
Python 並行分散式框架之 Celery
Celery (芹菜)是基於Python開發的分散式任務佇列。它支援使用任務佇列的方式在分佈的機器/程序/執行緒上執行任務排程。
架構設計
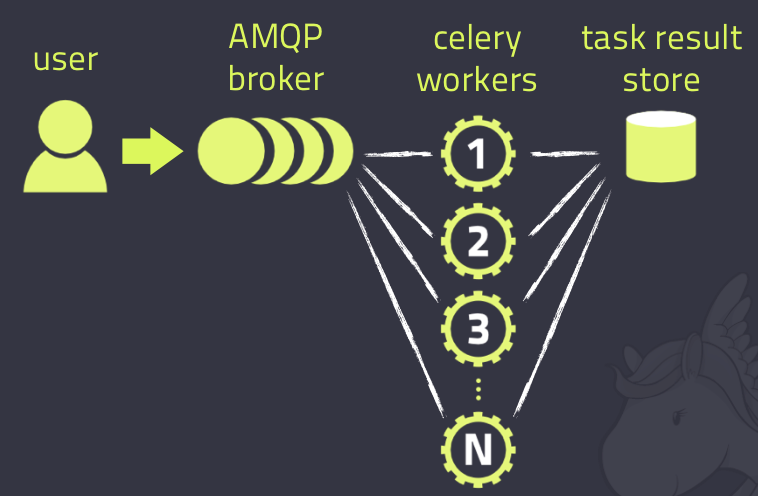
Celery的架構由三部分組成,訊息中介軟體(message broker),任務執行單元(worker)和任務執行結果儲存(task result store)組成。
-
訊息中介軟體
Celery本身不提供訊息服務,但是可以方便的和第三方提供的訊息中介軟體整合。包括,RabbitMQ, Redis, MongoDB (experimental), Amazon SQS (experimental),CouchDB (experimental), SQLAlchemy
(experimental),Django ORM (experimental), IronMQ -
任務執行單元
Worker是Celery提供的任務執行的單元,worker併發的執行在分散式的系統節點中。
-
任務結果儲存
Task result store用來儲存Worker執行的任務的結果,Celery支援以不同方式儲存任務的結果,包括AMQP, Redis,memcached, MongoDB,SQLAlchemy, Django ORM,Apache Cassandra, IronCache
另外, Celery還支援不同的併發和序列化的手段
-
序列化
pickle, json, yaml
, msgpack. zlib, bzip2 compression, Cryptographic message signing 等等
安裝和執行
Celery的安裝過程略為複雜,下面的安裝過程是基於我的AWS EC2的Linux版本的安裝過程,不同的系統安裝過程可能會有差異。大家可以參考官方文件。
首先我選擇RabbitMQ作為訊息中介軟體,所以要先安裝RabbitMQ。作為安裝準備,先更新YUM。
sudo yum -y updateRabbitMQ是基於erlang的,所以先安裝erlang
# Add and enable relevant application repositories: # Note: We are also enabling third party remi package repositories. wget http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm wget http://rpms.famillecollet.com/enterprise/remi-release-6.rpm sudo rpm -Uvh remi-release-6*.rpm epel-release-6*.rpm # Finally, download and install Erlang: yum install -y erlang
然後安裝RabbitMQ
# Download the latest RabbitMQ package using wget:
wget
# Add the necessary keys for verification:
rpm --import
# Install the .RPM package using YUM:
yum install rabbitmq-server-3.2.2-1.noarch.rpm啟動RabbitMQ服務
rabbitmq-server startRabbitMQ服務已經準備好了,然後安裝Celery, 假定你使用pip來管理你的python安裝包
pip install Celery為了測試Celery是否工作,我們執行一個最簡單的任務,編寫tasks.py
from celery import Celery
app = Celery('tasks', backend='amqp', broker='amqp://[email protected]//')
app.conf.CELERY_RESULT_BACKEND = 'db+sqlite:///results.sqlite'
@app.task
def add(x, y):
return x + y在當前目錄執行一個worker,用來執行這個加法的task
celery -A tasks worker --loglevel=info其中-A引數表示的是Celery App的名字。注意這裡我使用的是SQLAlchemy作為結果儲存。對應的python包要事先安裝好。
worker日誌中我們會看到這樣的資訊
- ** ---------- [config]
- ** ---------- .> app: tasks:0x1e68d50
- ** ---------- .> transport: amqp://guest:**@localhost:5672//
- ** ---------- .> results: db+sqlite:///results.sqlite
- *** --- * --- .> concurrency: 8 (prefork)其中,我們可以看到worker預設使用prefork來執行併發,並設定併發數為8
下面的任務執行的客戶端程式碼:
from tasks import add
import time
result = add.delay(4,4)
while not result.ready():
print "not ready yet"
time.sleep(5)
print result.get()用python執行這段客戶端程式碼,在客戶端,結果如下
not ready
8Work日誌顯示
[2015-03-12 02:54:07,973: INFO/MainProcess] Received task: tasks.add[34c4210f-1bc5-420f-a421-1500361b914f]
[2015-03-12 02:54:08,006: INFO/MainProcess] Task tasks.add[34c4210f-1bc5-420f-a421-1500361b914f] succeeded in 0.0309705100954s: 8這裡我們可以發現,每一個task有一個唯一的ID,task非同步執行在worker上。
這裡要注意的是,如果你執行官方文件中的例子,你是無法在客戶端得到結果的,這也是我為什麼要使用SQLAlchemy來儲存任務執行結果的原因。官方的例子使用AMPQ,有可能Worker在列印日誌的時候取出了task的執行結果顯示在worker日誌中,然而AMPQ作為一個訊息佇列,當訊息被取走後,佇列中就沒有了,於是客戶端總是無法得到任務的執行結果。不知道為什麼官方文件對這樣的錯誤視而不見。
如果大家想要對Celery做更進一步的瞭解,請參考官方文件
相關推薦
Python 並行分散式框架之 Celery
Celery (芹菜)是基於Python開發的分散式任務佇列。它支援使用任務佇列的方式在分佈的機器/程序/執行緒上執行任務排程。 架構設計 Celery的架構由三部分組成,訊息中介軟體(message broker),任務執行單元(worker)和任務執行結果儲存(tas
Python 並行分散式框架:Celery 超詳細介紹
先來一張圖,這是在網上最多的一張Celery的圖了,確實描述的非常好 Celery的架構由三部分組成,訊息中介軟體(message broker),任務執行單元(worker)和任務執行結果儲存(task result store)組成。 訊息中介軟體
[原始碼解析] 並行分散式框架 Celery 之架構 (2)
# [原始碼解析] 並行分散式框架 Celery 之架構 (2) [toc] ## 0x00 摘要 Celery是一個簡單、靈活且可靠的,處理大量訊息的分散式系統,專注於實時處理的非同步任務佇列,同時也支援任務排程。 本系列將通過原始碼分析,和大家一起深入學習 Celery。本文是系列第二篇,繼續探究
[原始碼解析] 並行分散式框架 Celery 之 worker 啟動 (1)
# [原始碼解析] 並行分散式框架 Celery 之 worker 啟動 (1) [toc] ## 0x00 摘要 Celery是一個簡單、靈活且可靠的,處理大量訊息的分散式系統,專注於實時處理的非同步任務佇列,同時也支援任務排程。Celery 是呼叫其Worker 元件來完成具體任務處理。 ```s
[原始碼解析] 並行分散式框架 Celery 之 worker 啟動 (2)
# [原始碼解析] 並行分散式框架 Celery 之 worker 啟動 (2) [toc] ## 0x00 摘要 Celery是一個簡單、靈活且可靠的,處理大量訊息的分散式系統,專注於實時處理的非同步任務佇列,同時也支援任務排程。Celery 是呼叫其Worker 元件來完成具體任務處理。 前文講了
並行分散式框架 Celery 的分享理解
Celery 官網:http://www.celeryproject.org/ Celery 官方文件英文版:http://docs.celeryproject.org/en/latest/index.html Celery 官方文件中文版:http://docs.jinkan.or
SSM+dubbo+zookeeper簡單搭建分散式框架之專案配置
基於我們的需要的環境、條件準備好後,就可以搭建專案了。github專案地址:https://github.com/dairuijie/dubbo_demo1、新建四個maven 專案 分別是dubbo_core 這個是統一配置pom.xml 其他三個pom.xml 依賴
Dubbo分散式框架之token驗證
Dubbo提供了對消費者的 token驗證,防止消費者: 1.防止消費者繞過 註冊中心訪問提供者 2.在註冊中心控制權限,以決定要不要下發令牌給消費者。 3.註冊中心可靈活改變授權方式,而不需要修改或升級提供者。配置方法:提供商配置:1.伺服器級別
python爬蟲Scrapy框架之中間件
gin 關於 pre ces alt python類 分享 新建 爬蟲 Downloader Middleware處理的過程主要在調度器發送requests請求的時候以及網頁將response結果返回給spider的時候, 所以說下載中間件是結余Scrapy的request
分散式爬蟲之celery
以爬douban小說為例 首先啟動Redis,新建檔案crawl_douban.py import requests from bs4 import BeautifulSoup import time from celery import Celery
python web自制框架之-完整服務端實現
今天我們做下服務端的完整實現,把路由與模型分開來。首先是run函式,實現接收請求與返回客戶端資料1.def run(host='', port=3000): """ 啟動伺服器 """ # 初始化 socket 套路 log(
python爬蟲Scrapy框架之增量式爬蟲
obj lib show prop open html back extract hot 一 增量式爬蟲 什麽時候使用增量式爬蟲: 增量式爬蟲:需求 當我們瀏覽一些網站會發現,某些網站定時的會在原有的基礎上更新一些新的數據。如一些電影網站會實時更新最近熱門的電影。那麽,當我
python框架之 Tornado 學習筆記(一)
tornado pythontornado 一個簡單的服務器的例子:首先,我們需要安裝 tornado ,安裝比較簡單: pip install tornado 測試安裝是否成功,可以打開python 終端,輸入: import tornado.https
Python ORM框架之 Peewee入門
lob shortcuts pymysql 主鍵 也會 roo username fault 有意思 之前在學Django時,發現它的模型層非常好用,把對數據庫的操作映射成對類、對象的操作,避免了我們直接寫在Web項目中SQL語句,當時想,如果這個模型層可以獨立出來使用
2017.07.26 Python網絡爬蟲之Scrapy爬蟲框架
返回 scripts http ref select 文本 lang bsp str 1.windows下安裝scrapy:cmd命令行下:cd到python的scripts目錄,然後運行pip install 命令 然後pycharmIDE下就有了Scrapy:
Python Web框架之Django初探(一)
python django easy_install pip Python Web框架之Django初探 Django是一個開放源代碼的Web應用框架,由Python寫成。采用了MVC的框架模式,即模型M,視圖V和控制器C。它最初是被開發來用於管理勞倫斯出版集團旗下的一些以新聞內容為主的網站
Python web 框架之 Django 基礎搭建服務
XML 運行 端口被占用 占用 tin 1.8 whl 如果 pro 1. 需要安裝 Python 和 Django 環境,Python 環境的安裝我就不在多說了 2. 安裝框架 Django Django 安裝,推薦先裝個 pip吧,easyinstall也可以,
python-django rest framework框架之dispatch方法源碼分析
pytho fault quest 變量 miss imp ons esp cati 1.Django的 CBV 中在請求到來之後,都要執行dispatch方法,dispatch方法根據請求方式不同觸發 get/post/put等方法 class APIView(View
python-django rest framework框架之分頁
link 自己實現 -i man model 三種 imp *** efault 1. 以前django做的分頁組件當數據量特別大的時候,性能不是很高,有以下三種方式處理: a. 記錄當前訪問頁的最後一條數據id,往後取多少條 b. 最多顯示1
python-django rest framework框架之路由
dex frame self elf rgs nat register model create 路由 第一類:原始繼承APIView # http://127.0.0.1:8000/api/v1/auth/ url(r‘