我要爬爬蟲(11)-用selenium爬取淘寶商品資訊
阿新 • • 發佈:2019-02-02
思路就是用selenium操作瀏覽器,訪問淘寶,輸入關鍵詞,查詢,用pyquery解析目標資訊,翻頁,儲存到mongodb.
函式定義三個:
1 開啟瀏覽器,查詢初始化,翻頁
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def get_page 2 解析原始碼,選取目標資訊
from pyquery import PyQuery as pq
def crawl():
#用pyquery處理原始碼
source = pq(browser.page_source)
#items()轉化為列舉型別
items = source.find('#mainsrp-itemlist .items .item').items()
for item in items:
body={}
body['image']=item.find('.pic .img').attr('data-src')
body['price']=item('.price').text()[2:]
body['person_buy']=item('.deal-cnt').text()[:-3]
body['name']=item.find('.J_ClickStat').text()
body['store']=item('.shopname').text()
body['location']=item('.location').text()
yield body3 儲存到mongodb
from pymongo import MongoClient
mongo = MongoClient()
db = mongo['Taobao']
goods = db['goods']
def save_to_mongo(data):
try:
football.insert(data)
except:
print('儲存失敗')還有不開啟瀏覽器的模式,加入引數chrome_options即可。
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
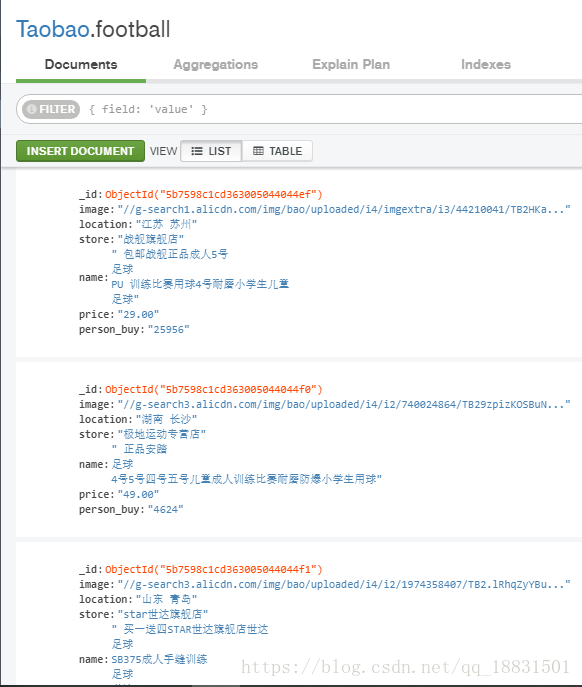
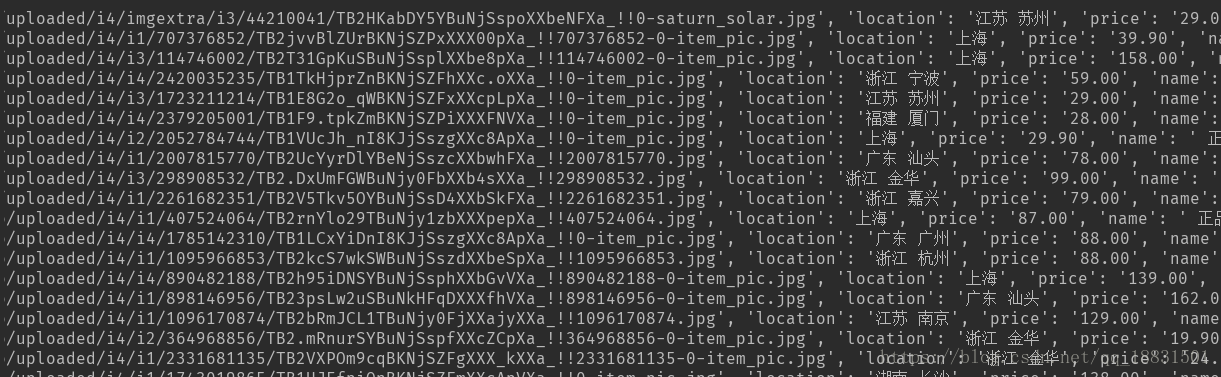
browser.get('http://s.taobao.com')結果展示
mongo中