
mysql資料庫事務型別
資料庫事務有不同的隔離級別,不同的隔離級別對鎖的使用是不同的,鎖的應用最終導致不同事務的隔離級別。
隔離性分為四個級別:
1讀未提交:(Read Uncommitted)
2讀已提交(Read Committed) 大多數資料庫預設的隔離級別
3可重複讀(Repeatable-Read) mysql資料庫所預設的級別
4序列化(serializable)
四個級別的具體實現和不同的請下面細讀:
首先程式是可以併發執行的,同樣,在MySQL中,一個表可以由兩個或多個程序同時來讀寫資料,這是沒有問題的。
比如,此時有兩個程序來讀資料,這也沒什麼問題,允許。但是如果一個程序在讀某一行的資料的過程中,另一個在程序又往這一行裡面寫資料(改、刪),那結果會是如何?同樣,如果兩個程序都同時對某一行資料進行更改,以誰的更改為準?那結果又會怎樣,不敢想象,是不是資料就被破壞掉了。所以此時是衝突的。
既然會衝突就要想辦法解決,靠誰來解決,這時候就是靠鎖機制來維護了。怎麼使用鎖來使他們不衝突?
在事務開始的時候可以給要準備寫操作的這一行資料加一個排它鎖,如果是讀操作,就給該行資料一個讀鎖。這樣之後,在修改該行資料的時候,不讓其他程序對該行資料有任何操作。而讀該行資料的時候,其他程序不能更改,但可以讀。讀或寫完成時,釋放鎖,最後commit提交。這時候讀寫就分離開了,寫和寫也就分離開了。
注意:此時加鎖和釋放鎖的過程由mysql資料庫自身來維護,不需要我們人為干涉。mysql開發者給這個解決衝突的方案起了一個名字叫做:讀未提交:(Read Uncommitted)。這也就是事務的第一個隔離性。
但是這個程度的隔離性僅僅是不夠的。看下面的測試結果:
1)A修改事務級別為:未提交讀。並開始事務,對user表做一次查詢
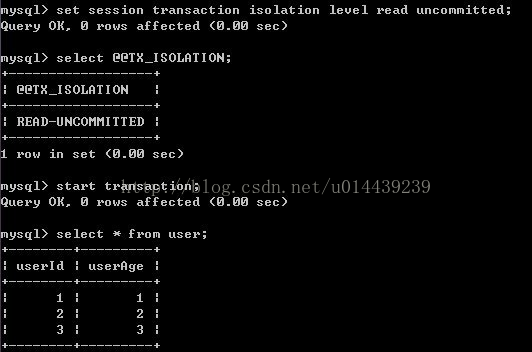
2)B事務更新一條記錄

3)此時B事務還未提交,A在事務內做一次查詢,發現查詢結果已經改變

4)B進行事務回滾
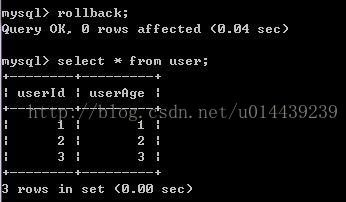
5)A再做一次查詢,查詢結果又變回去了
由試驗得知:在一個程序的事務當中,我更改了其中的一行資料,但是我修改完之後就釋放了鎖,這時候另一個程序讀取了該資料,此時先前的事務是還未提交的,直到我回滾了資料,另一個程序讀的資料就變成了無用的或者是錯誤的資料。我們通常把這種資料叫做髒資料,這種情況讀出來的資料叫做賍讀。
怎麼辦?依然是靠鎖機制。無非是鎖的位置不同而已,之前是隻要操作完該資料就立馬釋放掉鎖,現在是把釋放鎖的位置調整到事務提交之後,此時在事務提交前,其他程序是無法對該行資料進行讀取的,包括任何操作。那麼資料庫為此種狀態的資料庫操作規則又給了一個名字叫做:讀已提交(
在某些情況下,不可重複讀並不是問題,比如我們多次查詢某個資料當然以最後查詢得到的結果為主。但在另一些情況下就有可能發生問題,例如對於同一個資料A和B依次查詢就可能不同,A和B就可能打起來了……
繼續看下面的測試結果:
1)把隔離性調為READ-COMMITTED(讀取提交內容)設定A的事務隔離級別,並進入事務做一次查詢

2)B開始事務,並對記錄進行修改

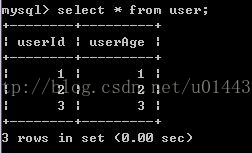
3)A再對user表進行查詢,發現記錄沒有受到影響
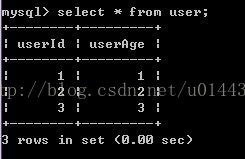
4)B提交事務

5)A再對user表查詢,發現記錄被修改

試驗進行到這裡,你會發現,在同一個事務中如果兩次讀取相同的資料時,最後的結果卻不一致。這裡我們把這種現象稱為:不可重複讀。因為在第一個事務讀取了資料之後,此時另一個事務把該資料給修改了,這時候事務提交,那麼另一個事務在第二次讀取的時候,結果就不一樣,一個修改前的,一個是修改後的。
但是細心的你會發現,既然你說此種隔離性是在事務提交後才釋放鎖,那麼在試驗過程中,在該資料未提交前,另一個事務為什麼也是仍然可以讀取的呀。是我說錯了嗎?不是的,在這裡mysql使用了一個併發版本控制機制,他們把它叫做MVCC,通俗的也就是說:mysql為了提高系統的併發量,在事務未提交前,雖然事務內操作的資料是鎖定狀態,但是另一個事務仍然可以讀取,大多數資料庫預設的就是這個級別的隔離性。但mysql不是。
而且不只是在更新資料時出現這個問題,在插入資料時仍然會造成類似的這樣一種現象:mysql雖然鎖住了正在操作的資料行,但它仍然不會阻止另一個事務往表插入新行新的資料。比如:一個事務讀取或更新了表裡的所有行,接者又有另一個事務往該表裡插入一個新行,在事務提交後。原來讀取或更改過資料的事務又第二次讀取了相同的資料,這時候這個事務中兩次讀取的結果集行數就不一樣。原來更新了所有行,而現在讀出來發現竟然還有一行沒有更新。這就是所謂的幻讀。
為了防止同事務中兩次讀取資料不一致,(包括不可重讀和幻讀),接下來該如何繼續做呢?!
mysql依然採取的是MVCC併發版本控制來解決這個問題。具體是:如果事務中存在多次讀取同樣的資料,MySQL第一次讀的時候仍然會保持選擇讀最新提交事務的資料,當第一次之後,之後再讀時,mysql會取第一次讀取的資料作為結果。這樣就保證了同一個事務多次讀取資料時資料的一致性。這時候,mysql把這種解決方案叫做:可重複度(Repeatable-Read),也就是上述所寫的第三個隔離性,也是mysql預設的隔離級別。
注意:幻讀和不可重複讀(Read Committed)都是讀取了另一條已經提交的事務(這點就髒讀不同),所不同的是不可重複讀查詢的都是同一個資料項,而幻讀針對的是一批資料整體(比如資料的個數)。
說到這裡,真的就完事了嗎?到這裡其實mysql並未完全解決資料的一致性問題。只是在讀取上做了手腳,解決了傳統意義上的幻讀和不可重複讀。
例子:1 A事務開啟,B事務開啟。
2 B事務往表裡面插入了一條資料,但還並未提交。
3 A事務開始查詢了,並沒有發現B事務這次插入的資料。然後此時B事務提交了資料。
4 於是乎,A事務就以為沒有這條資料,就開始新增這條資料,但是卻發現,發生了資料 重複衝突。
最後這個時候,該我們的最後一種隔離級別也是最高的隔離級:別序列化(serializable)登場了。
該隔離級別會自動在鎖住你要操作的整個表的資料,如果另一個程序事務想要操作表裡的任何資料就需要等待獲得鎖的程序操作完成釋放鎖。可避免髒讀、不可重複讀、幻讀的發生。當然效能會下降很多,會導致很多的程序相互排隊競爭鎖。
後記:以上所說的四種隔離性的鎖機制應用是資料庫自動完成的,不需要人為干預。隔離級別的設定只對當前連結有效。對於使用MySQL命令視窗而言,一個視窗就相當於一個連結,當前視窗設定的隔離級別只對當前視窗中的事務有效