
CS231n lecture 9:各大經典網路 AlexNet/VGG/GoogleNet/ResNet(上)
本篇將深入介紹當前的應用和研究工作中最火的幾個CNN網路架構——AlexNet、VGGNet、GoogleNet和ResNet,它們都在ImageNet分類任務中有很好的表現。另外,本篇也會粗略介紹一些其他的架構。
LeNet-5回顧
我們先來回顧一下最基本的LeNet,它可以說是首個效果比較好的CNN。它使用了5x5的卷積核,stride為1。池化層卷積核是2x2的,stride為2。最後還有幾個全連線層。網路結構很簡單也很容易理解。

AlexNet
接下來講的是AlexNet,它是第一個在ImageNet分類上表現不錯的大規模的CNN,在2012年一舉碾壓其他方法獲得冠軍,於是開啟了一個新的時代。
它的基本架構組成如下圖,它是由若干卷積層、池化層、歸一化層和全連線層組成的。左邊方括號裡的內容為資料的形狀,右邊有卷積核的詳細引數。總體來說AlexNet和LeNet很像,只不過網路層數大大增加。
整個網路架構可視化出來是這樣的(輸入層的224x224應為227x227):

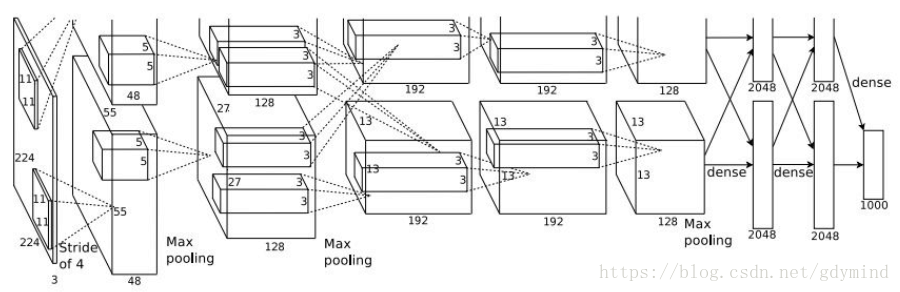
下面總結一下這個網路的一些特點和小細節:
- 它是第一個使用ReLU的網路;
- 它使用了局部響應歸一化層(Local Response Normalization Layers, LRN),瞭解LRN可以看這裡和這裡。不過要注意,這種層現在已經不常用了,因為研究發現它的作用不是很大;
- 它使用了很多資料增廣(data augmentation)技術,比如翻轉(flipping)、PCA Jittering、隨機裁切(cropping)、顏色歸一化(color normalization)等等;
- 使用了0.5的dropout;
- batch size為128;
- SGD Momentum為0.9;
- 學習率為0.01,每次loss不降的時候手動除以10,直到最後收斂;
- L2 weight decay為5e-4;
- 使用7個CNN ensemble(多次訓練模型取均值),效果提升為18.2% 15.4%。
另外提一句,從上面的架構圖中,CONV1層的的96個kernel分成了兩組,每組48個,這主要是歷史原因,當時用的GPU視訊記憶體不夠用,用了兩塊GPU。CONV1、CONV2、CONV4和CONV5在每塊GPU上只利用了所在層一半的feature map,而CONV3、FC6、FC7和FC8則使用了所在層全部的feature map。
AlexNet是第一個使用CNN架構在ImageNet Large Scale Visual Recognition Challenge(ILSVRC)上取得冠軍的網路,它能力挺不錯,不過後面講到的一些網路架構更加優秀,也是在我們實際應用中可以優先考慮使用的。
ZFNet贏得了2013年ILSVRC的冠軍,它所做的是對AlexNet的超引數進行了一些改進,網路架構沒什麼太大變化。但在2014年,有兩個新的很厲害的網路架構被提出來——VGGNet和GoogleNet。它們與之前網路的主要差異在於網路深度大大增加,相比於AlexNet的8層,它們分別有19層和22層。下面我們分別具體講一下兩個網路。
VGG
VGG主要有兩點改進:
- 顯著增加了網路層數(16層到19層)
- 大大減小了kernel size,使用的是3x3 CONV stride 1 padding 1和2x2 MAX POOL stride 2這樣的filter。
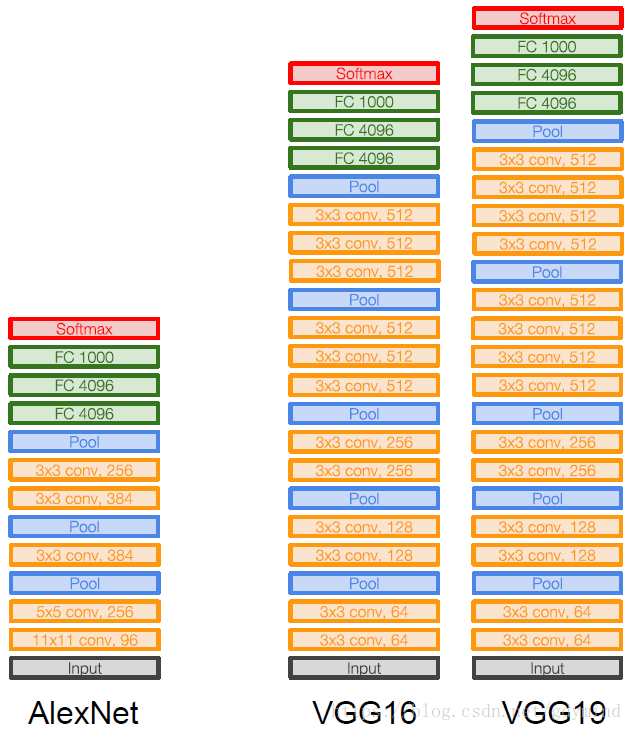
VGG和AlexNet的對比如下:
加深網路很好理解,但為什麼要縮小filter到3x3呢?我們來小小地計算一下:
當使用一個7x7的filter時,它的感受野是7x7的。但如果我們使用三個3x3的filter來替換這一個7x7的filter呢?
從輸入經過第一個3x3 filter,感受野為3x3,第一個filter的輸出再經過第二個3x3 filter,感受野為5x5(三個3x3的相鄰的區域綜合起來是5x5),經過第三個filter之後,感受野為7x7。這樣,經過替代後,在感受野不變的情況下:
- 網路更深了,大大增加了網路的非線效能力;
- 網路引數變少了:,其中、為分別為輸入、輸出的feature map數。
VGG16的具體引數如下:
可以看到,每張圖片forward的過程中需要佔用約100M的記憶體,這確實是個很大的數字。另外138M的引數量,也比AlexNet的60M多出不少。其中佔用記憶體大的主要是最前面的卷積層(因為網路前面部分資料量還比較大)和全連線層(之後我們可以看到一些架構通過去掉全連線層來節省記憶體)。

下面總結一下這個網路的一些特點和小細節:
- 它贏得了ILSVRC’14的冠軍;
- 它使用了和AlexNet類似的訓練方法;
- 它沒有使用AlexNet中用的LRN層(因為實驗發現LRN用處不大);
- 它分為VGG16和VGG19(其中VGG19只是多了三層,效果稍好一些,佔用記憶體也更多)。實際使用中VGG16用的更多;
- 為了提升效果使用了ensemble(多次訓練模型,最後取均值);
- FC7中得到的feature map(也就是一個1x4096的向量)提取出了很好的feature,可以用來做其他任務。
接下來講一下同樣在2014年提出的網路GoogleNet。
GoogleNet
GoogleNet是ILSVRC’14中的分類冠軍,它除了使用更深的網路(22層),還有一個更大的亮點——注重計算效率(Computational Efficiency)。GoogleNet中沒有使用全連線層,這大大減少了引數量。此外,它還使用了“Inception模組”(後面詳細講)。這樣一來,整個網路只需要5M的引數量,僅僅是AlexNet的十二分之一!
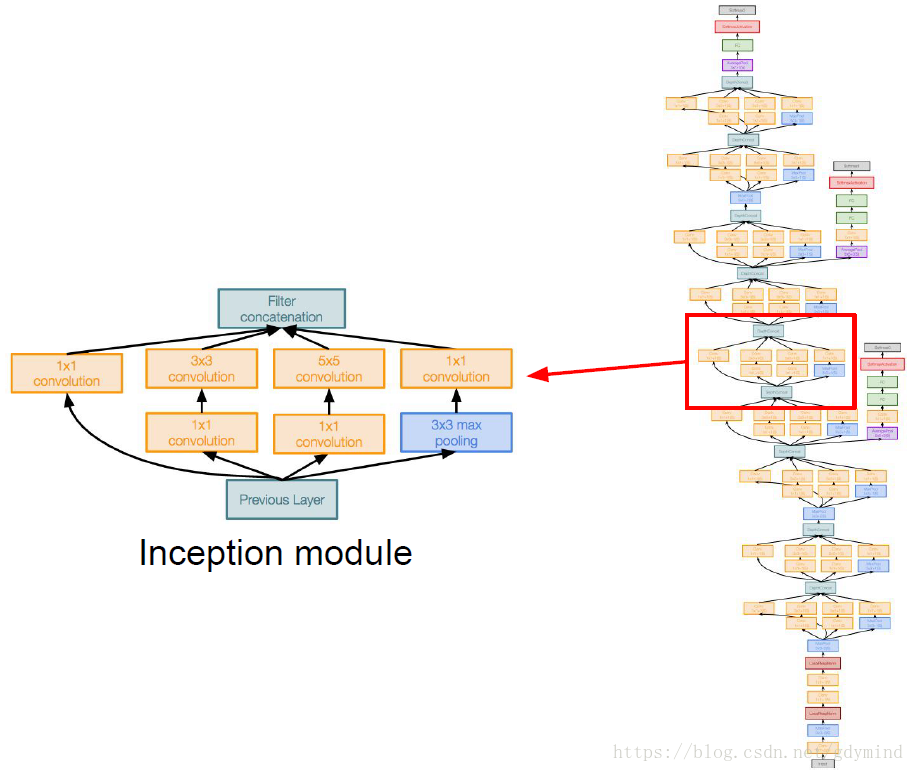
現在講一下這個神奇的“Inception模組”。它的主要思想是設計一種效果好的區域性網路拓撲結構(local network topology),也就是在網路中巢狀網路,最後把這些網路堆疊成一個網路,示意圖大概是這樣的:
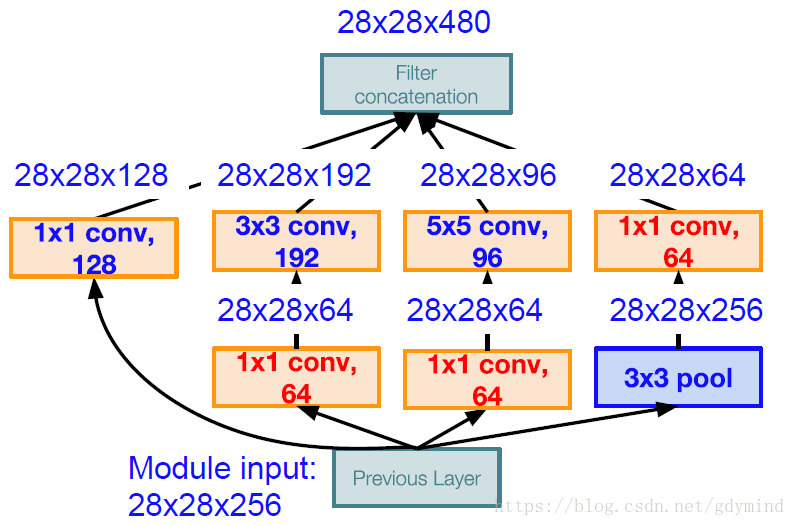
舉個Inception模組的最naive的栗子(見下圖),輸入被分別送到不同kernel size的卷積核中(1x1,3x3,5x5),另外還加了一個池化。各部分分別產生輸出之後,再把它們連成一個整體作為輸出。
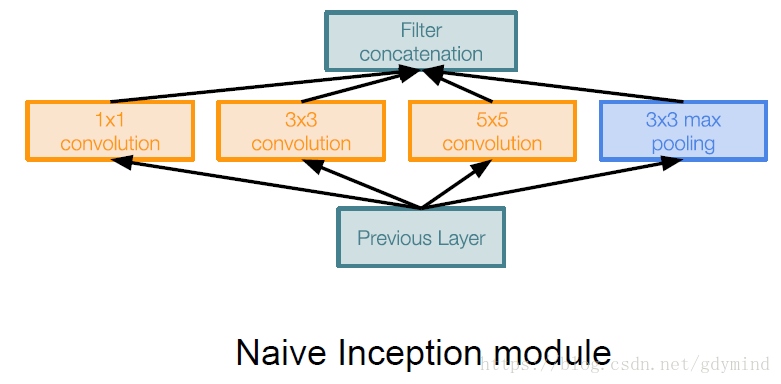
但是直接這樣做會有問題,把各部分輸出聯絡來之後,feature map的數量成數倍的增長。我們的解決方案是引入“bottleneck”層,這種層使用1x1的卷積層,不過使用的filter數目更少,也就是說減少了feature map的數量,新的架構舉例如下圖:
注意圖中的紅色部分,它們將256個feature map減少到了64個,也就大大降低了引數量。改進後的Inception模組只需要358M次操作(之前需要854M次)。
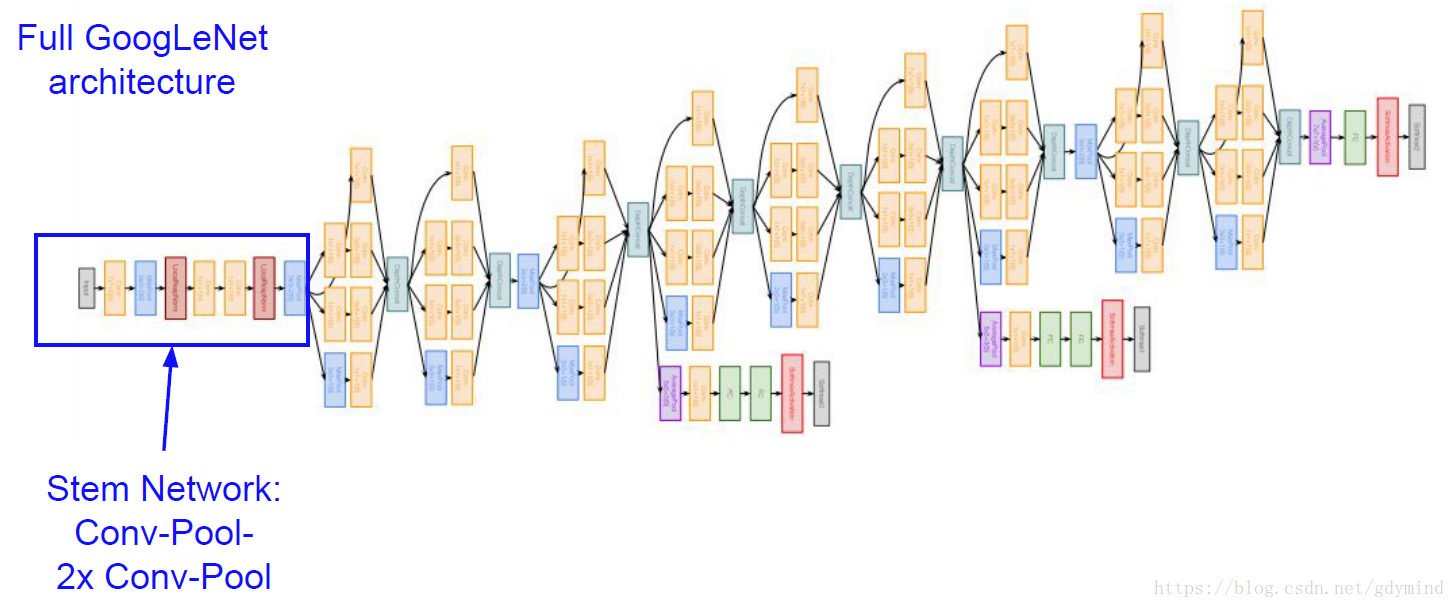
在GoogleNet中,網路的開頭部分是一個主幹形的stem network,這個部分和之前AlexNet和VGG中的差不多,是卷積池化之類的層的疊加(見下圖藍框)。之後把上面說的Inception模組串到了一起,最後加上用於分類的層形(注意沒有全連線層)成了整個網路。
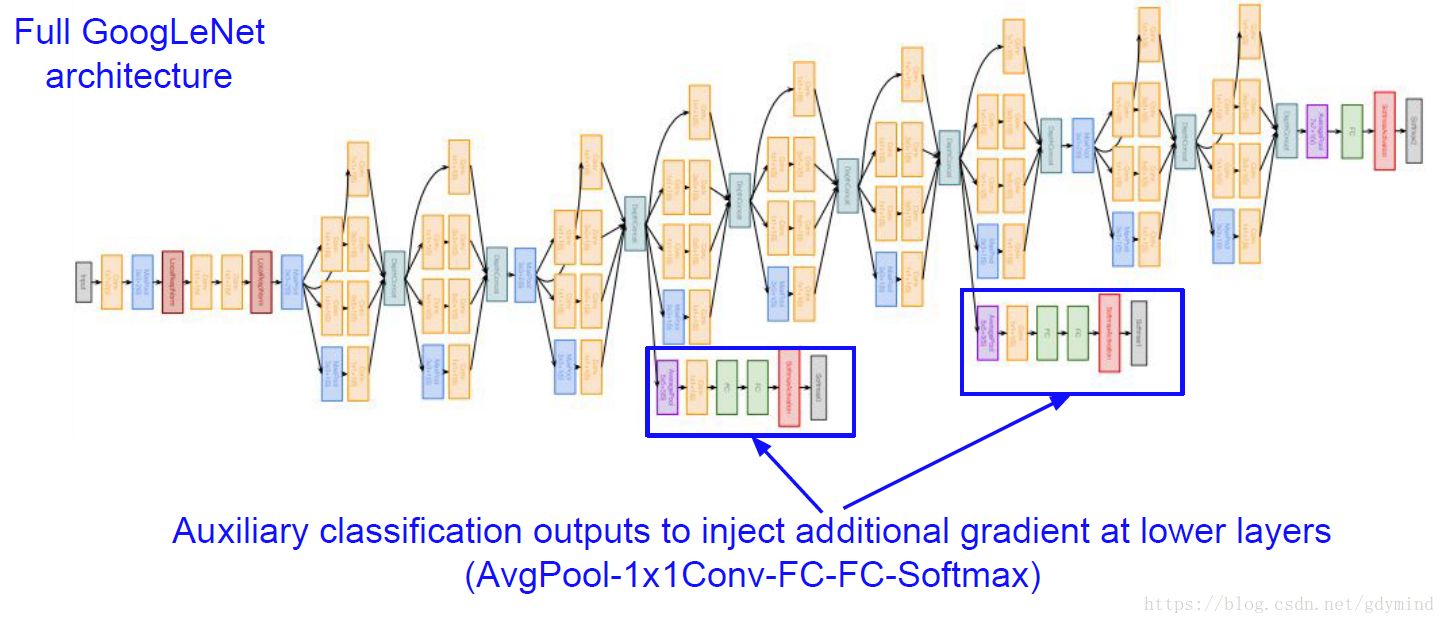
其中需要注意下圖中框出來的部分,它們和網路的最後做了類似的工作,也輸出了分類標籤。最終使用三處輸出一起計算loss。這樣做的原因是網路層數很多,中間的結果也很有用。此外中間的這兩處輸出也會計算梯度,這有助於緩解這種層數很多的網路中的梯度消失的問題。
到這裡,整個網路我們就介紹完啦,總體來說,網路之所以這樣設計、之所以效果這麼好有兩方面原因。一是前面提到的Inception Model很有用。此外還有一個重要原因,就是Google財大氣粗有錢任性,可以用大量的機器驗證各種各樣奇奇怪怪的網路架構,最後挑選出效果好的就行了(有錢真好.jpg)。
接下來我們的目光轉向2015年的冠軍——ResNet,具體請看下一篇文章~