
ELK+FileBeat日誌分析系統
日誌分析系統重新構建了一下,選定的技術方案是ELK,也就是ElasticSearch, LogStash,Kibana。另外加了Filebeat和Kafka
2017.06.28
這兩天稍微清閒一些,就趁機重新構建了日誌分析系統。沒有寫程式碼,全部使用成熟的技術方案來做資料採集,至於後期如何使用這些資料,還在考慮中,先收集吧。
整體的解決方案如下圖所示:
其中,日誌採集工具使用FileBeat,傳輸工具使用Kafka,資料整理工具使用LogStash叢集,資料儲存工具使用ES。當然,這個系統是可以簡化的,比如說簡化為Filebeat+ElasticSearch,FileBeat+LogStash+ElasticSearch,在不考慮資料Filter和資料處理能力的情況下,這兩種方案都可以。但是建立這個平臺的初衷是要支援整個網站的所有日誌,於是就增加了Kafka,保證資料處理能力。
FileBeat採集資料之後傳輸給Kafka訊息佇列,然後LogStash採集訊息佇列中的資料,作過濾處理,最後將資料傳輸給ES。FileBeat採集資料時就是Json化的,這個日誌採集工具相當輕量級,對系統資源的消耗很少。而LogStash的優點則是有豐富的Filter外掛,用於對資料作粗處理。Kafka和ES的優點就不用說了。為了保證系統穩定性,這裡所有的元件都使用叢集形式。kafka叢集使用三臺虛擬機器,LogStash叢集使用兩臺虛擬機器,而ElasticSearch叢集使用兩臺虛擬機器。下面來分別說一下各個元件的安裝和配置。
FileBeat
FileBeat 是用來替代LogStash-Forwarding的一個元件,是一個輕量級的日誌採集器,相比於LogStash-Forwarding日誌採集器,Filebeat對系統資源的佔用低很多。我這裡用到的伺服器是Windows,當然也可以放在Linux機器上,配置方法一致。
首先要下載filebeat,下載地址為:
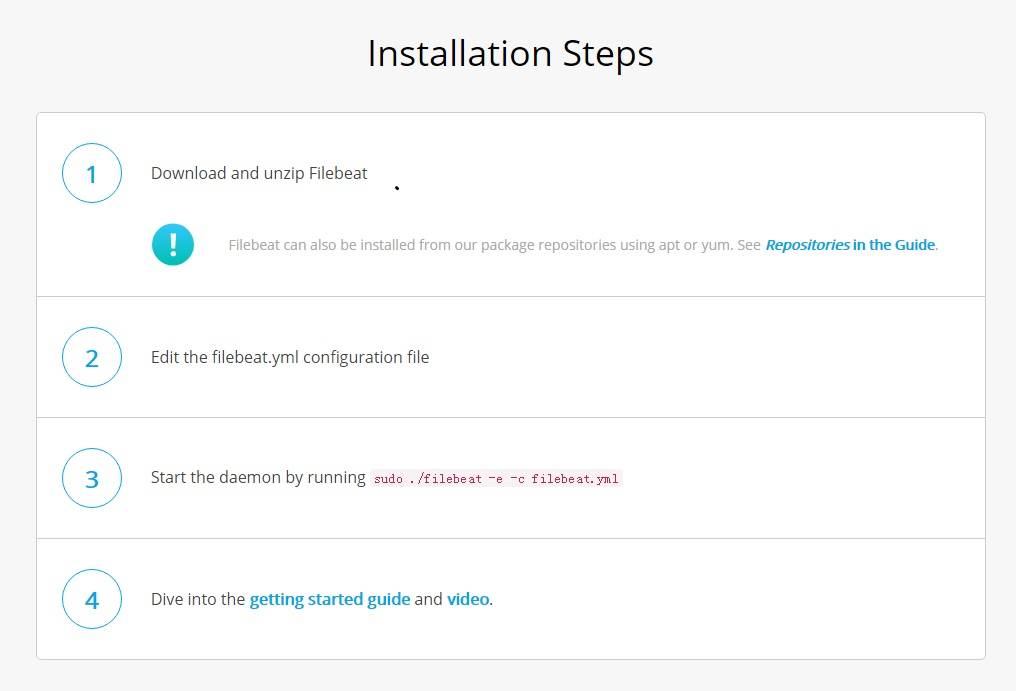
我用的版本是5.2.2,整個安裝目錄如下圖所示:
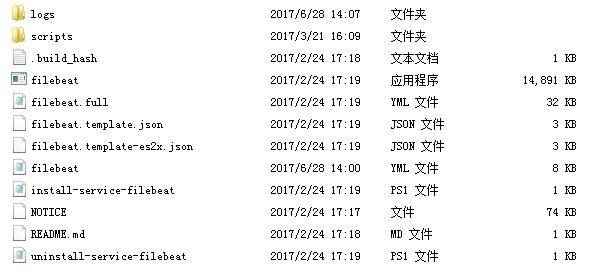
其中filebeat.yml表示配置檔案,filebeat.template.json表示資料輸出的json格式。配置檔案詳情如下:
filebeat.prospectors:
- input_type: log
# Paths that should be crawled and fetched. Glob based paths. 這份配置檔案中,定義了兩種型別的日誌,分別是Error和Info。日誌輸出可以是ES,可以使LogStash也可以是Kafka,不過由於Kafka運維還沒開過來,我先臨時寫入到了LogStash中。
配置檔案寫完之後,就可以啟動FileBeat了,Linux下的啟動沒啥好說的,./filebeat即可。而Windows下的安裝有點繁瑣,需要使用powershell來執行指令碼。開啟CMD視窗,具體的安裝程式碼如下:
PowerShell.exe -ExecutionPolicy UnRestricted -File .\install-service-filebeat.ps1
具體執行如下圖:
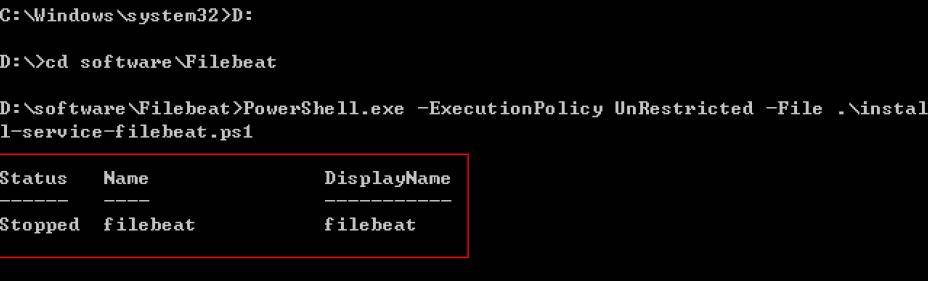
安裝之後,在服務視窗下啟動,或者是在CMD視窗執行net start filebeat即可。
LogStash
LogStash 的主要功能是對FileBeat採集到的粗資料作過濾,然後將過濾之後的資料寫入到ES中。如果不需要對資料過濾,可以直接從FileBeat或者Kafka將資料寫入ES。不過為了實現日誌時間解析、冗餘欄位濾除等功能,這裡還是選擇增加LogStash的使用。LogStash的安裝配置過程如下。
首先是下載安裝包,我這裡使用的版本是2.4.0,在Linux主機上執行;
wget https://download.elastic.co/logstash/logstash/logstash-2.4.0.tar.gz sudo tar -zxf logstash-2.4.0.tar.gz -C /usr/local/ cd /usr/local/logstash-2.4.0 sudo vim simple.conf
這段程式碼就是下載安裝包、解壓安裝包、建立配置檔案的過程。建立simple.conf之後,我在其中做的配置如下:
input{
beats{
codec => plain{charset => "UTF-8"}
port => "5044"
}
}
filter{
mutate{
remove_field => "@version"
remove_field => "offset"
remove_field => "input_type"
remove_field => "beat"
remove_field => "tags"
}
ruby{
code => "event.timestamp.time.localtime"
}
}
output{
elasticsearch{
codec => plain{charset => "UTF-8"}
hosts => ["106.205.10.138", "106.205.10.139"]
}
}
其中input選擇將filebeat的資料來源作為接入資料,通過output將資料推送到ES中,filter中過濾掉冗餘欄位。而 code => “event.timestamp.time.localtime” 則表示將時間戳從UTC時間改到本地時間,這裡是東八區,所以加了八小時。
配置完成之後,啟動LogStash,執行程式碼如下;
bin/logstash -f simple.conf
此時就完成了logstash的安裝和配置。
ElasticSearch
尾聲
SO, 到這裡,整個安裝配置過程結束,看一下效果先:
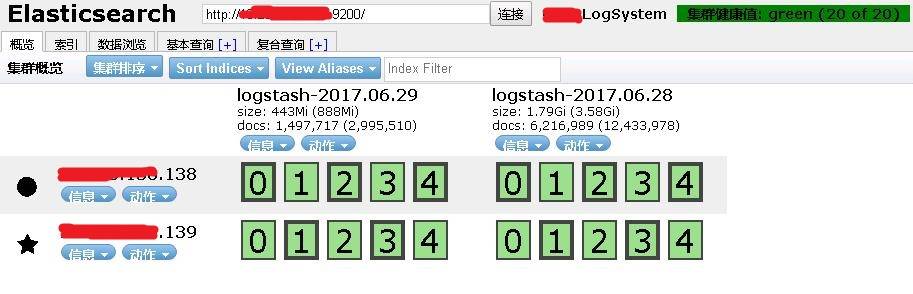
這是測試資料採集兩天之後的狀態。後續的資料分析在此基礎上進行,可能用Kibana,也可能自己開發,確定的時候會繼續寫出來。