
Python程式碼中的捕捉效能-CPU分析(直譯器)
在這篇文章中,我將介紹一些工具和方法,可以在執行Python指令碼時對剖析器進行剖析。
就像在我們之前的文章中一樣,CPU分析的含義是一樣的,但是現在我們不是針對Python指令碼的。相反,我們想知道Python直譯器是如何工作的,以及在執行我們的Python指令碼時花費多少時間。
接下來我們將看到如何跟蹤CPU使用情況,並找到直譯器中的熱點。
系列索引
一旦帖子釋出,下面的連結將會生效:
測量CPU使用率
對於這篇文章,我將主要使用與記憶體分析和指令碼CPU使用相同的指令碼,您可以在下面或在這裡看到它。
import time def primes(n): if n == 2: return [2] elif n < 2: return [] s = [] for i in range(3, n+1): if i % 2 != 0: s.append(i) mroot = n ** 0.5 half = (n + 1) / 2 - 1 i = 0 m = 3 while m <= mroot: if s[i]: j = (m * m - 3) / 2 s[j] = 0 while j < half: s[j] = 0 j += m i = i + 1 m = 2 * i + 3 l = [2] for x in s: if x: l.append(x) return l def benchmark(): start = time.time() for _ in xrange(40): count = len(primes(1000000)) end = time.time() print "Benchmark duration: %r seconds" % (end-start) benchmark()
優化後的版本是bellow或here:
import time def primes(n): if n==2: return [2] elif n<2: return [] s=range(3,n+1,2) mroot = n ** 0.5 half=(n+1)/2-1 i=0 m=3 while m <= mroot: if s[i]: j=(m*m-3)/2 s[j]=0 while j<half: s[j]=0 j+=m i=i+1 m=2*i+3 return [2]+[x for x in s if x] def benchmark(): start = time.time() for _ in xrange(40): count = len(primes(1000000)) end = time.time() print "Benchmark duration: %r seconds" % (end-start) benchmark()
CPython
CPython是多功能的,完全用C編寫,因此更容易測量和/或配置檔案。您可以在這裡找到在GitHub上託管的CPython的原始碼。預設情況下,你會看到最新的分支,在寫這個的時候是3.7+,但是所有其他的分支都可以下到2.7。
在我們的帖子中,我們將重點介紹CPython 2,但同樣的步驟可以成功應用到最新的3版本。
程式碼覆蓋工具
檢視正在執行的C程式碼部分的最簡單方法之一是使用程式碼覆蓋率工具。
我們首先克隆回購:
git clone https://github.com/python/cpython /cd cpython
git checkout 2.7
./configure
複製目錄中的指令碼並執行以下命令:
make
coverage
./python 04.primes-v1.py
make coverage-lcov
第一行將編譯GCOV支援的直譯器,第二行將執行工作負載並收集.gcda檔案中的分析資料,第三行解析包含分析資料的檔案,並在名為的資料夾中建立一堆HTML檔案lcov-report。
如果我們index.html在瀏覽器中開啟,我們可以看到直譯器原始碼中被執行的位置來執行我們的Python指令碼。你會看到像下面的東西:
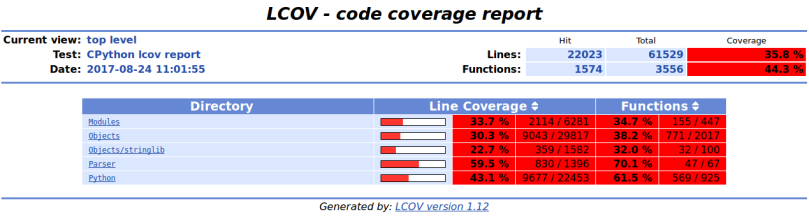
在頂層,我們可以看到構成原始碼的每個目錄以及覆蓋的程式碼量。例如,我們開啟Objects 目錄, listobject.c.gcov.html檔案。雖然我們不會完全解讀,但我們分析一部分。看下面的部分。

如何閱讀?在黃色的列上,你可以看到來自C檔案程式碼的行號。在下一列中,您可以看到特定行被執行的次數。在最右邊的列中,您可以看到實際的C原始碼。
在這個例子中,這個方法listiter_next被稱為6000萬次。
我們是如何得到這個功能的?如果我們仔細看看我們的Python指令碼,我們觀察到它使用了很多列表迭代並追加。(另一點可以導致指令碼優化首先)
讓我們繼續其他一些專用工具。
PERF
有關更多資訊,我們可以使用perfLinux系統上提供的工具。官方文件可以在這裡閱讀。
我們(重新)使用以下內容構建CPython直譯器。如果你沒有在同一個目錄中下載Python指令碼,你應該這樣做。另外,請確保perf 已安裝在您的系統上。
./configure --with-pydebug
make
執行perf 如下。Brendan
Gregg寫的這個優秀的頁面可以看到更多的使用perf的方法。
sudo
perf record ./python 04.primes-v1.py
執行指令碼之後,您將看到如下所示的內容:
Benchmark
duration: 32.03910684585571 seconds
[21868 refs]
perf record: Woken up 20 times to write data ]
[ perf record: Captured and wrote 4.914 MB perf.data (125364 samples) ]
要檢視結果,執行`sudo perf
report` 以獲得度量。

只有最有趣的電話才能被儲存。在上面的螢幕中,我們看到花費的時間最多PyEval_EvalFrameEx。這是主要的直譯器迴圈,我們對這個例子不感興趣。相反,我們感興趣的是下一個耗時的功能
- listiter_next佔用10.70%的時間。
執行優化版本後,我們看到以下內容:
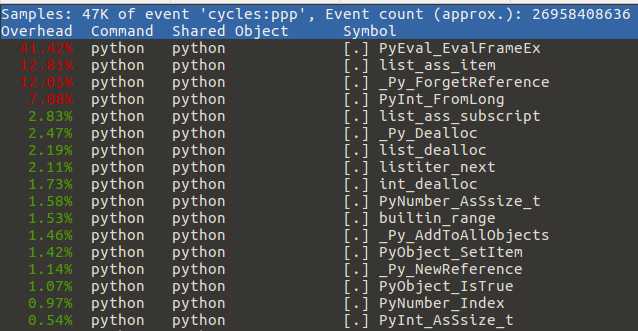
經過我們的優化,該listiter_next 功能只消耗了2.11%的時間。讀者可以根據口譯員的情況做進一步的優化。
Valgrind的/ Callgrind
另一個可以用來查詢瓶頸的工具是Valgrind,它的一個叫做callgrind的外掛。更多細節可以在這裡閱讀。
如果尚未完成,我們(重新)使用以下內容構建CPython直譯器。如果你沒有在同一個目錄中下載Python指令碼,你應該這樣做。另外,請確保valgrind 已安裝在您的系統上。
./configure --with-pydebug
make
執行valgrind 如下:
valgrind
--tool=callgrind --dump-instr=yes \
--collect-jumps=yes --collect-systime=yes \
--callgrind-out-file=callgrind-%p.out -- ./python 04.primes-v1.py
結果是:
Benchmark
duration: 1109.4096319675446 seconds
[21868 refs]
==24152==
==24152== Events : Ir sysCount sysTime
==24152== Collected : 115949791666 942 208
==24152==
==24152== I refs: 115,949,791,666
kcachegrind
callgrind-2327.out
PyPy
在PyPy上,可以成功使用的配置檔案是非常有限的,恢復到vmprof,一個由開發PyPy的人寫的工具。
首先,從這裡下載PyPy 。在此之後,啟用pip 對它的支援
安裝vmprof很簡單,只需執行:
bin/pypy
-m pip install vmprof
執行工作量為:
bin/pypy
-m vmprof --web 04.primes-v1.py
作者:Alecsandru
Patrascu,alecsandru.patrascu [at] rinftech [dot] com
原文:https://pythonfiles.wordpress.com/2017/08/24/hunting-performance-in-python-code-part-4/