
使用hystrix保護你的應用
凡是可能出錯的事必定會出錯
hystrix([hɪst'rɪks])是豪豬的意思。豪豬是一種哺乳動物,全身是刺用以更好的保護自己。netflix使用這畜生來命名這框架實在是非常的貼切,意味著hystrix能夠像豪豬的刺一樣保護著你的應用。下面是一張豪豬的高清無碼大圖。

本文專門探討netflix的hystrix框架。首先會說明在一次請求中呼叫多個遠端服務時可能會出現的雪崩問題,然後提出幾個解決這些問題的辦法,從而引出了hystrix框架;之後我們會給出一個簡單的例子試圖說明hystrix是如何解決上述問題的;文章主要探討了執行緒池隔離技術、訊號量隔離技術、優雅降級、熔斷器機制。
從雪崩看應用防護
一個現實中常見的場景
我們先來看一個分散式系統中常見的簡化的模型。此圖來自hystrix的官方wiki,因為模型比較簡單我這裡就在不在重複畫圖,直接使用現成的圖片做補充說明。
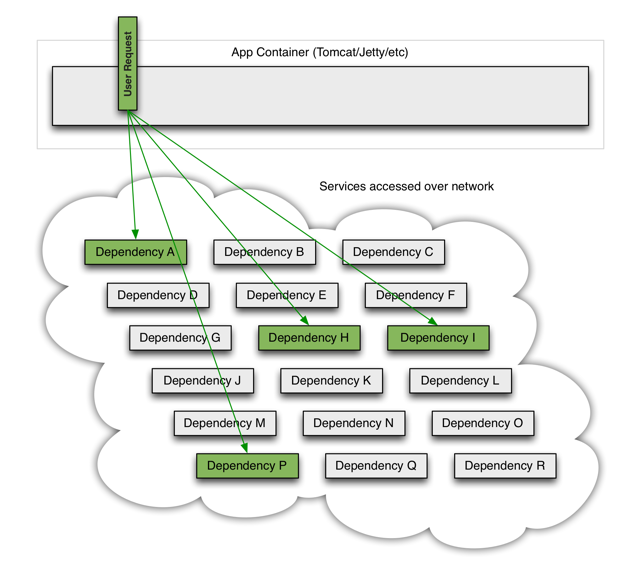
App Container可以是我們的應用容器,比如jetty,tomcat,也可以是一個用來處理外部請求的執行緒池(比如netty的worker執行緒池)。一個使用者請求有可能依賴其他多個外部服務,比如上圖中的A,H,I,P,在不可靠的網路環境下,任何的RPC都可能會面臨三種情況:成功、失敗、超時。如果一次使用者請求所依賴外部服務(A,H,I,P)有任何一個不可用,就有可能導致整個使用者請求被阻塞。考慮到應用容器的執行緒數目基本都是固定的(比如tomcat的執行緒池預設200),當在高併發的情況下,某一外部依賴的服務超時阻塞,就有可能使得整個主執行緒池被佔滿,這是
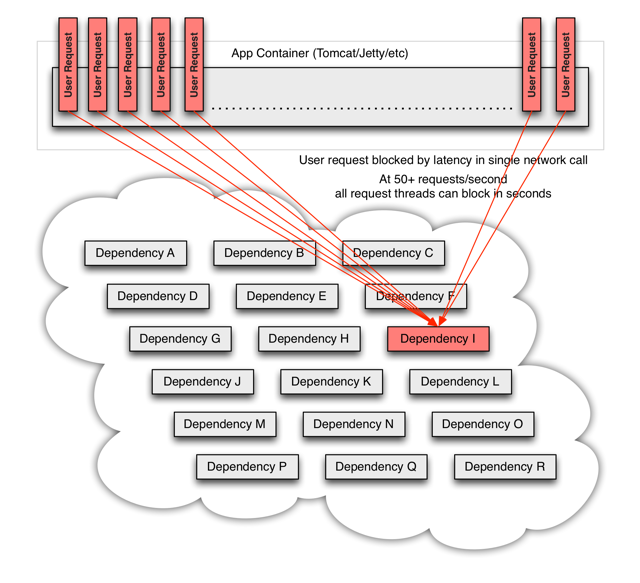
更進一步,執行緒池被佔滿就會導致整個服務不可用,而依賴該服務的其他服務,就又可能會重複產生上述問題。因此整個系統就像雪崩一樣逐漸的擴散、坍塌、崩潰了!
產生原因
服務提供者不可用,從而導致服務呼叫者執行緒資源耗盡是產生雪崩的原因之一。除此之外還有其他因素能夠產生雪崩效應:
- 服務呼叫者自身流量激增,導致系統負載升高。比如異常流量、使用者重試、程式碼邏輯重複
- 快取到期重新整理,使得請求都流向資料庫
- 重試機制,比如我們rpc框架的retry次數,每次重試都可能會進一步惡化服務提供者
- 硬體故障,比如機房斷電,電纜被挖了….
常見的解決方案
針對上述雪崩情景,有很多應對方案,但沒有一個萬能的模式能夠應對所有情況。
- 針對服務呼叫者自身流量激增,我們可以採用
auto-scaling方式進行自動擴容以應對突發流量,或在負載均衡器上安裝限流模組。參考微博:春節日活躍使用者超一億,探祕如何實現伺服器分鐘級擴容 - 針對重試機制,我們可以減少或關閉重試,直接採用
failfast,或採用failsafe進行優雅降級。 - 針對硬體故障,我們可以做
多機房容災,異地多活等。 - 針對服務提供者不可用,我們可以使用
資源隔離,熔斷器機制等。參考Martin Fowler的熔斷器模式
hystrix能夠解決服務提供者不可用的場景。他採用了資源隔離模式,通過執行緒隔離和訊號量隔離保護主執行緒池;使用熔斷器避免無節操的重試,並提供斷路自動復位功能。下面我們就來看一看如何使用hystrix。
使用hystrix
hystrix採用了命令模式,客戶端需要繼承抽象類HystrixCommand並實現其特定方法。為什麼使用命令模式呢?使用過RPC框架都應該知道一個遠端介面所定義的方法可能不止一個,為了更加細粒度的保護單個方法呼叫,命令模式就非常適合這種場景。命令模式的本質就是分離方法呼叫和方法實現,在這裡我們通過將介面方法抽象成HystricCommand的子類,從而獲得安全防護能力,並使得的控制力度下沉到方法級別。
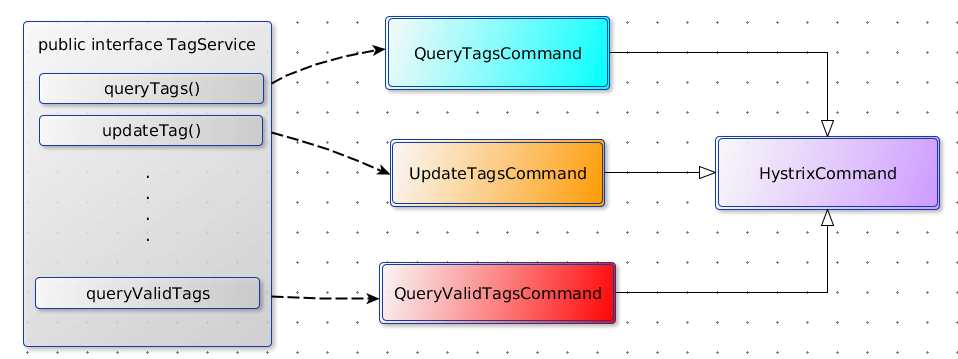
從簡單例子入手
先來看一個簡單的例子,TagService是一個遠端介面,queryTags()是其中一個方法,我們將其封裝為一個命令:
public class TagQueryCommand extends HystrixCommand<List<String>> {
// queryTags()的入參
int groupId;
// dubbo的實現介面
TagService remoteServiceRef;
// 構造方法用來進行方法引數傳遞
protected TagQueryCommand(int groupId) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("TagService"))
.andCommandKey(HystrixCommandKey.Factory.asKey("TagQueryCommand"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("TagServicePool"))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(THREAD)
.withCircuitBreakerEnabled(true)
));
this.groupId = groupId;
this.remoteServiceRef = ApplicationContextHelper.getBean(TagService.class);
}
// 我們呼叫遠端方法定義在這裡面
@Override
protected List<String> run() throws Exception {
return remoteServiceRef.queryTags(groupId);
}
// 降級方式
@Override
protected List<String> getFallback() {
return Collections.emptyList();
}
}HystrixCommand封裝了TagService.queryTags()方法),我們每次的呼叫都需要動態的建立一個命令:// 帶有隔離機制和熔斷器的遠端呼叫
List<String> tags = new TagQueryCommand(1).execute()Future<List<String>> f = new TagQueryCommand(1).queue();
List<String> tags = f.get();Future<List<String>> f = new TagQueryCommand(1).queue();
// 做一些額外工作
if(f.isDone()) {
f.get();
}- 每次new命令物件開銷怎麼樣?
- 構造方法中的那幾個key分別是什麼意思?
- 這裡的隔離策略配置是什麼意思?
- 如何去做優雅降級?
- 怎麼開啟和配置熔斷器?
建立命令開銷
每次new一個命令確實會有開銷。但是如果檢視HystrixCommand的原始碼,你會發現這個類的內部成員變數大都是共享物件。由於使用共享物件,每次建立一個新的command物件也就僅僅消耗一些引用空間以及一些非共享的原子狀態變數。因此這個類仍然是比較輕量的,我們在繼承這個類時,也應該繼續保持輕量。由於做了一層封裝,對cpu的額外消耗不可避免,但經過netflix的測試發現,帶來的額外效能消耗與他能帶來的好處相比是可以忽略不計。
key的意義
接著,我們再來說一下構造方法中key的意義:
HystrixCommandKey他用於唯一區分一個命令物件,並且唯一標識熔斷器、metric等資源。我們可以為每一個遠端方法都建立一個獨一無二的key。如果key相同,意味著此時會共用熔斷器和metric資源。HystrixCommandGroupKey將command進行分組,主要用於統計以便於我們進行監控。HystrixThreadPoolKey用來標示執行緒池,每一個command預設配備一個執行緒池(執行緒隔離模式下)。如果key相同,則會共用一個執行緒池資源。
一般實踐中,我們將一個介面中的所有方法都用不同的命令key區分,組key採用類名,執行緒池則根據需要選擇性的採用共享執行緒池或獨立執行緒池。
正確選擇隔離模式
hystrix之所以能夠防止雪崩的本質原因,是其運用了資源隔離模式。要解釋資源隔離的概念,我們可以用船艙做比喻。一艘遊輪一般都是一個一個艙室隔離開來的,這樣如果某一個艙室出現火災,就不會波及到其他船艙,從而影響整艘遊輪(這個是彈性工程學的一個關鍵概念:艙壁)。軟體資源隔離如出一轍,上文已經說過,由於服務提供者不可用,可能導致服務呼叫端主執行緒池被佔滿。此時如果採用資源隔離模式,將對遠端服務的呼叫隔離到一個單獨的執行緒池後,若服務提供者不可用,那麼受到影響的只會是這個獨立的執行緒池。如圖:

hystrix的執行緒池抽象是HystrixThreadPool類,它封裝了JDK的ThreadPoolExecutor,然後通過併發策略HystrixConcurrencyStrategy對外提供工廠方法。我們這裡只關心該執行緒池的核心配置,如下表:
| 引數 | 解釋 |
|---|---|
| coreSize | 核心執行緒數,maxSize也是該值 |
| keepAliveTime | 空閒執行緒保活時間 |
| maxQueueSize | 最大佇列大小,如果-1則會使用交換佇列 |
| queueSizeRejectionThreashold | 當等待佇列多大的時候,將會執行決絕策略 |
| timeoutInMilliseconds | 執行執行緒的超時時間 |
這裡我們需要注意的是queueSizeRejectionThreashold配置,直接用maxQueueSize去限制佇列大小行不行?行,但是不好,因為maxQueueSize是在初始化BlockingQueue時寫死的,靈活性較差,queueSizeRejectionThreashold則能夠動態進行配置,靈活性好,我們在調節執行緒池配置的時候也會重點關注這個值,如果設定的過高,則起不到隔離的目的(試想把他和maxQueueSize設定的非常大,則基本不會觸發拒絕策略),如果設定過小,就難以應對突發流量,因為你的快取佇列小了,當併發突然上來後很快就會觸發拒絕策略。因此需要根據實際的業務情況求得一個最佳值,當然也可以去做彈性感知。
除了執行緒池隔離,hystrix還提供了訊號量隔離機制。所謂訊號量隔離(TryableSemaphore),說的比較玄乎,其實很簡單,就是採用資源計數法,每一個執行緒來了就去資源池判斷一下是否有可用資源,有就繼續執行,然後資源池訊號量自減,使用完再自增回來;沒有則呼叫降級策略或丟擲異常。通過這種方式能夠限制資源的最大併發數,但它有兩個不好的地方:其一是他無法使用非同步呼叫,因為使用訊號量,意味著在呼叫者執行緒中執行run()方法;其二訊號量不像執行緒池自帶緩衝佇列,無法應對突發情況,當達設定的併發後,就會執行失敗。因此訊號量更適用於非網路請求的場景中。訊號量隔離模式下的最主要配置就是semaphoreMaxConcurrentRequests,用來設定最大併發量。我們再來看一下訊號量的實現類,TrableSemaphore:
private static class TryableSemaphore {
// 總資源數
private final HystrixProperty<Integer> numberOfPermits;
// 當前資源數
private final AtomicInteger count = new AtomicInteger(0);
public TryableSemaphore(HystrixProperty<Integer> numberOfPermits) {
this.numberOfPermits = numberOfPermits;
}
public boolean tryAcquire() {
int currentCount = count.incrementAndGet();
if (currentCount > numberOfPermits.get()) {
count.decrementAndGet();
return false;
} else {
return true;
}
}
public void release() {
count.decrementAndGet();
}
public int getNumberOfPermitsUsed() {
return count.get();
}
}使用優雅降級
所謂的優雅降級本質上就是指當服務提供者不可用時,我們能夠通過某種手段容忍這種不可用,以不影響正常請求。我們這裡舉個查詢標籤服務的例子,如果該服務不可用,是可以返回一組預設標籤以提供優雅降級。比如,我們要檢視大品類,它包括:家電、圖書、音響等,這時我們可以在系統初始化中預設裝載這一批兜底資料,當服務不可用,我們則降級到這些兜底資料上,雖然資料可能不完備,但基本可用。使用hystrix可以非常方便的新增優雅降級策略,只需要Override getFallback()方法就可以了。
// 降級方式
@Override
protected List<String> getFallback() {
// 這裡我們可以返回兜底資料
return Collections.emptyList();
}父類的getFallback()是直接丟擲異常的,因此要想開啟優雅降級,必須重寫這個方法,並且需要確保配置withFallbackEnabled被開啟。有的時候我們可能會在降級程式碼中訪問遠端資料(比如訪問redis),那麼當併發量上來之後,也需要保護我們的降級呼叫,此時可以配置withFallbackIsolationSemaphoreMaxConcurrentRequests引數,當呼叫降級程式碼的併發數超過閾值時會丟擲REJECTED_SEMAPHORE_FALLBACK異常
降級有很多種玩法,官方wiki也說了幾種降級策略,我們可以根據實際情況選擇合適的降級策略:
- failfast:表示馬上丟擲異常,即不會降級,比較適用於關鍵服務。
- fail silent:或者叫做failsafe,默默的什麼都不做,併發度最大
- failback static:比如返回0,true,false等
- failback stubbed:返回預設的資料,比如上文的預設標籤
- failback cache via network:通過網路訪問快取資料
使用熔斷器
熔斷器與家裡面的保險絲有些類似,當電流過大,保險絲熔斷以保護我們的電器。在沒有熔斷器機制保護下,我們可能會無節操的重試,這會持續加大服務端壓力,造成惡性迴圈;如果直接關閉重試功能,當服務端又可用的時候,我們又該如何恢復?熔斷器正好適合這種場景:當請求失敗比率(失敗/總數)達到一定閾值後,熔斷器開啟,並休眠一段時間,這段休眠期過後熔斷器將處與半開狀態(half-open),在此狀態下將試探性的放過一部分流量(hystrix只支援single request),如果這部分流量呼叫成功後,再次將熔斷器閉合,否則熔斷器繼續保持開啟並進入下一輪休眠週期。

我們知道了熔斷器的原理後,再重點看一下hystrix都支援哪些熔斷器配置:
| 引數 | 解釋 |
|---|---|
| enabled | 熔斷器是否開啟,預設開啟 |
| errorThresholdPercentage | 熔斷器錯誤比率閾值 |
| forceClosed | 是否強制閉合 |
| forceOpen | 是否強制開啟 |
| requestVolumeThreshold | 表示請求數至少達到多大才進行熔斷計算 |
| sleepWindowInMilliseconds | 半開的觸發試探休眠時間 |
errorThresholdPercentage用來設定錯誤比率,預設50%,比如在一段時間內我們有100個呼叫請求,其中有70個超時了,那麼這段時間的錯誤比率是70%,它大於50%則會觸發熔斷器熔斷。這個值的設定非常重要,他表示我們對錯誤的容忍程度,值越小我們對錯誤的容忍程度越小。強制閉合和強制開啟是兩個執行時調節動態引數,如果強制閉合則忽略統計資訊,熔斷器馬上閉合,相反強制開啟則會保證熔斷器始終處於open狀態。requestVolumeThreshold也是一個比較重要的引數,預設是20,表示至少有20個請求才進行熔斷錯誤比率計算。什麼意思?比如我有19個請求,但是全部失敗了,錯誤比率100%,但也不會觸發熔斷,因為我的volume設定的是20。sleepWindowInMilliseconds是半開試探休眠時間,預設是5000ms,什麼是試探休眠時間?上面我們說到了熔斷器自動恢復的原理:當熔斷器開啟一段時間之後,再放過一部分流量進行試探。這一段時間就是試探休眠時間。如果這個值比較大,意味著我們可能需要一段比較長的恢復時間。如果值比較小,則表示我們需要更好地應對網路抖動情況。
hystrix抽象出HystrixCircuitBreaker介面用來提供熔斷器功能,其在內部維護了AtomicBoolean circuitOpen作為熔斷器狀態開關。下面我們來看一下其實現的核心程式碼:
// 相關配置,就是我們上文在構造方法中的命令配置
private final HystrixCommandProperties properties;
// 統計資訊,按照時間視窗進行統計
private final HystrixCommandMetrics metrics;
// 熔斷器狀態
private AtomicBoolean circuitOpen = new AtomicBoolean(false);
// 熔斷器開啟時間或者上一次半開測試的時間,主要用於從休眠期恢復
private AtomicLong circuitOpenedOrLastTestedTime = new AtomicLong();
// 外部呼叫者主要通過該方法獲取熔斷器狀態
public boolean isOpen() {
if (circuitOpen.get()) {
// 如果熔斷器是開啟的,則返回true
return true;
}
// metric能夠統計服務呼叫情況
HealthCounts health = metrics.getHealthCounts();
// 如果沒有達到熔斷器設定的volumn值則false,肯定是關閉的
if (health.getTotalRequests() < properties.circuitBreakerRequestVolumeThreshold().get()) {
return false;
}
// 如果錯誤比率也沒有達到設定值,也會關閉的
if (health.getErrorPercentage() < properties.circuitBreakerErrorThresholdPercentage().get()) {
return false;
} else {
// 熔斷器開啟
if (circuitOpen.compareAndSet(false, true)) {
//設定熔斷器開啟時間,主要為了進行休眠期判斷
circuitOpenedOrLastTestedTime.set(System.currentTimeMillis());
return true;
} else {
return false;
}
}
}
//做single request測試
public boolean allowSingleTest() {
long timeCircuitOpenedOrWasLastTested = circuitOpenedOrLastTestedTime.get();
// 判斷是否已經過了熔斷器開啟休眠期
if (circuitOpen.get() && System.currentTimeMillis() > timeCircuitOpenedOrWasLastTested + properties.circuitBreakerSleepWindowInMilliseconds().get()) {
// 這裡將上一次測試時間設定為當前時間,主要為了休眠期判斷
if (circuitOpenedOrLastTestedTime.compareAndSet(timeCircuitOpenedOrWasLastTested, System.currentTimeMillis())) {
return true;
}
}
return false;
}後記
第一次聽說熔斷器模式還是在公司的tech郵件討論組裡,同事都在討論一個故障:由於程式碼bug,導致請求時間變長,呼叫方又不斷重試,結果使整組服務崩潰。這件事過後沒多久,公司的RPC框架中就增加了熔斷器機制。最近也在做motan的開原始碼,想在其中增加一個熔斷器的實現,於是翻了翻hystrix原始碼,從中學習到了不少好東西:執行緒池隔離、訊號量隔離、熔斷器的實現、RxJava等等。當然hystrix的功能還不僅限於此,由於篇幅原因,還有很多內容並沒有涉及到,比如請求快取與上下文、collapse請求合併、metrics的實現、hystrix擴充套件鉤子。