
lucene字典實現原理
1 lucene字典
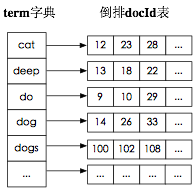
使用lucene進行查詢不可避免都會使用到其提供的字典功能,即根據給定的term找到該term所對應的倒排文件id列表等資訊。實際上lucene索引檔案字尾名為tim和tip的檔案實現的就是lucene的字典功能。
怎麼實現一個字典呢?我們馬上想到排序陣列,即term字典是一個已經按字母順序排序好的陣列,陣列每一項存放著term和對應的倒排文件id列表。每次載入索引的時候只要將term陣列載入記憶體,通過二分查詢即可。這種方法查詢時間複雜度為Log(N),N指的是term數目,佔用的空間大小是O(N*str(term))。排序陣列的缺點是消耗記憶體,即需要完整儲存每一個term,當term數目多達上千萬時,佔用的記憶體將不可接受。
2 常用字典資料結構
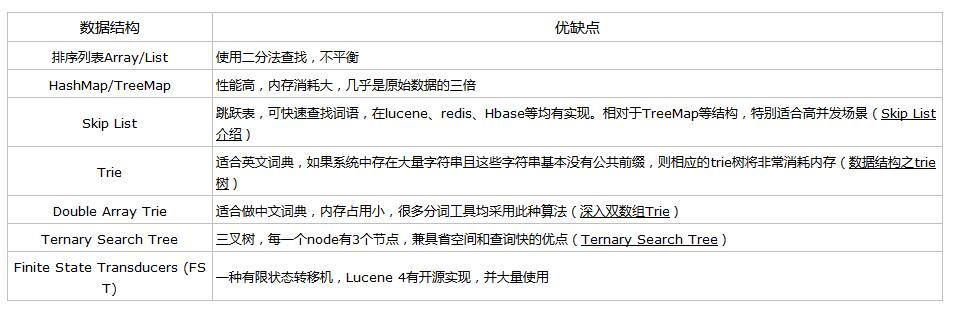
很多資料結構均能完成字典功能,總結如下。
3 FST原理簡析
lucene從4開始大量使用的資料結構是FST(Finite State Transducer)。FST有兩個優點:1)空間佔用小。通過對詞典中單詞字首和字尾的重複利用,壓縮了儲存空間;2)查詢速度快。O(len(str))的查詢時間複雜度。
1)插入“cat”
插入cat,每個字母形成一條邊,其中t邊指向終點。

2)插入“deep”
與前一個單詞“cat”進行最大字首匹配,發現沒有匹配則直接插入,P邊指向終點。
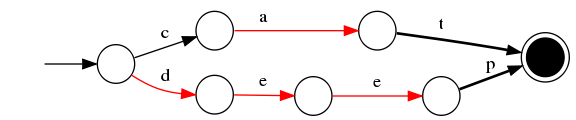
3)插入“do”
與前一個單詞“deep”進行最大字首匹配,發現是d,則在d邊後增加新邊o,o邊指向終點。
4)插入“dog”
與前一個單詞“do”進行最大字首匹配,發現是do,則在o邊後增加新邊g,g邊指向終點。
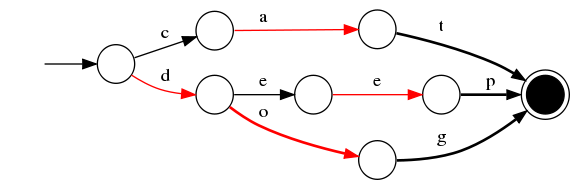
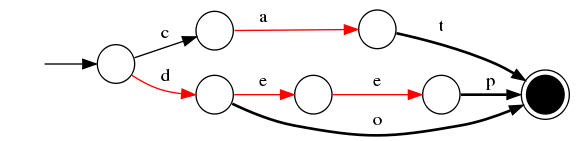
5)插入“dogs”
與前一個單詞“dog”進行最大字首匹配,發現是dog,則在g後增加新邊s,s邊指向終點
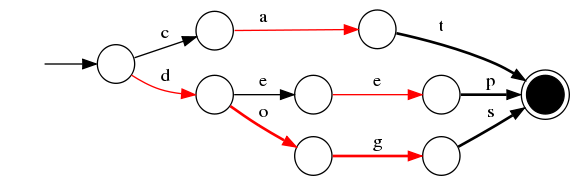
最終我們得到了如上一個有向無環圖。利用該結構可以很方便的進行查詢,如給定一個term “dog”,我們可以通過上述結構很方便的查詢存不存在,甚至我們在構建過程中可以將單詞與某一數字、單詞進行關聯,從而實現key-value的對映。