
分享幾個小小的python爬蟲供大家娛樂(人民日報要聞---to be continued )
阿新 • • 發佈:2019-02-02
-1-實現人民日報要聞的抓取
說明文件:
使用包 : lxml,requests,urllib2
起始url :人民日報主頁
爬取目標 :人民日報要聞
- 要聞連結
- 要聞標題
- 要聞時間
- 要聞來源
- 要聞內容
輸出格式: HTML表格檔案
思路 : 首先收集要爬取頁面的所有連結,之後逐個進行爬取
實現程式碼:
#-*-coding:utf8-*-
#這段程式碼寫得不是很好,許多地方都有要改善的地方,大神勿噴^-^
import requests
import urllib2
from lxml import etree
from multiprocessing.dummy import 執行結果:
爬取數量取決於中國人民網首頁要聞一欄的文章數量
執行成功產生content.html檔案
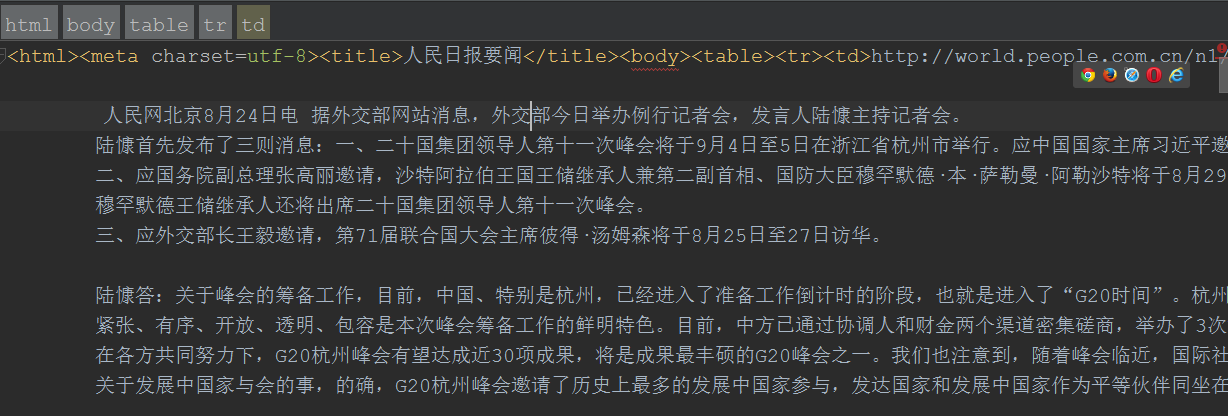
可以在瀏覽器中直接開啟

我是一條小小的分割線,我還是第一條 ^-^