
Gym小記(四)
Gym Box2D
Gym為我們提供了各種各樣的環境,其中對我最有用的是MuJoCo,但是這個要收費......
所以,我就只能去用Box2D環境了,畢竟免費~現在對Gym Box2D環境進行一些簡單的說明。
首先,我們來了解一下什麼是Box2D。Box2D是一個強大的開源物理遊戲引擎,用來模擬2D剛體物體的運動和碰撞。我們需要記住的是兩點:1.2D;2.剛體。在Box2D中集成了大量的物理力學和運動學的計算,並且將物理模擬過程封裝到物件中,將對物體的操作,以簡單友好的介面提供給開發者。我們只需要呼叫引擎中顯影的物件或者函式,就可以模擬現實生活中的加速、減速、拋物線運動、萬有引力、碰撞反彈等等各種真實的物理運動。
那如何在Gym中使用Box2D呢?是不是可以簡單地與前面一樣直接env=gym.make("Env")就可以呢?
答案是需要先安裝......
下面我們介紹一下安裝Box2D的步驟:
1)git clone https://github.com/pybox2d/pybox2d.git
2)cd pybox2d
3)python setup.py clean
4)python setup.py install
注意,如果我們以前按照某個教程安裝Box2D沒有安裝成功,並且在/usr/local/lib/python2.7/dist-packages中有Box2D相關檔案,請先刪除,然後按照上面的指令進行安裝,其中3)、4)兩步可能需要sudo才行,具體視情況而定。
裝好之後import Box2D,沒有報錯則表示安裝成功。下面我們通過示例展示一下Gym Box2D:
執行示例:import gym env = gym.make('LunarLander-v2') print env.observation_space print env.action_space for i_episode in range(100): observation = env.reset() for t in range(100): env.render() print(observation) action = env.action_space.sample() observation, reward, done, info = env.step(action) if done: print("Episode finished after {} timesteps".format(t+1)) break
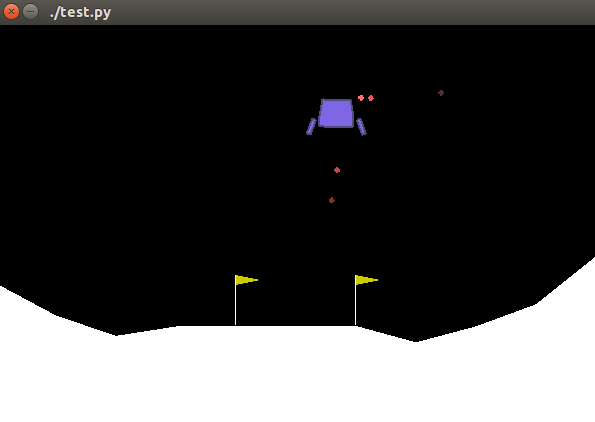
上面是對Gym Box2D中的LunarLander-v2環境進行了展示,該環境與另一個環境LunarLanderContinuous-v2定義在同一個.py檔案中:lunar_lander.py。二者的區別是LunarLander-v2中的action是是離散的(包括do nothing、fire left orientation engine、fire main engine、fire right orientation engine),而LunarLanderContinuous-v2中的action則是連續的(由一個包含兩個實值的向量來表示,一個值控制main engine,(-1,0)表示關閉,(0,+1)表示在50%~100%Power之間進行調節;另一個實值則控制left/right engine,(-1,-0.5)表示fire the left engine,(0.5,1)表示fire the right engine,(-0.5,0.5)表示off)。我們的目標是控制這裡說的這三個引擎(main/left/right)來控制飛行器的降落。我們的智慧體的目標是將飛行器停到指定的位置(兩旗中間的位置),環境的具體介紹如下:
1)LunarLander-v2
"Landing pad is always at coordinates (0,0). Coordinates are the first two numbers in state vector.Reward for moving from the top of the screen to landing pad and zero speed is about 100..140 points.If lander moves away from landing pad it loses reward back. Episode finishes if the lander crashes or comes to rest, receiving additional -100 or +100 points. Each leg ground contact is +10. Firing main engine is -0.3 points each frame. Solved is 200 points.Landing outside landing pad is possible. Fuel is infinite, so an agent can learn to fly and then land on its first attempt.Four discrete actions available: do nothing, fire left orientation engine, fire main engine, fire right orientation engine."
2)LunarLanderContinuous-v2
"Landing pad is always at coordinates (0,0). Coordinates are the first two numbers in state vector.Reward for moving from the top of the screen to landing pad and zero speed is about 100..140 points.If lander moves away from landing pad it loses
reward back. Episode finishes if the lander crashes or comes to rest, receiving additional -100 or +100 points. Each leg ground contact is +10. Firing main engine is -0.3 points each frame. Solved is 200 points.Landing outside landing pad is possible. Fuel
is infinite, so an agent can learn to fly and then land on its first attempt.Action is two real values vector from -1 to +1. First controls main engine, -1..0 off, 0..+1 throttle from 50% to 100% power. Engine can't work with less than 50% power. Second value
-1.0..-0.5 fire left engine, +0.5..+1.0 fire right engine, -0.5..0.5 off."
我們通過以下命令可以看一下比較好的示範:
cd ~/gym
python gym/env/box2d/lunar_lander.pycd ~/gym
python examples/agents/keyboard_agent.py LunarLander-v2我沒太搞懂這個怎麼玩......
對了,也可以去Wiki上看這個遊戲的具體說明:Lunar Lander。
因為我想要找一個以raw image作為輸入的env,所以對於這個LunarLander環境也就不是很關注,該環境的state如下:
state = [
(pos.x - VIEWPORT_W/SCALE/2) / (VIEWPORT_W/SCALE/2),
(pos.y - (self.helipad_y+LEG_DOWN/SCALE)) / (VIEWPORT_W/SCALE/2),
vel.x*(VIEWPORT_W/SCALE/2)/FPS,
vel.y*(VIEWPORT_H/SCALE/2)/FPS,
self.lander.angle,
20.0*self.lander.angularVelocity/FPS,
1.0 if self.legs[0].ground_contact else 0.0,
1.0 if self.legs[1].ground_contact else 0.0
]return np.array(state), reward, done, {}也就是說observation等於state,也是上面的長度為8個的向量,為low-dimension的observation輸入,所以這裡就不仔細考察了。
下一次我們將嘗試去尋找一個以raw image作為observation輸入的環境進行分析,下回再見~