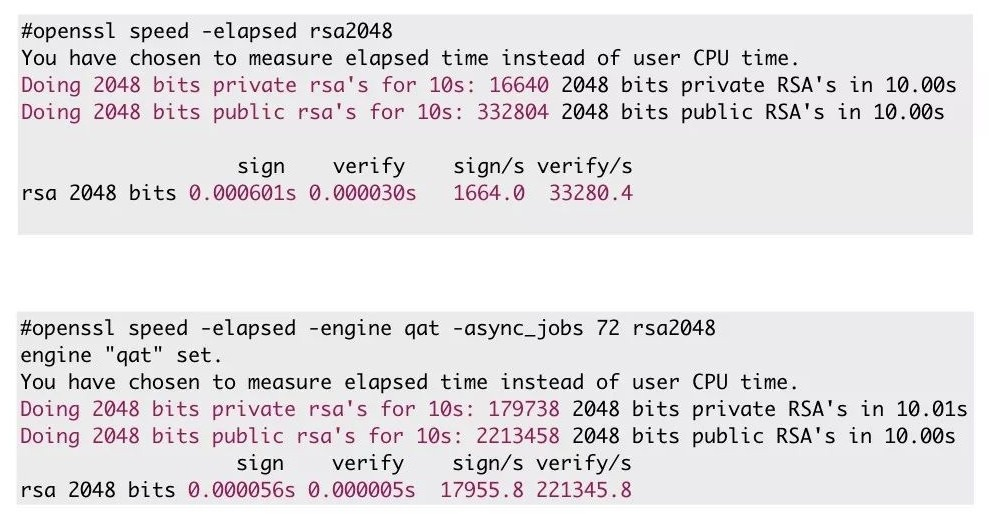
△ 硬體加速前後資料
這張對比圖,上面是沒有使用硬體加速的資料,下面是使用了硬體加速的資料,分別做了一次RSA 私鑰簽名以及公鑰認證的過程,可以看到最後一行的對比,使用 QAT 卡之後私鑰簽名的過程至少提高了十倍,後面用公鑰認證也有八到九倍的提升。不過這是最理想的情況,是沒有任何業務的時候的得到的一個理論值,業務當中肯定是達不到的。
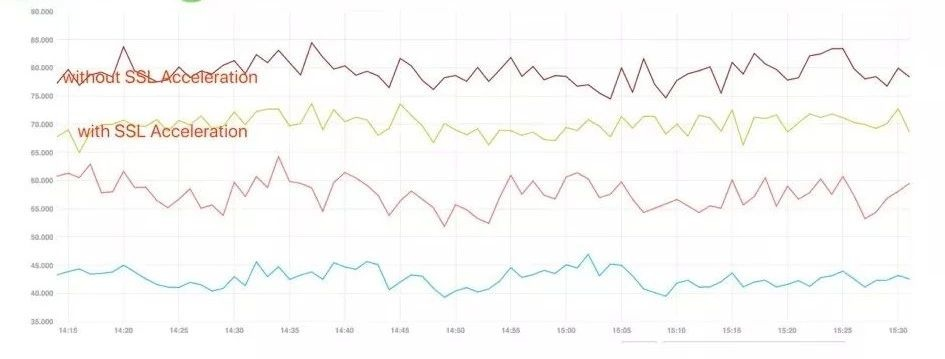
△ 實際 CPU 效果
這是我們監控中採集到的 CPU 的變化曲線,當時的連線數大概是三四萬個到 443 埠的連線。 CPU 的變化可能就沒有那麼理想,大約降低了10%,因為其他的業務也需要佔據一定的 CPU。整合到又拍雲這樣複雜的 CDN 系統中也算是一個非常不錯的提升了。
非同步模式的 OpenSSL 和 LuaJIT 不能很好的共存,會出現應用程式崩潰的問題,這是非常不幸的。對此我們也排查了很久,究竟是什麼導致的崩潰。
首先嚐試過將 LuaJIT 的 JIT compiler 禁用,結果是還會出現崩潰。也嘗試過關閉 OpenSSL 的非同步模式,崩潰確實沒有出現了,但是同步的去做硬體 offload 過程,沒有比直接用軟體計算快多少,那就沒必要用這個方案了。另外我們在 ssl_certificate_by_lua* 階段有 ocsp 校驗過程,會有一些 Light Thread 的協程切換,我們也試過關閉 ocsp,但崩潰問題還是會出現。最後,我們甚至將服務中用到的其他一些元件全換成了原生元件,但問題依舊存在。

△ 流程圖
後來,LuaJIT 社群有一個哥們說我們的程式是不是存在這麼一個情況。
首先 Nginx 要進行 SSL handshake,執行在系統棧上。非同步模式 Open SSL 內部使用了 OpenSSL fibre,其實就是協程,啟用這個模式後,會涉及到 fibre 上下文切換的過程, 此時程式會執行到 OpenSSL fibre 的棧上,前面我提到了我們的程式在 ssl_certificate_by_lua 階段也有業務介入,那麼反過來程式又會跑到了 LuaJIT 的棧上,從而可以執行應用程式碼。應用程式碼又呼叫了 ssl.set_der_cert 這樣的介面去設定證書,證書都是儲存在 redis 這樣的外部元件裡的,拿出來就需要設定進去。設定進去以後,會涉及到一些摘要計算,此時程式執行到了 OpenSSL fibre 的棧上去了,在交付給硬體以後,OpenSSL fibre 可能會將自己切出,所以此時應用程式又回到了系統棧上,即握手之前的位置,然後 Niginx就非常愉快的去處理其他的請求,其他請求也是類似,所有的業務程式碼都是由 LuaJIT 執行的,某個時刻就又跑到了 LuaJIT 的協程棧上。
整個的過程簡單來說,就是我們重入了 LuaJIT,但是並沒有呼叫到 lua_yield() 函式。
Lua 是用 lua_resume() 和 lua_yield(),去進行協程切換的。我們相當於違反了這個規則,重入到了 LuaJIT,發生了不可預期的問題。

△ 禁用程式碼
目前想到的最好的辦法就是在 ngx_lua 和 ssl 相關的 API 裡去禁掉上下文切換。所幸 OpenSSL 非同步模式提供了相關介面,我們在相關的函式里加入了兩段程式碼,重新編譯完放上去後,應用程式就開始正常的工作了。
我的分享就到這裡,希望大家遇到同樣的問題能有一些啟發。
推薦閱讀: