使用Python抓取網易雲音樂所有歌手資訊
阿新 • • 發佈:2019-02-02
思路
1. 構造請求頁面的URL
2. 請求資料
請求資料使用的是requests包,當請求的網址沒有錯誤並且status_code為200時,返回網頁的內容。
注意:這裡並沒改變請求的headers,也沒有使用代理
3. 解析資料
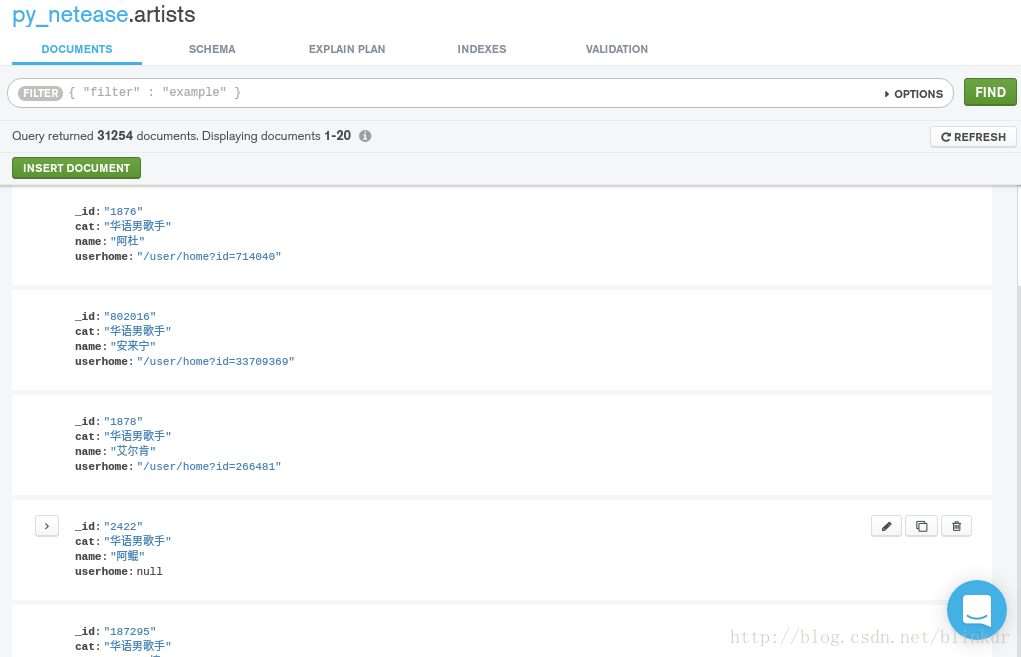
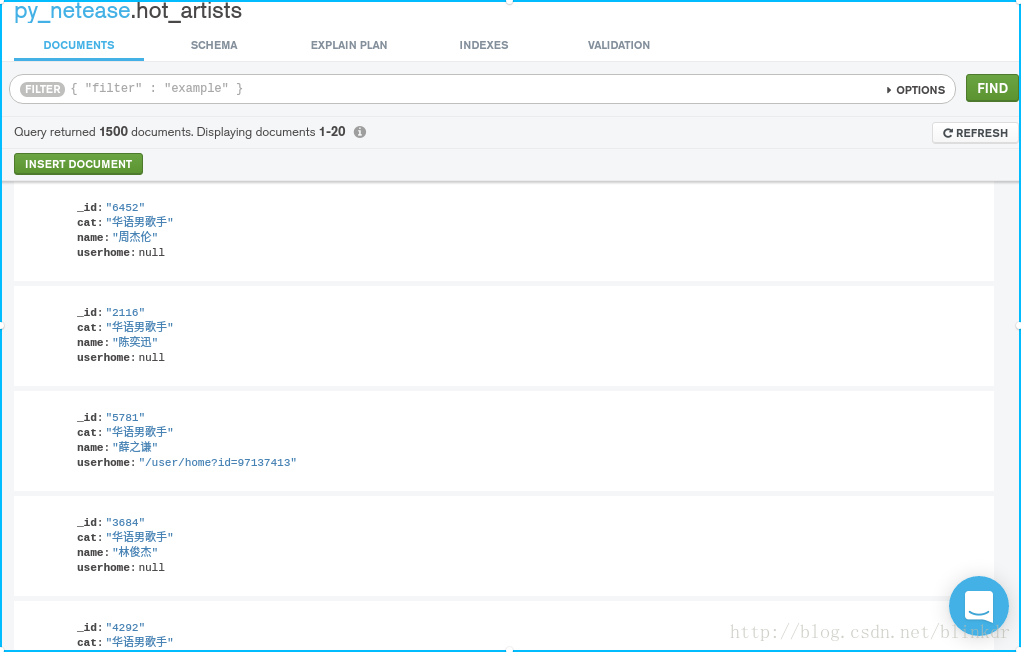
使用lxml包進行html解析,抓取包括歌手id,name,cat,userhome四個資訊
4. 儲存到MongoDB
儲存時將歌手id作為資料表的’_id’,由於歌手id唯一性,可以防止資料庫中的文件重複插入
import requests
from requests.exceptions import RequestException
from 其他
1. 關於多執行緒
最簡單的方法就是使用concurrent.futures包,其他也可以使用threading包。由於抓取屬於IO密集型,因此使用多執行緒會明顯改善效率。
2. 關於抓取失敗
有可能是IP被禁止訪問,返回503錯誤
3. 最後,發一下效果圖,所有歌手一共有3w+條資料,而熱門歌手有1500條資料