
hadoop分散式環境搭建(vmware14+hadoop2.9.0(包含yarn)+Ubuntu16.04LTS+jdk1.8.0_161)
博主最近在vmware workstation14+hadoop2.9.0+Ubuntu16.04LTS環境下搭建了一個master(一個namenode)兩個slave(即兩個datanode)的分散式hadoop環境,下面將本次博主搭建的過程及步驟按照和各位博友分享,由於博主未儲存搭建時各步驟的截圖,因此將使用前輩們各步驟截圖或者無截圖,望各位前輩見諒。
進行配置之前,需要在ubuntu中安裝vim外掛編輯檔案,相比於vi和gedit工具,該工具更容易操作,也能避免亂碼等一系列不必要的問題。
安裝命令:sudo apt-get install vim

(一)第一步:新建三臺虛擬機器,並進行相應的網路配置(靜態IP,hostname檔案配置,hosts檔案配置,關閉防火牆或者開啟相應埠)
(1)利用vmware workstation14新建三個虛擬機器(網路模式選擇橋接模式)
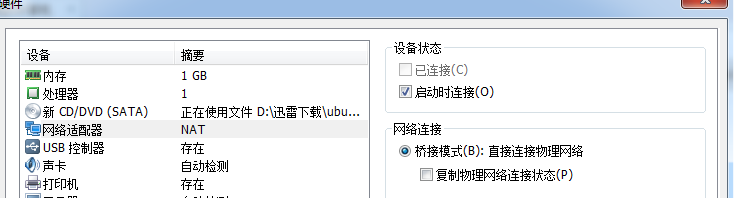
並根據實體機所在的網路環境,在虛擬機器中設定靜態IP,博主搭建的網路環境如下(各位博友根據自己網路環境進行相應變化):
master節點:192.168.1.200
slave1節點:192.168.1.201
slave2節點:192.168.1.202
以上配置可以從介面進行操作,以master為例。
(2)修改hostname檔案,需要root許可權,命令:su root,輸入密碼,然後進入root,然後vim etc/hostname,master節點機器,改為master,於此相同,slave1和slave2節點也分別改為slave1和slave2
(3)修改hosts檔案,將下列內容新增進hosts檔案(三個節點均需要配置此步驟,需要root許可權,進入root參考上條,以master為例)
192.168.1.200 master
192.168.1.201 slave1
192.168.1.202 slave2

(4)關閉防火牆或者開啟使用埠(三個節點均需要配置此步驟,博主使用的是關閉防火牆,簡單粗暴)
進入root使用者,關閉防火牆命令為:ufw disable
執行命令後,提示防火牆服務不會在開機時啟動即可

(5)測試
master節點:ping slave1 看是否ping通
ping slave2 看是否ping通
slave1 節點:ping master 看是否ping通
ping slave2 看是否ping通
slave2 節點:ping master 看是否ping通
ping slave1 看是否ping通
如以上測試通過,則第一步配置成功
(二)第二步,三臺虛擬機器分別新建相同的使用者(如果新建的三臺虛擬機器有相同的使用者,我覺得此步驟可以省略,以master為例)
(1)新建名為hadoop使用者組

(2)新增一個使用者mwq,並新增進hadoop使用者組,並制定使用者目錄

(3)設定mwq使用者密碼,連續輸入兩次

(4)設定mwq使用者許可權,賦予admin許可權

以下步驟切換到mwq使用者進行
(三)第三步,機器未安裝ssh時需安裝ssh服務,並在三臺虛擬機器之間開啟ssh免密的登入
(1)三臺機器均需安裝ssh服務(以master節點為例)

(2)虛擬機器自身免密登入自身(三臺虛擬機器均需要此步驟設定),以master節點為例,輸入ssh-keygen -t rsa -P "",敲回車兩次,直到出現以下介面

進入.ssh資料夾
用cat id_rsa.pub >> authorized_keys 命令生成免密登入authorized_keys,實現免密登入

效果如下:
第一次需要輸入yes,以後就不需要了
(3)配置master到slave1和slave2的免密登入(該操作在slave1和slave2上操作)
首先將master中生成的id_rsa.pub複製到已安裝ssh服務的slave1和slave2中的.ssh資料夾
然後利用cat id_rsa.pub >> authorized_keys實現master登入到slave1和slave2的免密登入
(四)安裝java jdk環境(本文使用jdk1.8.0_161,三臺虛擬機器均需要此操作)
(1)首先去oracle官網,下載jdk8,預設檔案儲存到/home/mwq/Downloads
(2)我的解壓目錄為/usr/lib下的jvm資料夾,而且jvm資料夾不存在,需要在root許可權下建立,如下圖所示

進入jvm資料夾

複製Downloads資料夾下的jdk到jvm並解壓

切換到mwq使用者並配置環境變數,編輯/.bashrc檔案

在檔案末尾輸入以下內容

使配置檔案生效

檢視是否配置成功

另外的slave1和slave2節點也可按照以上步驟配置
(五)下載並配置hadoop(三臺主機均需相同配置)
在以下地址http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz下載hadoop-2.9.0,千萬別下成hadoop-2.9.0-src.tar.gz
博主在/home/mwq中新建hadoop資料夾,並將hadoop-2.9.0解壓到hadoop下面(三臺主機存放hadoop-2.9.0檔案的位置相同)
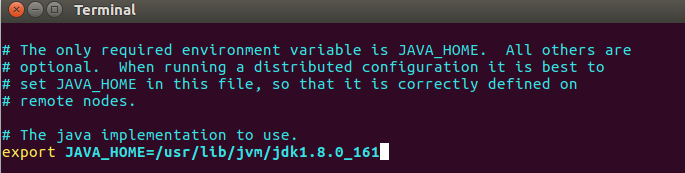
修改/home/mwq/hadoop/hadoop-2.9.0/etc/hadoop/hadoop-env.sh檔案
修改/home/mwq/hadoop/hadoop-2.9.0/etc/hadoop/core-site.xml檔案

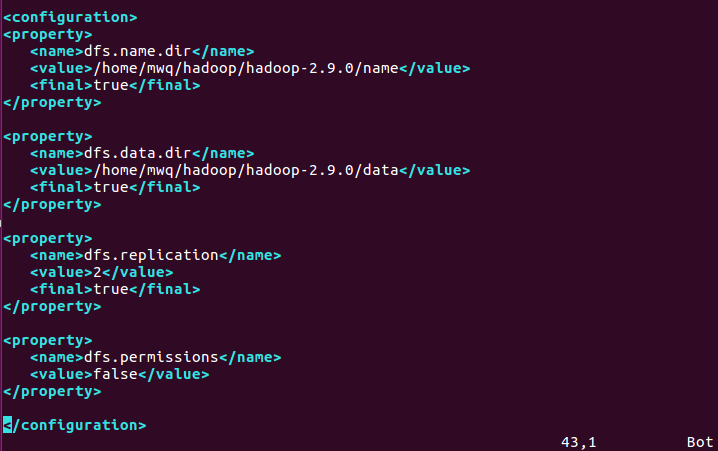
修改/home/mwq/hadoop/hadoop-2.9.0/etc/hadoop/hdfs-site.xml檔案
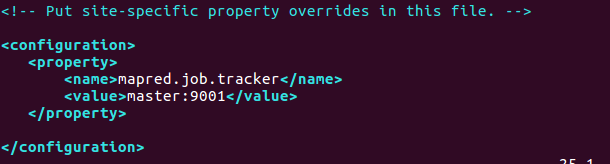
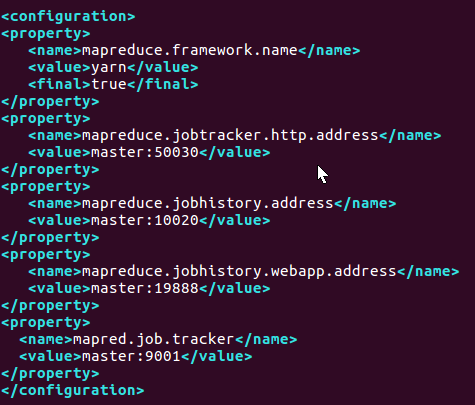
修改/home/mwq/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml.template檔案
修改/home/mwq/hadoop/hadoop-2.9.0/etc/hadoop/slaves檔案

修改/etc/profile檔案,加入以下內容

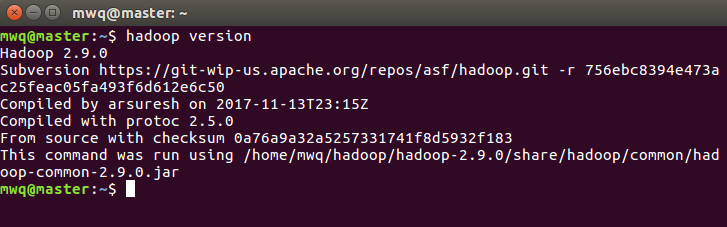
執行結果:
(六)格式化,只需在master節點
hadoop namenode -format,測試通過後可以配置yarn和mapreduce
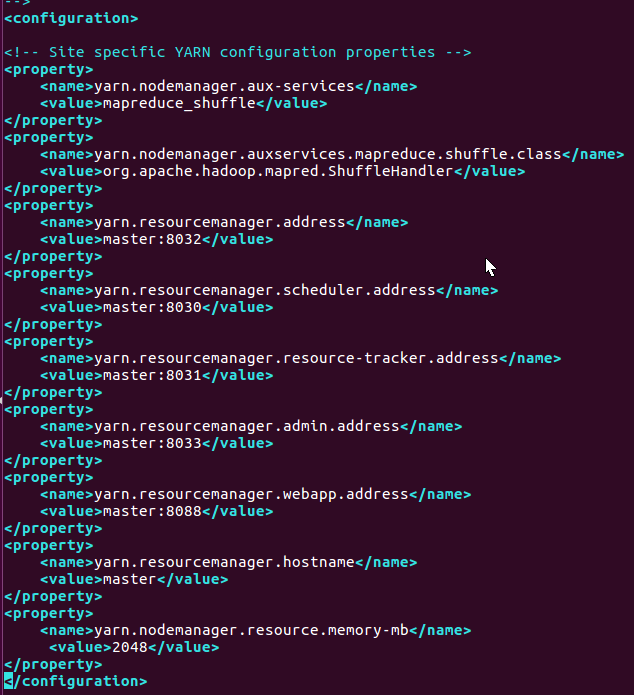
(七)配置yarn,主要修改yarn-env.sh,yarn-site.xml和mapred-sitexml,master節點修改好之後,複製到slave1和salve2節點即可
yarn-env.sh 新增jdk目錄

mapred-site.xml在剛才配置的基礎上,增加以下未有的內容
yarn-site.xml增加以下配置
(七)啟動hadoop服務
start-all.sh