
Windows伺服器高併發處理IOCP(完成埠)詳細說明
本系列裡完成埠的程式碼在兩年前就已經寫好了,但是由於許久沒有寫東西了,不知該如何提筆,所以這篇文件總是在醞釀之中……醞釀了兩年之後,終於決定開始動筆了,但願還不算晚…..
這篇文件我非常詳細並且圖文並茂的介紹了關於網路程式設計模型中完成埠的方方面面的資訊,從API的用法到使用的步驟,從完成埠的實現機理到實際使用的注意事項,都有所涉及,並且為了讓朋友們更直觀的體會完成埠的用法,本文附帶了有詳盡註釋的使用MFC編寫的圖形介面的示例程式碼。
我的初衷是希望寫一份網際網路上能找到的最詳盡的關於完成埠的教學文件,而且讓對Socket程式設計略有了解的人都能夠看得懂,都能學會如何來使用完成埠這麼優異的網路程式設計模型
由於篇幅原因,本文假設你已經熟悉了利用Socket進行TCP/IP程式設計的基本原理,並且也熟練的掌握了多執行緒程式設計技術,太基本的概念我這裡就略過不提了,網上的資料應該遍地都是。
本文件凝聚著筆者心血,如要轉載,請指明原作者及出處,謝謝!不過程式碼沒有版權,可以隨便散播使用,歡迎改進,特別是非常歡迎能夠幫助我發現Bug的朋友,以更好的造福大家。^_^
本文配套的示例原始碼下載地址(在我的下載空間裡,已經補充上了客戶端的程式碼)
(裡面的程式碼包括VC++2008/VC++2010編寫的完成埠伺服器端和客戶端的程式碼,還包括一個對伺服器端進行壓力測試的客戶端,都是經過我精心除錯過,並且帶有非常詳盡的程式碼註釋的。當然,作為教學程式碼,為了能夠使得程式碼結構清晰明瞭,我還是對程式碼有所簡化,如果想要用於產品開發,最好還是需要自己再完善一下,另外我的工程是用2010編寫的,附帶的2008工程不知道有沒有問題,但是其中程式碼都是一樣的,暫未測試)
忘了囑咐一下了,文章篇幅很長很長,基本涉及到了與完成埠有關的方方面面,一次看不完可以分好幾次,中間注意休息,好身體才是咱們程式設計師最大的本錢!
對了,還忘了囑咐一下,因為本人的水平有限,雖然我反覆修正了數遍,但文章和示例程式碼裡肯定還有我沒發現的錯誤和紕漏,希望各位一定要指出來,拍磚、噴我,我都能Hold住,但是一定要指出來,我會及時修正,因為我不想讓文中的錯誤傳遍網際網路,禍害大家。
OK, Let’s go ! Have fun !
目錄:
1. 完成埠的優點
2. 完成埠程式的執行演示
3. 完成埠的相關概念
4. 完成埠的基本流程
5. 完成埠的使用詳解
6. 實際應用中應該要注意的地方
一. 完成埠的優點
1. 我想只要是寫過或者想要寫C/S模式網路伺服器端的朋友,都應該或多或少的聽過完成埠的大名吧,完成埠會充分利用Windows核心來進行I/O的排程,是用於C/S通訊模式中效能最好的網路通訊模型,沒有之一;甚至連和它效能接近的通訊模型都沒有。
2. 完成埠和其他網路通訊方式最大的區別在哪裡呢?
(1) 首先,如果使用“同步”的方式來通訊的話,這裡說的同步的方式就是說所有的操作都在一個執行緒內順序執行完成,這麼做缺點是很明顯的:因為同步的通訊操作會阻塞住來自同一個執行緒的任何其他操作,只有這個操作完成了之後,後續的操作才可以完成;一個最明顯的例子就是咱們在MFC的介面程式碼中,直接使用阻塞Socket呼叫的程式碼,整個介面都會因此而阻塞住沒有響應!所以我們不得不為每一個通訊的Socket都要建立一個執行緒,多麻煩?這不坑爹呢麼?所以要寫高效能的伺服器程式,要求通訊一定要是非同步的。
(2) 各位讀者肯定知道,可以使用使用“同步通訊(阻塞通訊)+多執行緒”的方式來改善(1)的情況,那麼好,想一下,我們好不容易實現了讓伺服器端在每一個客戶端連入之後,都要啟動一個新的Thread和客戶端進行通訊,有多少個客戶端,就需要啟動多少個執行緒,對吧;但是由於這些執行緒都是處於執行狀態,所以系統不得不在所有可執行的執行緒之間進行上下文的切換,我們自己是沒啥感覺,但是CPU卻痛苦不堪了,因為執行緒切換是相當浪費CPU時間的,如果客戶端的連入執行緒過多,這就會弄得CPU都忙著去切換執行緒了,根本沒有多少時間去執行執行緒體了,所以效率是非常低下的,承認坑爹了不?
(3) 而微軟提出完成埠模型的初衷,就是為了解決這種"one-thread-per-client"的缺點的,它充分利用核心物件的排程,只使用少量的幾個執行緒來處理和客戶端的所有通訊,消除了無謂的執行緒上下文切換,最大限度的提高了網路通訊的效能,這種神奇的效果具體是如何實現的請看下文。
3. 完成埠被廣泛的應用於各個高效能伺服器程式上,例如著名的Apache….如果你想要編寫的伺服器端需要同時處理的併發客戶端連線數量有數百上千個的話,那不用糾結了,就是它了。
二. 完成埠程式的執行演示
首先,我們先來看一下完成埠在筆者的PC機上的執行表現,筆者的PC配置如下:
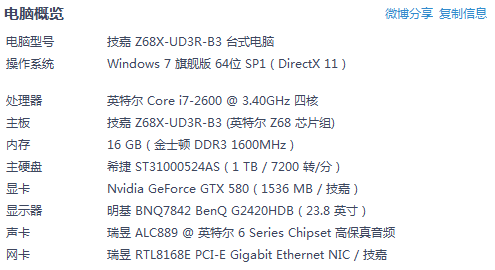
大體就是i7 2600 + 16GB記憶體,我以這臺PC作為伺服器,簡單的進行了如下的測試,通過Client生成3萬個併發執行緒同時連線至Server,然後每個執行緒每隔3秒鐘傳送一次資料,一共傳送3次,然後觀察伺服器端的CPU和記憶體的佔用情況。
如圖2所示,是客戶端3萬個併發執行緒傳送共傳送9萬條資料的log截圖
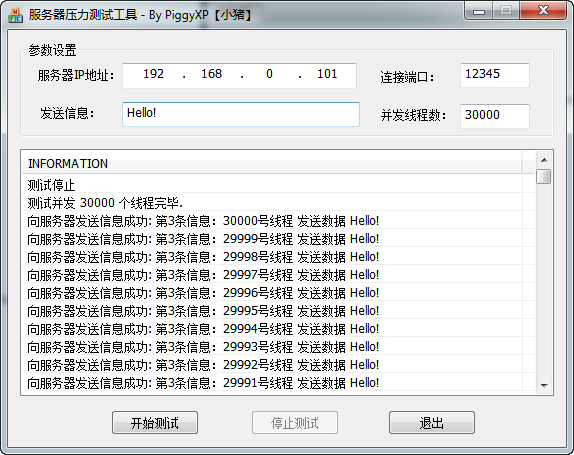
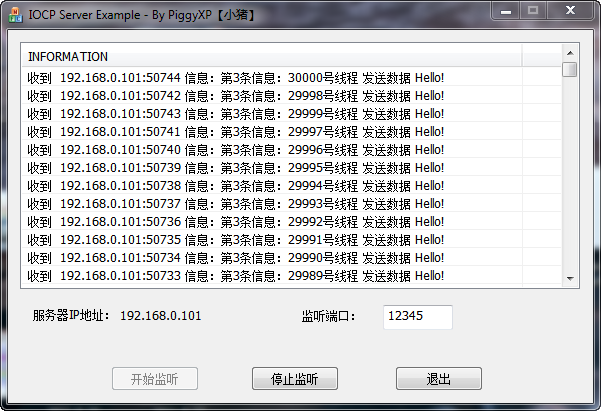
圖3是伺服器端接收完畢3萬個併發執行緒和每個執行緒的3份資料後的log截圖
最關鍵是圖4,圖4是伺服器端在接收到28000個併發執行緒的時候,CPU佔用率的截圖,使用的軟體是大名鼎鼎的Process Explorer,因為相對來講這個比自帶的工作管理員要準確和精確一些。
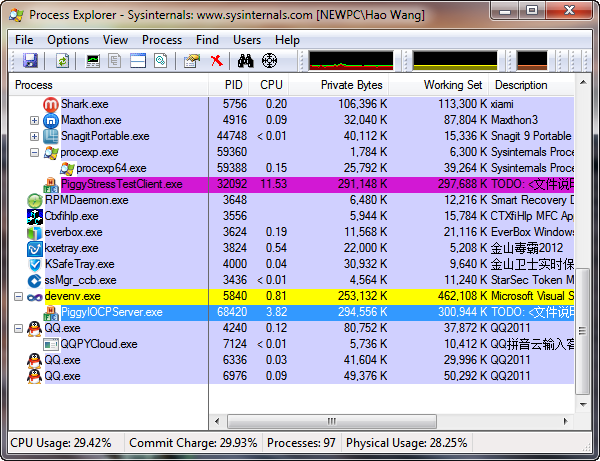
我們可以發現一個令人驚訝的結果,採用了完成埠的Server程式(藍色橫線所示)所佔用的CPU才為 3.82%,整個執行過程中的峰值也沒有超過4%,是相當氣定神閒的……哦,對了,這還是在Debug環境下執行的情況,如果採用Release方式執行,效能肯定還會更高一些,除此以外,在UI上顯示資訊也很大成都上影響了效能。
相反採用了多個併發執行緒的Client程式(紫色橫線所示)居然佔用的CPU高達11.53%,甚至超過了Server程式的數倍……
其實無論是哪種網路操模型,對於記憶體佔用都是差不多的,真正的差別就在於CPU的佔用,其他的網路模型都需要更多的CPU動力來支撐同樣的連線資料。
雖然這遠遠算不上伺服器極限壓力測試,但是從中也可以看出來完成埠的實力,而且這種方式比純粹靠多執行緒的方式實現併發資源佔用率要低得多。
三. 完成埠的相關概念
在開始編碼之前,我們先來討論一下和完成埠相關的一些概念,如果你沒有耐心看完這段大段的文字的話,也可以跳過這一節直接去看下下一節的具體實現部分,但是這一節中涉及到的基本概念你還是有必要了解一下的,而且你也更能知道為什麼有那麼多的網路程式設計模式不用,非得要用這麼又複雜又難以理解的完成埠呢??也會堅定你繼續學習下去的信心^_^
3.1 非同步通訊機制及其幾種實現方式的比較
我們從前面的文字中瞭解到,高效能伺服器程式使用非同步通訊機制是必須的。
而對於非同步的概念,為了方便後面文字的理解,這裡還是再次簡單的描述一下:
非同步通訊就是在咱們與外部的I/O裝置進行打交道的時候,我們都知道外部裝置的I/O和CPU比起來簡直是龜速,比如硬碟讀寫、網路通訊等等,我們沒有必要在咱們自己的執行緒裡面等待著I/O操作完成再執行後續的程式碼,而是將這個請求交給裝置的驅動程式自己去處理,我們的執行緒可以繼續做其他更重要的事情,大體的流程如下圖所示:
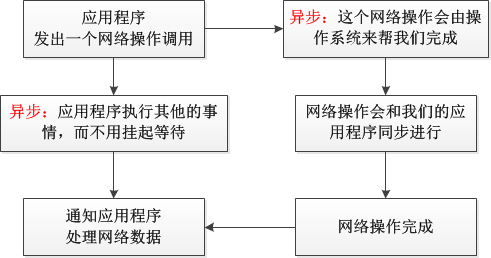
我可以從圖中看到一個很明顯的並行操作的過程,而“同步”的通訊方式是在進行網路操作的時候,主執行緒就掛起了,主執行緒要等待網路操作完成之後,才能繼續執行後續的程式碼,就是說要麼執行主執行緒,要麼執行網路操作,是沒法這樣並行的;
“非同步”方式無疑比 “阻塞模式+多執行緒”的方式效率要高的多,這也是前者為什麼叫“非同步”,後者為什麼叫“同步”的原因了,因為不需要等待網路操作完成再執行別的操作。
而在Windows中實現非同步的機制同樣有好幾種,而這其中的區別,關鍵就在於圖1中的最後一步“通知應用程式處理網路資料”上了,因為實現作業系統呼叫裝置驅動程式去接收資料的操作都是一樣的,關鍵就是在於如何去通知應用程式來拿資料。它們之間的具體區別我這裡多講幾點,文字有點多,如果沒興趣深入研究的朋友可以跳過下一面的這一段,不影響的:)
(1) 裝置核心物件,使用裝置核心物件來協調資料的傳送請求和接收資料協調,也就是說通過設定裝置核心物件的狀態,在裝置接收資料完成後,馬上觸發這個核心物件,然後讓接收資料的執行緒收到通知,但是這種方式太原始了,接收資料的執行緒為了能夠知道核心物件是否被觸發了,還是得不停的掛起等待,這簡直是根本就沒有用嘛,太低階了,有木有?所以在這裡就略過不提了,各位讀者要是沒明白是怎麼回事也不用深究了,總之沒有什麼用。
(2) 事件核心物件,利用事件核心物件來實現I/O操作完成的通知,其實這種方式其實就是我以前寫文章的時候提到的《基於事件通知的重疊I/O模型》,連結在這裡,這種機制就先進得多,可以同時等待多個I/O操作的完成,實現真正的非同步,但是缺點也是很明顯的,既然用WaitForMultipleObjects()來等待Event的話,就會受到64個Event等待上限的限制,但是這可不是說我們只能處理來自於64個客戶端的Socket,而是這是屬於在一個裝置核心物件上等待的64個事件核心物件,也就是說,我們在一個執行緒內,可以同時監控64個重疊I/O操作的完成狀態,當然我們同樣可以使用多個執行緒的方式來滿足無限多個重疊I/O的需求,比如如果想要支援3萬個連線,就得需要500多個執行緒…用起來太麻煩讓人感覺不爽;
(3) 使用APC( Asynchronous Procedure Call,非同步過程呼叫)來完成,這個也就是我以前在文章裡提到的《基於完成例程的重疊I/O模型》,連結在這裡,這種方式的好處就是在於擺脫了基於事件通知方式的64個事件上限的限制,但是缺點也是有的,就是發出請求的執行緒必須得要自己去處理接收請求,哪怕是這個執行緒發出了很多傳送或者接收資料的請求,但是其他的執行緒都閒著…,這個執行緒也還是得自己來處理自己發出去的這些請求,沒有人來幫忙…這就有一個負載均衡問題,顯然效能沒有達到最優化。
(4) 完成埠,不用說大家也知道了,最後的壓軸戲就是使用完成埠,對比上面幾種機制,完成埠的做法是這樣的:事先開好幾個執行緒,你有幾個CPU我就開幾個,首先是避免了執行緒的上下文切換,因為執行緒想要執行的時候,總有CPU資源可用,然後讓這幾個執行緒等著,等到有使用者請求來到的時候,就把這些請求都加入到一個公共訊息佇列中去,然後這幾個開好的執行緒就排隊逐一去從訊息佇列中取出訊息並加以處理,這種方式就很優雅的實現了非同步通訊和負載均衡的問題,因為它提供了一種機制來使用幾個執行緒“公平的”處理來自於多個客戶端的輸入/輸出,並且執行緒如果沒事幹的時候也會被系統掛起,不會佔用CPU週期,挺完美的一個解決方案,不是嗎?哦,對了,這個關鍵的作為交換的訊息佇列,就是完成埠。
比較完畢之後,熟悉網路程式設計的朋友可能會問到,為什麼沒有提到WSAAsyncSelect或者是WSAEventSelect這兩個非同步模型呢,對於這兩個模型,我不知道其內部是如何實現的,但是這其中一定沒有用到Overlapped機制,就不能算作是真正的非同步,可能是其內部自己在維護一個訊息佇列吧,總之這兩個模式雖然實現了非同步的接收,但是卻不能進行非同步的傳送,這就很明顯說明問題了,我想其內部的實現一定和完成埠是迥異的,並且,完成埠非常厚道,因為它是先把使用者資料接收回來之後再通知使用者直接來取就好了,而WSAAsyncSelect和WSAEventSelect之流只是會接收到資料到達的通知,而只能由應用程式自己再另外去recv資料,效能上的差距就更明顯了。
最後,我的建議是,想要使用 基於事件通知的重疊I/O和基於完成例程的重疊I/O的朋友,如果不是特別必要,就不要去使用了,因為這兩種方式不僅使用和理解起來也不算簡單,而且還有效能上的明顯瓶頸,何不就再努力一下使用完成埠呢?
3.2 重疊結構(OVERLAPPED)
我們從上一小節中得知,要實現非同步通訊,必須要用到一個很風騷的I/O資料結構,叫重疊結構“Overlapped”,Windows裡所有的非同步通訊都是基於它的,完成埠也不例外。
至於為什麼叫Overlapped?Jeffrey Richter的解釋是因為“執行I/O請求的時間與執行緒執行其他任務的時間是重疊(overlapped)的”,從這個名字我們也可能看得出來重疊結構發明的初衷了,對於重疊結構的內部細節我這裡就不過多的解釋了,就把它當成和其他核心物件一樣,不需要深究其實現機制,只要會使用就可以了,想要了解更多重疊結構內部的朋友,請去翻閱Jeffrey Richter的《Windows via C/C++》 5th 的292頁,如果沒有機會的話,也可以隨便翻翻我以前寫的Overlapped的東西,不過寫得比較淺顯……
這裡我想要解釋的是,這個重疊結構是非同步通訊機制實現的一個核心資料結構,因為你看到後面的程式碼你會發現,幾乎所有的網路操作例如傳送/接收之類的,都會用WSASend()和WSARecv()代替,引數裡面都會附帶一個重疊結構,這是為什麼呢?因為重疊結構我們可以理解成為是一個網路操作的ID號,也就是說我們要利用重疊I/O提供的非同步機制的話,每一個網路操作都要有一個唯一的ID號,因為進了系統核心,裡面黑燈瞎火的,也不瞭解上面出了什麼狀況,一看到有重疊I/O的呼叫進來了,就會使用其非同步機制,並且作業系統就只能靠這個重疊結構帶有的ID號來區分是哪一個網路操作了,然後核心裡面處理完畢之後,根據這個ID號,把對應的資料傳上去。
你要是實在不理解這是個什麼玩意,那就直接看後面的程式碼吧,慢慢就明白了……
3.3 完成埠(CompletionPort)
對於完成埠這個概念,我一直不知道為什麼它的名字是叫“完成埠”,我個人的感覺應該叫它“完成佇列”似乎更合適一些,總之這個“埠”和我們平常所說的用於網路通訊的“埠”完全不是一個東西,我們不要混淆了。
首先,它之所以叫“完成”埠,就是說系統會在網路I/O操作“完成”之後才會通知我們,也就是說,我們在接到系統的通知的時候,其實網路操作已經完成了,就是比如說在系統通知我們的時候,並非是有資料從網路上到來,而是來自於網路上的資料已經接收完畢了;或者是客戶端的連入請求已經被系統接入完畢了等等,我們只需要處理後面的事情就好了。
各位朋友可能會很開心,什麼?已經處理完畢了才通知我們,那豈不是很爽?其實也沒什麼爽的,那是因為我們在之前給系統分派工作的時候,都囑咐好了,我們會通過程式碼告訴系統“你給我做這個做那個,等待做完了再通知我”,只是這些工作是做在之前還是之後的區別而已。
其次,我們需要知道,所謂的完成埠,其實和HANDLE一樣,也是一個核心物件,雖然Jeff Richter嚇唬我們說:“完成埠可能是最為複雜的核心物件了”,但是我們也不用去管他,因為它具體的內部如何實現的和我們無關,只要我們能夠學會用它相關的API把這個完成埠的框架搭建起來就可以了。我們暫時只用把它大體理解為一個容納網路通訊操作的佇列就好了,它會把網路操作完成的通知,都放在這個佇列裡面,咱們只用從這個佇列裡面取就行了,取走一個就少一個…。
關於完成埠核心物件的具體更多內部細節我會在後面的“完成埠的基本原理”一節更詳細的和朋友們一起來研究,當然,要是你們在文章中沒有看到這一節的話,就是說明我又犯懶了沒寫…在後續的文章裡我會補上。這裡就暫時說這麼多了,到時候我們也可以看到它的機制也並非有那麼的複雜,可能只是因為作業系統其他的核心物件相比較而言實現起來太容易了吧^_^
四. 使用完成埠的基本流程
說了這麼多的廢話,大家都等不及了吧,我們終於到了具體編碼的時候了。
使用完成埠,說難也難,但是說簡單,其實也簡單 ---- 又說了一句廢話=。=
大體上來講,使用完成埠只用遵循如下幾個步驟:
(1) 呼叫 CreateIoCompletionPort() 函式建立一個完成埠,而且在一般情況下,我們需要且只需要建立這一個完成埠,把它的控制代碼儲存好,我們今後會經常用到它……
(2) 根據系統中有多少個處理器,就建立多少個工作者(為了醒目起見,下面直接說Worker)執行緒,這幾個執行緒是專門用來和客戶端進行通訊的,目前暫時沒什麼工作;
(3) 下面就是接收連入的Socket連線了,這裡有兩種實現方式:一是和別的程式設計模型一樣,還需要啟動一個獨立的執行緒,專門用來accept客戶端的連線請求;二是用效能更高更好的非同步AcceptEx()請求,因為各位對accept用法應該非常熟悉了,而且網上資料也會很多,所以為了更全面起見,本文采用的是效能更好的AcceptEx,至於兩者程式碼編寫上的區別,我接下來會詳細的講。
(4) 每當有客戶端連入的時候,我們就還是得呼叫CreateIoCompletionPort()函式,這裡卻不是新建立完成埠了,而是把新連入的Socket(也就是前面所謂的裝置控制代碼),與目前的完成埠繫結在一起。
至此,我們其實就已經完成了完成埠的相關部署工作了,嗯,是的,完事了,後面的程式碼裡我們就可以充分享受完成埠帶給我們的巨大優勢,坐享其成了,是不是很簡單呢?
(5) 例如,客戶端連入之後,我們可以在這個Socket上提交一個網路請求,例如WSARecv(),然後系統就會幫咱們乖乖的去執行接收資料的操作,我們大可以放心的去幹別的事情了;
(6) 而此時,我們預先準備的那幾個Worker執行緒就不能閒著了, 我們在前面建立的幾個Worker就要忙活起來了,都需要分別呼叫GetQueuedCompletionStatus() 函式在掃描完成埠的佇列裡是否有網路通訊的請求存在(例如讀取資料,傳送資料等),一旦有的話,就將這個請求從完成埠的佇列中取回來,繼續執行本執行緒中後面的處理程式碼,處理完畢之後,我們再繼續投遞下一個網路通訊的請求就OK了,如此迴圈。
關於完成埠的使用步驟,用文字來表述就是這麼多了,很簡單吧?如果你還是不理解,我再配合一個流程圖來表示一下:
當然,我這裡假設你已經對網路程式設計的基本套路有了解了,所以略去了很多基本的細節,並且為了配合朋友們更好的理解我的程式碼,在流程圖我標出了一些函式的名字,並且畫得非常詳細。
另外需要注意的是由於對於客戶端的連入有兩種方式,一種是普通阻塞的accept,另外一種是效能更好的AcceptEx,為了能夠方面朋友們從別的網路程式設計的方式中過渡,我這裡畫了兩種方式的流程圖,方便朋友們對比學習,圖a是使用accept的方式,當然配套的原始碼我預設就不提供了,如果需要的話,我倒是也可以發上來;圖b是使用AcceptEx的,並配有配套的原始碼。
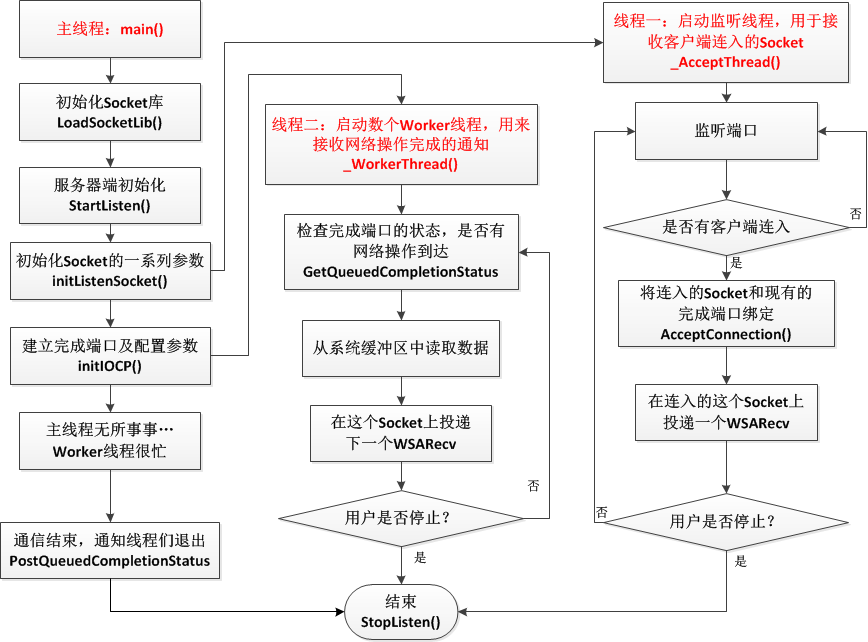
採用accept方式的流程示意圖如下:
採用AcceptEx方式的流程示意圖如下:
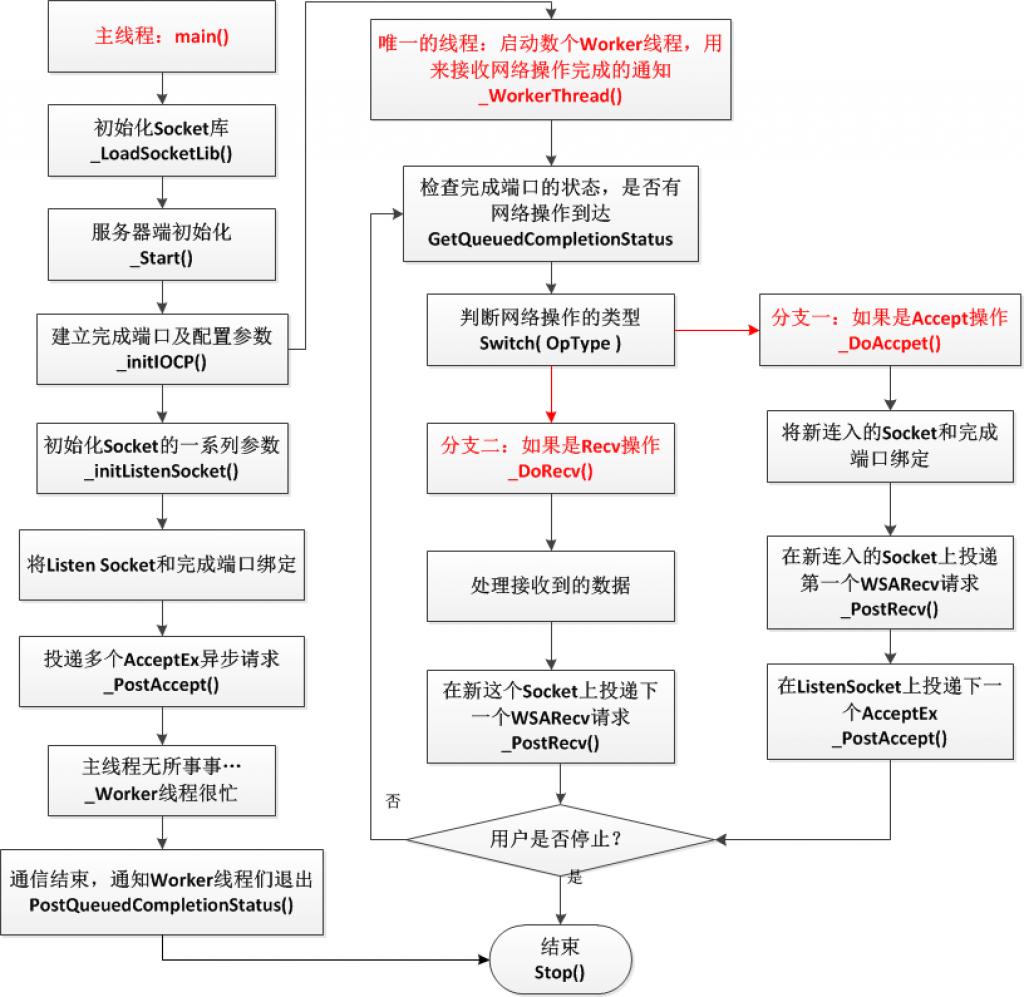
兩個圖中最大的相同點是什麼?是的,最大的相同點就是主執行緒無所事事,閒得蛋疼……
為什麼呢?因為我們使用了非同步的通訊機制,這些瑣碎重複的事情完全沒有必要交給主執行緒自己來做了,只用在初始化的時候和Worker執行緒交待好就可以了,用一句話來形容就是,主執行緒永遠也體會不到Worker執行緒有多忙,而Worker執行緒也永遠體會不到主執行緒在初始化建立起這個通訊框架的時候操了多少的心……
圖a中是由 _AcceptThread()負責接入連線,並把連入的Socket和完成埠繫結,另外的多個_WorkerThread()就負責監控完成埠上的情況,一旦有情況了,就取出來處理,如果CPU有多核的話,就可以多個執行緒輪著來處理完成埠上的資訊,很明顯效率就提高了。
圖b中最明顯的區別,也就是AcceptEx和傳統的accept之間最大的區別,就是取消了阻塞方式的accept呼叫,也就是說,AcceptEx也是通過完成埠來非同步完成的,所以就取消了專門用於accept連線的執行緒,用了完成埠來進行非同步的AcceptEx呼叫;然後在檢索完成埠佇列的Worker函式中,根據使用者投遞的完成操作的型別,再來找出其中的投遞的Accept請求,加以對應的處理。
讀者一定會問,這樣做的好處在哪裡?為什麼還要非同步的投遞AcceptEx連線的操作呢?
首先,我可以很明確的告訴各位,如果短時間內客戶端的併發連線請求不是特別多的話,用accept和AcceptEx在效能上來講是沒什麼區別的。
按照我們目前主流的PC來講,如果客戶端只進行連線請求,而什麼都不做的話,我們的Server只能接收大約3萬-4萬個左右的併發連線,然後客戶端其餘的連入請求就只能收到WSAENOBUFS (10055)了,因為系統來不及為新連入的客戶端準備資源了。
需要準備什麼資源?當然是準備Socket了……雖然我們建立Socket只用一行SOCKET s= socket(…) 這麼一行的程式碼就OK了,但是系統內部建立一個Socket是相當耗費資源的,因為Winsock2是分層的機構體系,建立一個Socket需要到多個Provider之間進行處理,最終形成一個可用的套接字。總之,系統建立一個Socket的開銷是相當高的,所以用accept的話,系統可能來不及為更多的併發客戶端現場準備Socket了。
而AcceptEx比Accept又強大在哪裡呢?是有三點:
(1) 這個好處是最關鍵的,是因為AcceptEx是在客戶端連入之前,就把客戶端的Socket建立好了,也就是說,AcceptEx是先建立的Socket,然後才發出的AcceptEx呼叫,也就是說,在進行客戶端的通訊之前,無論是否有客戶端連入,Socket都是提前建立好了;而不需要像accept是在客戶端連入了之後,再現場去花費時間建立Socket。如果各位不清楚是如何實現的,請看後面的實現部分。
(2) 相比accept只能阻塞方式建立一個連入的入口,對於大量的併發客戶端來講,入口實在是有點擠;而AcceptEx可以同時在完成埠上投遞多個請求,這樣有客戶端連入的時候,就非常優雅而且從容不迫的邊喝茶邊處理連入請求了。
(3) AcceptEx還有一個非常體貼的優點,就是在投遞AcceptEx的時候,我們還可以順便在AcceptEx的同時,收取客戶端發來的第一組資料,這個是同時進行的,也就是說,在我們收到AcceptEx完成的通知的時候,我們就已經把這第一組資料接完畢了;但是這也意味著,如果客戶端只是連入但是不傳送資料的話,我們就不會收到這個AcceptEx完成的通知……這個我們在後面的實現部分,也可以詳細看到。
最後,各位要有一個心裡準備,相比accept,非同步的AcceptEx使用起來要麻煩得多……
五. 完成埠的實現詳解
又說了一節的廢話,終於到了該動手實現的時候了……
這裡我把完成埠的詳細實現步驟以及會涉及到的函式,按照出現的先後步驟,都和大家詳細的說明解釋一下,當然,文件中為了讓大家便於閱讀,這裡去掉了其中的錯誤處理的內容,當然,這些內容在示例程式碼中是會有的。
【第一步】建立一個完成埠
首先,我們先把完成埠建好再說。
我們正常情況下,我們需要且只需要建立這一個完成埠,程式碼很簡單:
- HANDLE m_hIOCompletionPort = CreateIoCompletionPort(INVALID_HANDLE_VALUE, NULL, 0, 0 );
呵呵,看到CreateIoCompletionPort()的引數不要奇怪,引數就是一個INVALID,一個NULL,兩個0…,說白了就是一個-1,三個0……簡直就和什麼都沒傳一樣,但是Windows系統內部卻是好一頓忙活,把完成埠相關的資源和資料結構都已經定義好了(在後面的原理部分我們會看到,完成埠相關的資料結構大部分都是一些用來協調各種網路I/O的佇列),然後系統會給我們返回一個有意義的HANDLE,只要返回值不是NULL,就說明建立完成埠成功了,就這麼簡單,不是嗎?
有的時候我真的很讚歎Windows API的封裝,把很多其實是很複雜的事整得這麼簡單……
至於裡面各個引數的具體含義,我會放到後面的步驟中去講,反正這裡只要知道建立我們唯一的這個完成埠,就只是需要這麼幾個引數。
但是對於最後一個引數 0,我這裡要簡單的說兩句,這個0可不是一個普通的0,它代表的是NumberOfConcurrentThreads,也就是說,允許應用程式同時執行的執行緒數量。當然,我們這裡為了避免上下文切換,最理想的狀態就是每個處理器上只執行一個執行緒了,所以我們設定為0,就是說有多少個處理器,就允許同時多少個執行緒執行。
因為比如一臺機器只有兩個CPU(或者兩個核心),如果讓系統同時執行的執行緒多於本機的CPU數量的話,那其實是沒有什麼意義的事情,因為這樣CPU就不得不在多個執行緒之間執行上下文切換,這會浪費寶貴的CPU週期,反而降低的效率,我們要牢記這個原則。
【第二步】根據系統中CPU核心的數量建立對應的Worker執行緒
我們前面已經提到,這個Worker執行緒很重要,是用來具體處理網路請求、具體和客戶端通訊的執行緒,而且對於執行緒數量的設定很有意思,要等於系統中CPU的數量,那麼我們就要首先獲取系統中CPU的數量,這個是基本功,我就不多說了,程式碼如下:
- SYSTEM_INFO si;
- GetSystemInfo(&si);
- int m_nProcessors = si.dwNumberOfProcessors;
這樣我們根據系統中CPU的核心數量來建立對應的執行緒就好了,下圖是在我的 i7 2600k CPU上初始化的情況,因為我的CPU是8核,一共啟動了16個Worker執行緒,如下圖所示
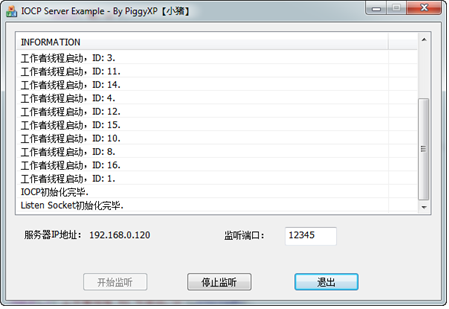
啊,等等!各位沒發現什麼問題麼?為什麼我8核的CPU卻啟動了16個執行緒?這個不是和我們第二步中說的原則自相矛盾了麼?
哈哈,有個小祕密忘了告訴各位了,江湖上都流傳著這麼一個公式,就是:
我們最好是建立CPU核心數量*2那麼多的執行緒,這樣更可以充分利用CPU資源,因為完成埠的排程是非常智慧的,比如我們的Worker執行緒有的時候可能會有Sleep()或者WaitForSingleObject()之類的情況,這樣同一個CPU核心上的另一個執行緒就可以代替這個Sleep的執行緒執行了;因為完成埠的目標是要使得CPU滿負荷的工作。
這裡也有人說是建立 CPU“核心數量 * 2 +2”個執行緒,我想這個應該沒有什麼太大的區別,我就是按照我自己的習慣來了。
然後按照這個數量,來啟動這麼多個Worker執行緒就好可以了,接下來我們開始下一個步驟。
什麼?Worker執行緒不會建?
…囧…
Worker執行緒和普通執行緒是一樣一樣一樣的啊~~~,程式碼大致上如下:
- // 根據CPU數量,建立*2的執行緒
- m_nThreads = 2 * m_nProcessors;
- HANDLE* m_phWorkerThreads = newHANDLE[m_nThreads];
- for (int i = 0; i < m_nThreads; i++)
- {
- m_phWorkerThreads[i] = ::CreateThread(0, 0, _WorkerThread, …);
- }
其中,_WorkerThread是Worker執行緒的執行緒函式,執行緒函式的具體內容我們後面再講。
【第三步】建立一個用於監聽的Socket,繫結到完成埠上,然後開始在指定的埠上監聽連線請求
最重要的完成埠建立完畢了,我們就可以利用這個完成埠來進行網路通訊了。
首先,我們需要初始化Socket,這裡和通常情況下使用Socket初始化的步驟都是一樣的,大約就是如下的這麼幾個過程(詳情參照我程式碼中的LoadSocketLib()和InitializeListenSocket(),這裡只是挑出關鍵部分):
- // 初始化Socket庫
- WSADATA wsaData;
- WSAStartup(MAKEWORD(2,2), &wsaData);
- //初始化Socket
- struct sockaddr_in ServerAddress;
- // 這裡需要特別注意,如果要使用重疊I/O的話,這裡必須要使用WSASocket來初始化Socket
- // 注意裡面有個WSA_FLAG_OVERLAPPED引數
-
相關推薦
Windows伺服器高併發處理IOCP(完成埠)詳細說明
本系列裡完成埠的程式碼在兩年前就已經寫好了,但是由於許久沒有寫東西了,不知該如何提筆,所以這篇文件總是在醞釀之中……醞釀了兩年之後,終於決定開始動筆了,但願還不算晚….. 這篇文件我非常詳細並且圖文並茂的介紹了關於網路程式設計模型中完成埠的方方面
在c#多執行緒使用IOCP(完成埠)的簡單示例
在c#使用IOCP(完成埠)的簡單示例 上次給大家發了利用winsock原生的api來做一個同步的socket伺服器的例子,大致上只是貼了一些程式碼,相信大家這麼冰雪聰明,已經研究的差不多了。因為winsock的api使用在msdn或者google上都能很方便的查到,所以我
高併發解決方案(負載均衡)
1,什麼是負載均衡? 當一臺伺服器的效能達到極限時,我們可以使用伺服器叢集來提高網站的整體效能。那麼,在伺服器叢集中,需要有一臺伺服器充當排程者的角色,使用者的所有請求都會首先由它接收,排程者再根據每臺伺服器的負載情況將請求分配給某一臺後端伺服器去處理。 那麼在這個過程中,排程者如何合理分配
Java高併發解決方案(參考文)
對於我們開發的網站,如果網站的訪問量非常大的話,那麼我們就需要考慮相關的併發訪問問題了。而併發問題是絕大部分的程式設計師頭疼的問題,但話又說回來了,既然逃避不掉,那我們就坦然面對吧~今天就讓我們一起來研究一下常見的併發和同步吧。 為了更好的理解併發和同步,我們需要先明白兩個重要的概念:同步和
程式設計師修神之路--用NOSql給高併發系統加速(送書)
隨著網際網路大潮的到來,越來越多網站,應用系統需要海量資料的支撐,高併發、低延遲、高可用、高擴充套件等要求在傳統的關係型資料庫中已經得不到滿足,或者說關係型資料庫應對這些需求已經顯得力不從心了。關係型資料庫經過幾十年的發展已經很成熟,強大的sql語句支援,完美的ACID屬性的支援,使得關係型資料庫廣泛應用於
linux centos7 從零搭建Hadoop離線處理平臺(單機模式)詳細
hadoop下載網址 http://archive.cloudera.com/cdh5/cdh/5/cdh-5.7.0 1、關閉防火牆 #停止防火牆,重啟後失效 sudo systemctl stop firewalld.service #禁用防火牆,重啟後依然有效 sudo syst
高併發處理思路與手段(五):應用限流
限流就是通過對併發訪問/請求進行限速或一個時間視窗內的請求進行限速,從而達到保護系統的目的。一般系統可以通過壓測來預估能處理的峰值,一旦達到設定的峰值閥值,則可以拒絕服務(定向錯誤頁或告知資源沒有了)、排隊或等待(例如:秒殺、評論、下單)、降級(返回預設資料)。 限流不能亂用,否則正常流量會出現一些奇怪的問
伺服器端接受多個請求時的高併發處理
同步服務為每個請求建立單一執行緒,由此執行緒完成整個請求的處理:接收訊息,處理訊息,返回資料;這種情況下伺服器資源對所有入棧請求開放,伺服器資源被所有入棧請求競爭使用,如果入棧請求過多就會導致伺服器資源耗盡宕機,或者導致競爭加劇,資源排程頻繁,伺服器資源利用效率降低。 非同步服務則可以分別設定兩個執行緒佇列
python爬蟲進階(八):分散式系統的高可用與高併發處理
一、應對高併發的基本思路 1、加快單機的速度,例如使用Redis,提高資料訪問頻率;增加CPU的核心數,增大記憶體; 2、增加伺服器的數量,利用叢集。 二、分散式系統的設計 1、無狀態 應用本身沒有狀態,狀態全部通過配置檔案或者叢集的服務端提供並與之同步。比如不同
Python實戰之協程(greenlet模組,gevent模組,socket+ gevent實現高併發處理)
協程 協程,又稱微執行緒,纖程。英文名Coroutine。一句話說明什麼是執行緒:協程是一種使用者態的輕量級執行緒。(cpu不知道,是使用者自己控制的) 協程擁有自己的暫存器上下文和棧。協程排程切換時,將暫存器上下文和棧儲存到其他地方,在切回來的時候,恢復先前儲存的暫存器上下文和棧(執行緒的
高併發處理系統的理解---資料一致性(還有一點問題)
伺服器配置資料庫設計以及優化快取資料一致性處理 伺服器配置: 叢集的環境,每個主機選擇apahe 還是nginx,nignx的併發性好。nginx和apche區別 以及伺服器的配置,例如快取大小等 根據實際情況,可能對於影象比較多的情況,單
一個簡單的IOCP(IO完成埠)伺服器/客戶端類(英文版)
1.1 Requirements The article expects the reader to be familiar with C++, TCP/IP, socket programming, MFC, and multithreading.The source code uses Winsoc
Volley高併發處理網路請求(No2)
public class MainActivity extends AppCompatActivity { private ImageView image; @Override protected void onCreate(Bundle savedInstanceState) {
一個簡單的IOCP(IO完成埠)伺服器/客戶端類(中文版)
一個簡單的IOCP(IO完成埠)伺服器/客戶端類 ——A simple IOCP Server/Client Class By spinoza 原文【選自CodeProject】 原始碼: ——譯: Ocean Email: [email protect
windows伺服器下使用nginx 基礎(一)
windows nginx 安裝 nginx 手機端訪問 https 問題:為什麼使用windows伺服器,因為不會linux。為什麼使用node做伺
Redis的快取高併發處理
Springboot 整合Redis,快取過期之後,如果多個執行緒同時請求對某個資料的訪問,會同時去到資料庫,導致資料庫瞬間負荷增高。 解決辦法: ①Spring4.3為@Cacheable註解提供了一個新的引數“sync”(boolean型別,預設為false),當設定它為true時,
高併發的實現(非同步化+快取+多執行緒)
一年前,本人有幸負責公司核心專案的優化。隨著公司業務的增長,專案處理量也越來越大。 一次818大促甚至導致一臺伺服器滿負荷運作。於是,高併發改造被提上行程。 乾貨開始: 技術實現上有三個重點:非同步化(一般使用mq)、快取(一般使用redis)、多執行緒 一個功能併發量上大的提升,是需要業務
Nginx高併發處理
#user nobody; #nginx程序數,建議按照cpu數目來指定,一般跟cpu核數相同或為它的倍數。 worker_processes 18; #下面這個指令是指當一個nginx程序開啟的最多檔案描述符數目,理論值應該是系統的最多開啟檔案數(ulimit -n)與nginx程序數相除,但是n
Java併發程式設計和高併發學習總結(一)-大綱
系列 開篇語 想寫這樣一個東西很久了,在慕課網上學完某老師的課程(避免打廣告的嫌疑就不貼出來了,感興趣的同學可以去慕課網上去搜來看看,是個付費課程)之後就覺得應該有這樣的一個學習總結的東西來,後來因為懶又有其他事情耽誤了,然後又上了新專案(正好拿來練手了,當然
高併發負載均衡(一)——企業架構分析和DNS
最近研究了幾個關於阿里研究院對於高併發的解決方案,總結一下,漲漲姿勢。 企業級web專案架構圖 1、客戶端通過企業防火牆傳送請求 2、在App伺服器如tomcat接收客戶端請求前,面對高併發大資料量訪問的企業架構,會通過加入負載均衡主備伺服器將請求進行轉發到不