
Anti-Caching:一種新型資料庫管理系統架構
1.寫在前面
之前的三篇博文主要介紹了NVM(Non-Volatile Memory)和資料庫相關的內容。NVM因其讀寫效能接近DRAM、可位元組定址、非易失、大容量等特點,在電腦科學的許多領域都具有非常身後的發掘潛力。而我目前研究的資料庫方向只是NVM所應用的一個小小的領域分支而已。
上一篇部落格介紹了兩篇論文,它們都是將已有的資料庫系統(或者是將該系統的某種機制)重新實現在NVM架構上,進行一番討論,給出未來的資料庫結合NVM的可能方向。
從啟發性上來講,CMU、BROWN大學和Intel實驗室合作的工作成果具有非常深遠的意義和十分現實的研究價值。
今天,給大家介紹的就是他們三者合力做出的另一個研究,這一研究於2013年發表於資料庫頂會VLDB上,論文連結如下:
2.本週回顧
在深入介紹Anti-caching這篇論文之前,我先來總結下前一週看得相對比較有啟發價值的論文(當然,我並不是只在讀論文)。
第一篇論文是發表於IEEE Computer Society的Survey:How Persistent Memory Will Change Software Systems,它高屋建瓴地總結了Persistent Memory的特性,指出這種記憶體在諸如File system,Database, virtual memory management等領域的可能應用。對於剛剛瞭解NVM(或者說成是SCM,PM也罷)的研究者來說,是一個具有提綱挈領作用的啟發式論文。
當然,它有一個缺點,就是在每個方向上展開都不豐富也不嚴密,看完之後可能會有走馬觀花的感覺,但是如果你想要了解NVM可能在哪些場景發揮作用的話,建議讀一讀,之後更加細節具體的研究就需要再去查閱更多相關文獻了。
第二篇論文是FPTree: A Hybrid SCM-DRAM Persistent and Concurrent B-Tree for Storage Class Memory,SIGMOD,2016,是一個非常新穎的研究。之前我幾乎沒有看到研究者只針對資料庫中的B+ Tree做永續性方面的優化,但這篇文章就匠心獨運地提出來通過將索引數做成Persistent,concurrent B+ Tree,可以將資料持久化而且與那些易失性樹結構相比,沒有明顯的開銷。它是在傳統的Hardware Transactional Memory基礎上,利用了SCM-DRAM混合架構,引入fingerprinting技術,達到的研究效果。
然而,遺憾的是,對於目前的我來說,這篇論文仍然顯得太過複雜了,主要是它的base knowledge我學習地還不夠。所以也只是大概看了一下的他的工作,技術細節沒法講得清楚。如果哪位研究者對此新成果有興趣且有這方面的知識基礎,相信閱讀這篇論文會有很大的裨益。
第三篇論文就是今天要著重介紹的Anti-caching了,有趣的是Anti-caching本身並沒有跟NVM結合,它是對現有的面向記憶體的資料庫系統的一種改進(關於memory-oriented的含義待會會進一步介紹)。因此,如果能夠在Anti-Caching的基礎之上,針對NVM的優勢做優化,使之效能更高,也是一個非常有趣且值得一做的嘗試。
3.論文介紹
(1)問題背景
資料庫發展的歷程是以高效能1為目標的,而基於disk的資料庫系統將磁碟作為資料的主要儲存裝置,只在DRAM上做buffer pool,快取一小部分熱資料。當transaction來臨時,若資料不在記憶體中,就必須讀取磁碟,因此磁碟IO成為了disk-oriented database system2的效能瓶頸。除此之外,面向磁碟的資料庫系統一般採用併發機制來加快transaction執行的速度(多執行緒訪問),因此在操作過程中可能會有鎖衝突3發生。
隨著DRAM的儲存空間增大,資料庫系統設計者們想到可以將資料遷移到記憶體中進行,而不再將磁碟作為資料庫的儲存裝置。這就是memory-oriented database system4的基本思想。面向記憶體的資料庫系統大大提升了transaction執行的速度,也省去了複雜的併發控制開銷與繁重的資料logging。但是面向記憶體的資料庫系統存在一個不可避免的問題,它的效能只有在資料庫資料量小於可用記憶體空間大小的時候才好。一旦記憶體裝不下整個資料庫,就會發生page fault,當前transaction任務的執行就會終止。
因此一旦資料大小超出記憶體容量時,作為任務執行者和操作者就只有兩個選擇:第一是換一個更大容量的實體記憶體;第二是什麼都不做,看著它的效能跌落會disk-oriented database system。
由於以上兩種資料庫系統各有各的弊端,Anti-caching的研究者試圖構思出一種良好的方案,解決大容量資料與有限空間記憶體之間的矛盾,從而提升整個資料庫系統的效能。
(2)Anti-Caching系統設計
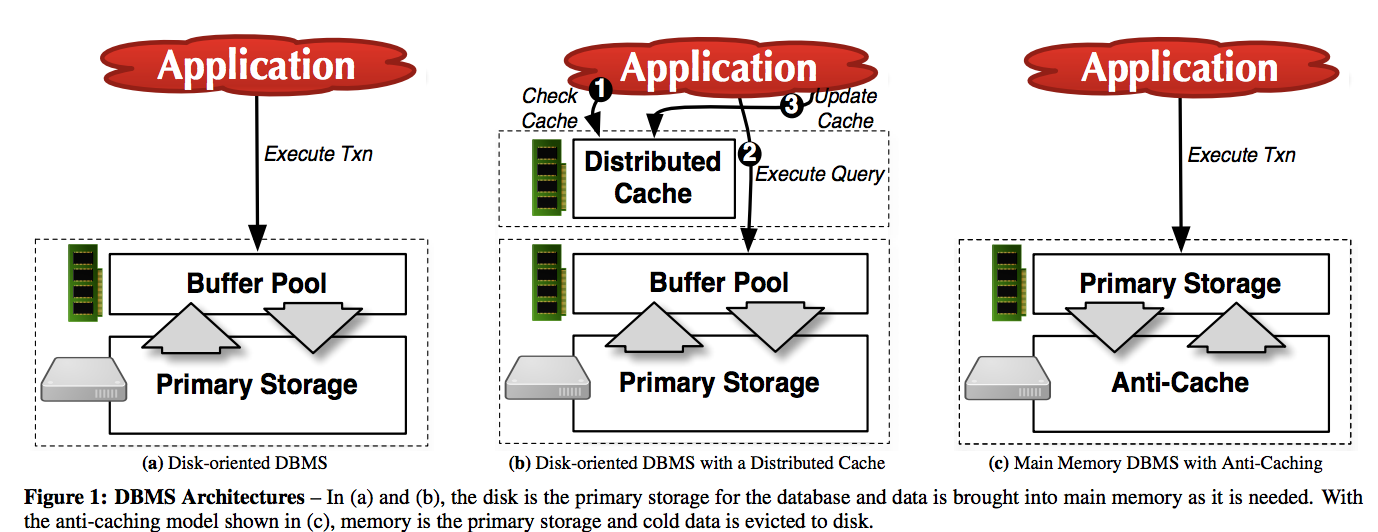
Anti-Caching 系統結構圖如上圖(c)所示,它是基於H-Store5實現的改良版本的記憶體資料庫系統。它的特點是,在執行transaction之前,仍然像傳統的面向記憶體資料庫系統那樣把所有資料裝入DRAM中,隨著transaction的執行,資料庫會變得越來越龐大。當資料量超過操作者設定的一個閾值以後,就彈出(evict)冷資料組6到磁碟上。此時資料的存放地點是唯一的,即熱資料都在記憶體中,冷資料都在磁碟上,不存在某些資料既在磁碟又在記憶體中的情況。
那麼,我們自然會產生這樣一個問題:如果某個transaction想要訪問被彈出的冷資料,該怎麼辦?
這個時候,資料庫系統會中斷當前的transaction,並開闢一個新執行緒執行“prepass”過程,來取回冷資料。與此同時,下一個transaction是允許非同步執行的。這樣就提高了整體的執行速度。具體的prepass流程比較複雜,但是論文在這一點上是有詳細描述的,流程圖如下所示:
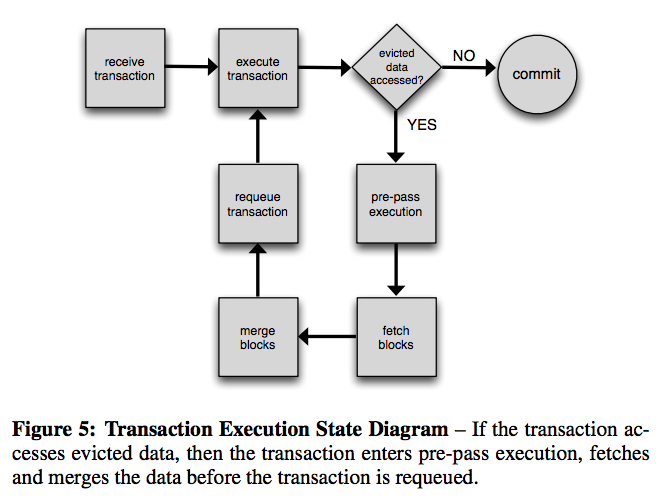
如果感興趣的話,建議閱讀該論文的第三部分最後一小節。
整個Anti-Caching的原理概括起來就是這麼簡單,因為它將冷資料彈出到disk的Block table(也就是Anti-cache)中,這剛好與面向磁碟的資料庫將DRAM作為資料Cache完全相反,所以這一系統機制的名稱就是Anti-Caching。
(3)效能評測
評測採用的Benchmark依舊是業界標準YCSB與TPC-C。
與Anti-Caching相比較的是另外兩個系統:MySQL與用分散式cache優化的SQL。H-Store作為一個面向記憶體的資料庫系統的Baseline而存在。
效能對比圖如下所示:
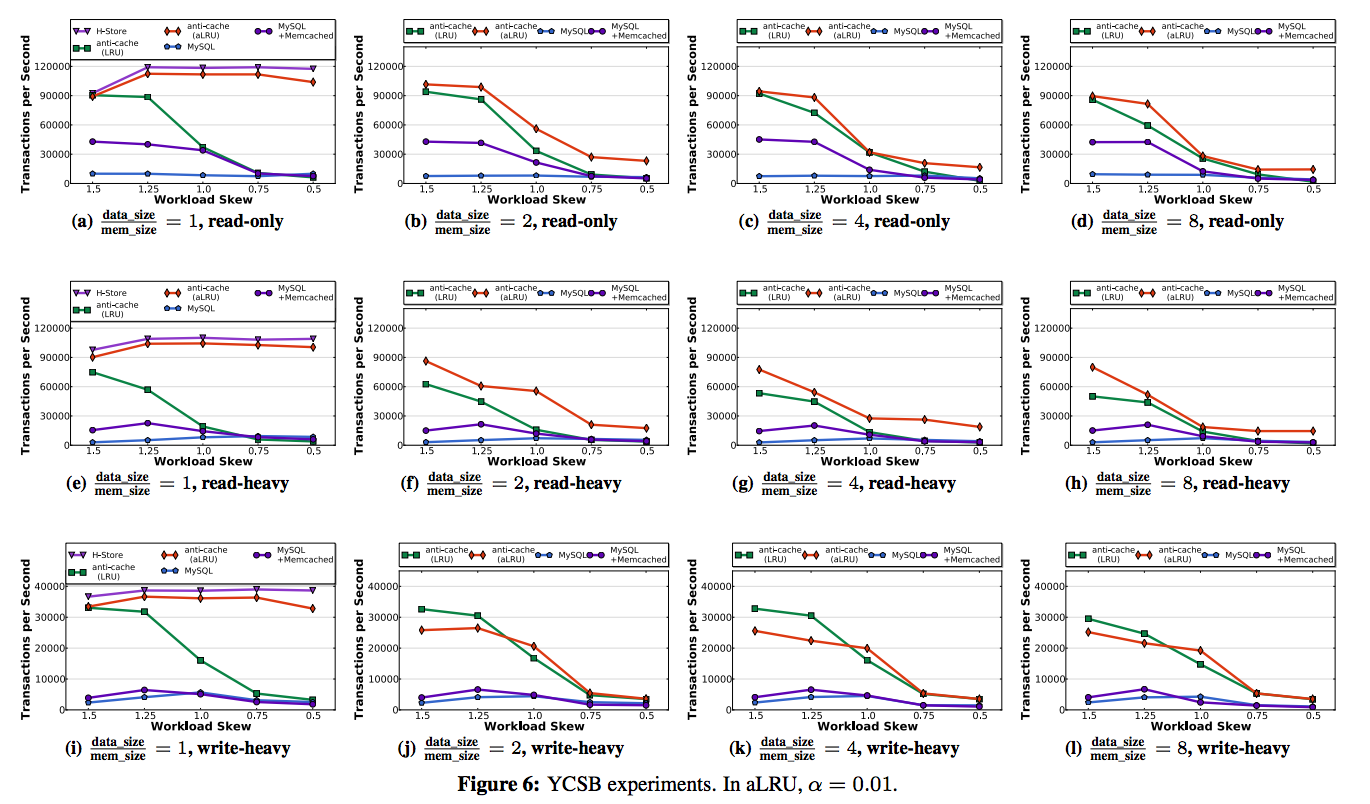
從上述的效能對比中,可以得出很多有趣的結論:
第一,隨著資料庫資料量的增大,所有系統的效能都發生了下降,這是因為disk read和write增加的緣故;
第二,隨著skew7的降低,所有的系統性能也都發生了下降,這是因為訪問evicted data的頻率變高了,需要進行更多的磁碟IO;
第三,對於high skew工作負載,Anti-caching要遠遠好於MySQL,這是因為一方面H-Store的輕量級併發控制機制(我對此並沒有深入研究)比MySQL的更加高效,另一方面Anti-cahing的細粒度管理使得tuples不會在記憶體和磁碟中反覆換入換出,大大減少了抖動現象的發生。
關於aLRU與LRU這兩條曲線,其區別在於根據transaction取樣,從而維繫LRU連結串列。aLRU是1%取樣,LRU是100%取樣。從圖上可以看出,aLRU要比LRU效能更高,說明取樣時一種有效節約空間資源的方法,也避免了每次transaction都要重新整理LRU連結串列的過程。
4.我的思考
可以肯定的是,這是一篇非常漂亮的論文,每一個部分的設計都很合情合理,也加入了很多研究者自己構思出的新技術以解決Anti-cahcing機制帶來的新問題。
但是,如果非要概括一下的話,他們的主要貢獻並不是Anti-Caching機制本身,而是“prepass”過程的非同步控制transaction執行。因為傳統的面向記憶體資料庫系統在記憶體過載的情況下完全可以直接退化為Anti-Caching模式,組織冷資料,彈出到disk中,以某種形式(塊,集合,hashmap)存放。
而對於我來說,該汲取Anti-caching機制的哪些優點/特點,為我所用,並結合NVM的優勢,使效能再進一步提高,才是重點。
想解決的問題有:在大資料量database的情況下,如何使系統系能具有非線性下降的特性(比如緩慢的亞線性下降)?或者是在low-skew情況下,如何使得系統不至於因為IO成為效能瓶頸?
試想,如果將NVM作為Anti-cache的存放空間,至少IO問題將得到有效緩解,因為NVM的讀寫效能是2xDRAM-8xDRAM;另一方面,如果將NVM作為DRAM替代品來使用,Anti-Caching機制也就不再有意義,因為NVM本身就可以保證大資料量儲存。
那麼是否可以往上一層再考慮一下,如何緩解cache miss的問題?
似乎NVM本身並不能帶來多大的效能改善······
那併發控制和資料一致性保證呢?恢復速度?
NVM可以省去breakpoint的工夫,只做logging即可。
目前似乎還沒有特別清晰的思路,也是在摸索中前進。哪怕只能在現有的系統上做出一點點的改善,哪怕只改善了某一個負載場景下的效能,對我來說也一定是非常有意義的工作。
加油!
- 衡量資料庫效能的主要方法是執行OLTP負載,以其每秒鐘執行的transaction數量來評判效能是高是低。 ↩
- disk-oriented database system,即面向磁碟的資料庫系統,是最早出現的資料庫系統設計。它將全部資料放在磁碟中,隨著transaction的進行,而將熱資料快取到DRAM中。 ↩
- 之所以要加鎖,是為了防止多執行緒訪問同一資料(比如record)時進行修改造成的資料不一致。 ↩
- memory-oriented database system,即面向記憶體的資料庫系統。它在開始執行transaction之前,就將全部資料庫資料載入到記憶體中,只用disk做logging和breakpoint。 ↩
- H-Store是一種經典的面向記憶體的資料庫系統,是由Brown大學開發。它的一個商業實現版本是voltDB。 ↩
- 冷熱資料的區分是由記憶體中的維持的一個LRU連結串列來表徵的,表頭是最近不被訪問的資料,表尾是最近最常訪問的資料。這裡的資料不是按塊(block)而是按元組(tuple)來區分的,因此具有細粒度的特點。 ↩
- skew指的是transaction是否對某些資料有更高的訪問頻度,high skew指大部分transaction只對一小部分資料進行操作,low skew指transaction對資料的訪問比較均勻。 ↩