
Android原始碼解析——LruCache
我認為在寫涉及到資料結構或演算法的實現類的原始碼解析部落格時,不應該急於講它的使用或馬上展開對原始碼的解析,而是要先交待一下這個資料結構或演算法的資料,瞭解它的設計,再從它的設計出發去講如何實現,最後從實現的角度來講回原始碼,才能深入理解。這是最新讀了一些部落格之後的思考。對此問題如果你有其他見解,歡迎留言交流。
LRU
在讀LruCache原始碼之前,我們先來了解一下這裡的Lru是什麼。LRU全稱為Least Recently Used,即最近最少使用,是一種快取置換演算法。我們的快取容量是有限的,它會面臨一個問題:當有新的內容需要加入我們的快取,但我們的快取空閒的空間不足以放進新的內容時,如何捨棄原有的部分內容從而騰出空間用來放新的內容。解決這個問題的演算法有多種,比如LRU,LFU,FIFO等。
需要注意區分的是LRU
LFU。前者是最近最少使用,即淘汰最長時間未使用的物件;後者是最近最不常使用,即淘汰一段時間內使用最少的物件。比如我們快取物件的順序是:A B C B D A C A ,當需要淘汰一個物件時,如果採用LRU演算法,則淘汰的是B,因為它是最長時間未被使用的。如果採用LFU演算法,則淘汰的是D,因為在這段時間內它只被使用了一次,是最不經常使用的。 瞭解了
LRU之後,我們再來看一下LruCache是如何實現的。
LinkedHashMap
我們看一下LruCache的結構,它的成員變數及構造方法定義如下(這裡分析的是android-23裡的程式碼):
private final 從上面的定義中會發現,LruCache進行快取的內容是放在LinkedHashMap物件當中的。那麼,LinkedHashMap是什麼?它是怎麼實現LRU這種快取策略的?
LinkedHashMap繼承自HashMap,不同的是,它是一個雙向迴圈連結串列,它的每一個數據結點都有兩個指標,分別指向直接前驅和直接後繼,這一個我們可以從它的內部類LinkedEntry中看出,其定義如下:
static class LinkedEntry<K, V> extends HashMapEntry<K, V> {
LinkedEntry<K, V> nxt;
LinkedEntry<K, V> prv;
/** Create the header entry */
LinkedEntry() {
super(null, null, 0, null);
nxt = prv = this;
}
/** Create a normal entry */
LinkedEntry(K key, V value, int hash, HashMapEntry<K, V> next,
LinkedEntry<K, V> nxt, LinkedEntry<K, V> prv) {
super(key, value, hash, next);
this.nxt = nxt;
this.prv = prv;
}
}LinkedHashMap實現了雙向迴圈連結串列的資料結構,它的定義如下:
public class LinkedHashMap<K, V> extends HashMap<K, V> {
transient LinkedEntry<K, V> header;
private final boolean accessOrder;
}當連結串列不為空時,header.nxt指向第一個結點,header.prv指向最後一個結點;當連結串列為空時,header.nxt與header.prv都指向它本身。
accessOrder是指定它的排序方式,當它為false時,只按插入的順序排序,即新放入的順序會在連結串列的尾部;而當它為true時,更新或訪問某個節點的資料時,這個對應的結點也會被放到尾部。它通過構造方法public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)來賦值。
我們來看一下加入一個新結點時的方法執行過程:
@Override void addNewEntry(K key, V value, int hash, int index) {
LinkedEntry<K, V> header = this.header;
// Remove eldest entry if instructed to do so.
LinkedEntry<K, V> eldest = header.nxt;
if (eldest != header && removeEldestEntry(eldest)) {
remove(eldest.key);
}
// Create new entry, link it on to list, and put it into table
LinkedEntry<K, V> oldTail = header.prv;
LinkedEntry<K, V> newTail = new LinkedEntry<K,V>(
key, value, hash, table[index], header, oldTail);
table[index] = oldTail.nxt = header.prv = newTail;
}可以看到,當加入一個新結點時,結構如下:
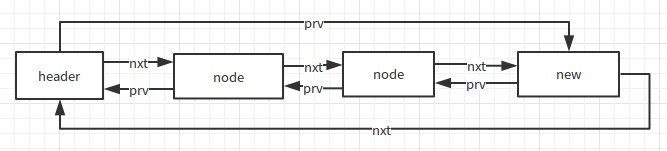
當accessOrder為true時,更新或者訪問一個結點時,它會把這個結點移到尾部,對應程式碼如下:
private void makeTail(LinkedEntry<K, V> e) {
// Unlink e
e.prv.nxt = e.nxt;
e.nxt.prv = e.prv;
// Relink e as tail
LinkedEntry<K, V> header = this.header;
LinkedEntry<K, V> oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
oldTail.nxt = header.prv = e;
modCount++;
}以上程式碼分為兩步,第一步是先把該節點取出來(Unlink e),如下圖:
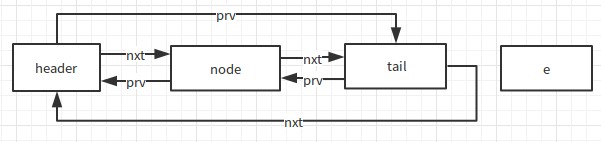
第二步是把這個這個結點移到尾部(Relink e as tail),也就是把舊的尾部的nxt以及頭部的prv指向它,並讓它的nxt指向頭部,把它的prv指向舊的尾部。如下圖:
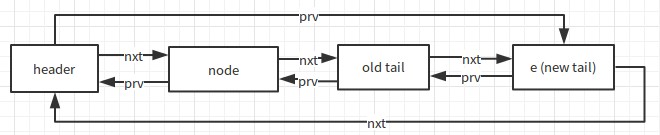
除此之外,LinkedHashMap還提供了一個方法public Entry<K, V> eldest(),它返回的是最老的結點,當accessOrder為true時,也就是最近最少使用的結點。
LruCache
熟悉了LinkedHashMap之後,我們發現,通過它來實現Lru演算法也就變得理所當然了。我們所需要做的,就只剩下定義快取的最大大小,記錄快取當前大小,在放入新資料時檢查是否超過最大大小。所以LruCache定義了以下三個必需的成員變數:
private final LinkedHashMap<K, V> map;
/** Size of this cache in units. Not necessarily the number of elements. */
private int size;
private int maxSize;然後我們來讀一下它的get方法:
public final V get(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
mapValue = map.get(key);
if (mapValue != null) {// 當能獲取到對應的值時,返回該值
hitCount++;
return mapValue;
}
missCount++;
}
/*
* Attempt to create a value. This may take a long time, and the map
* may be different when create() returns. If a conflicting value was
* added to the map while create() was working, we leave that value in
* the map and release the created value.
*/
//嘗試建立一個值,這個方法的預設實現是直接返回null。但是在它的設計中,這個方法可能執行完成之後map已經有了變化。
V createdValue = create(key);
if (createdValue == null) {//如果不為沒有命名的key建立新值,則直接返回
return null;
}
synchronized (this) {
createCount++;
//將建立的值放入map中,如果map在前面的過程中正好放入了這對key-value,那麼會返回放入的value
mapValue = map.put(key, createdValue);
if (mapValue != null) {//如果不為空,說明不需要我們所建立的值,所以又把返回的值放進去
// There was a conflict so undo that last put
map.put(key, mapValue);
} else {
size += safeSizeOf(key, createdValue);//為空,說明我們更新了這個key的值,需要重新計算大小
}
}
if (mapValue != null) {//上面放入的值有衝突
entryRemoved(false, key, createdValue, mapValue);// 通知之前建立的值已經被移除,而改為mapValue
return mapValue;
} else {
trimToSize(maxSize);//沒有衝突時,因為放入了新建立的值,大小已經有變化,所以需要修整大小
return createdValue;
}
}LruCache是可能被多個執行緒同時訪問的,所以在讀寫map時進行加鎖。當獲取不到對應的key的值時,它會呼叫其create(K key)方法,這個方法用於當快取沒有命名時計算一個key所對應的值,它的預設實現是直接返回null。這個方法並沒有加上同步鎖,也就是在它進行建立時,map可能已經有了變化。
所以在get方法中,如果create(key)返回的V不為null,會再把它給放到map中,並檢查是否在它建立的期間已經有其他物件也進行建立並放到map中了,如果有,則會放棄這個建立的物件,而把之前的物件留下,否則因為我們放入了新建立的值,所以要計算現在的大小並進行trimToSize。
trimToSize方法是根據傳進來的maxSize,如果當前大小超過了這個maxSize,則會移除最老的結點,直到不超過。程式碼如下:
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize) {
break;
}
Map.Entry<K, V> toEvict = map.eldest();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}接下來,我們再來看put方法,它的程式碼也很簡單:
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
size += safeSizeOf(key, value);
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
trimToSize(maxSize);
return previous;
}主要邏輯是,計算新增加的大小,加入size,然後把key-value放入map中,如果是更新舊的資料(map.put(key, value)會返回之前的value),則減去舊資料的大小,並呼叫entryRemoved(false, key, previous, value)方法通知舊資料被更新為新的值,最後也是呼叫trimToSize(maxSize)修整快取的大小。
剩下的其他方法,比如刪除裡面的物件,或進行調整大小的操作,邏輯上都和上面的類似,這裡略過。LruCache還定義了一些變數用於統計快取命中率等,這裡也不再進行贅述。
結語
LruCache的原始碼分析就到這裡,它對LRU演算法的實現主要是通過LinkedHashMap來完成。另外,使用LRU演算法,說明我們需要設定快取的最大大小,而快取物件的大小在不同的快取型別當中的計算方法是不同的,計算的方法通過protected int sizeOf(K key, V value)實現,這裡的預設實現是存放的元素的個數。舉個例子,如果我們要快取Bitmap物件,則需要重寫這個方法,並返回bitmap物件的所有畫素點所佔的記憶體大小之和。還有,LruCache在實現的時候考慮到了多執行緒的訪問問題,所以在對map進行更新時,都會加上同步鎖。
另外,囉嗦一句:LRU的快取策略由來已久,圖片快取也並非沒有策略,弱引用和軟引用更不是各種圖片框架沒流行之前的很常用的記憶體快取技術,垃圾回收機制更傾向於回收弱引用和軟引用物件的這種說法也是不妥當的。
友情校對:寒楓