
opencv影象識別技術在自動化測試中的應用
阿新 • • 發佈:2019-02-02
在自動化測試中,基於xpath、js選擇器、css選擇器進行元素定位及判定的技術已經比較成熟。在實際應用中,無論是web端還是移動端,仍有很多時候需要根據頁面內容、頁面中的影象進行定位及判定,這裡介紹一下基於opencv的影象識別技術在自動化測試中的應用。
這裡我們使用selenium驅動測試,使用opencv進行頁面元素判定。
OpenCV是一個基於BSD許可(開源)發行的跨平臺計算機視覺庫,可以執行在Linux、Windows和Mac OS作業系統上。它輕量級而且高效——由一系列 C 函式和少量 C++ 類構成,同時提供了Python、Ruby、MATLAB等語言的介面,實現了影象處理和計算機視覺方面的很多通用演算法。
0.基本步驟
在自動化測試中,我們預先對目標影象進行截圖,使用selenium驅動頁面訪問,使用xpath預先驗證指定元素是否存在,之後使用opencv的模板匹配對元素的內容進行驗證。
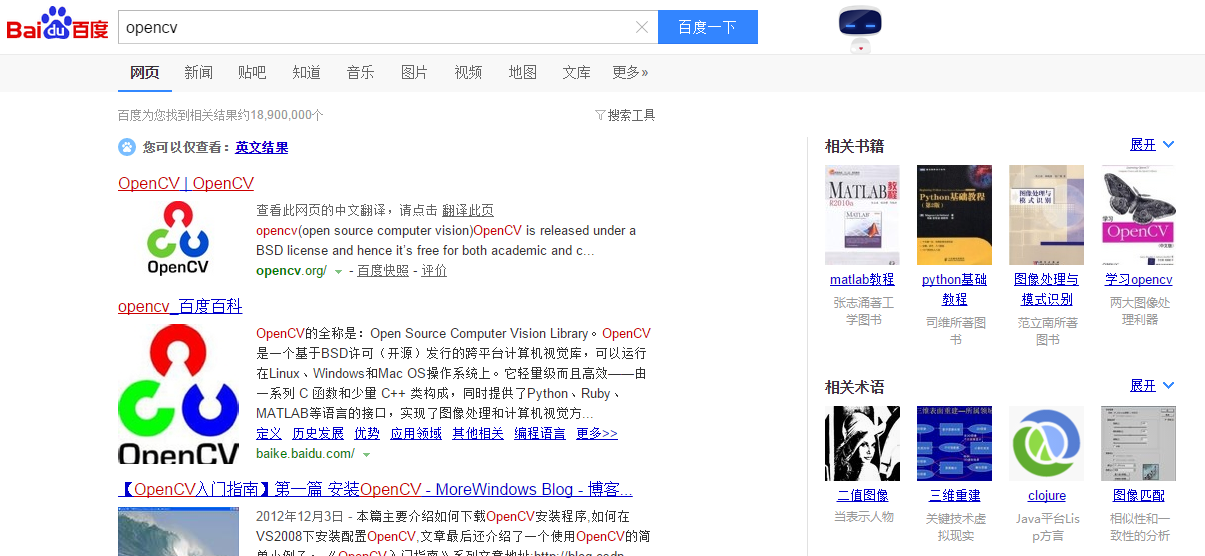
在示例中,我們使用百度搜索opencv,驗證搜尋結果中是否包含百度百科的詞條,以及百度百科詞條中opencv的logo是否存在。
1.測試環境:
Firefox v42.0
Python v2.7.10
Opencv v2.4.8
Numpy v1.8.1
Selenium v2.47.1
2.準備目標影象
使用baidu搜尋opencv,並對我們需要驗證的影象進行截圖。

3.使用selenium開啟baidu進行搜尋
browser = webdriver.Firefox() # Get local session of firefox browser.get("http://www.baidu.com") # Load page assert "百度" in browser.title elem = browser.find_element_by_id("kw") # Find the query box elem.send_keys("opencv" + Keys.RETURN) time.sleep(1) # Let the page load, will be added to the API
4.使用selenium驗證搜尋結果中是否含有百度百科詞條,這裡我們使用xpath進行驗證
try: browser.find_element_by_xpath("//h3/a[contains(text(),'_')]") #find baike in result page browser.save_screenshot('D://source.jpg') #save page except NoSuchElementException: assert 0, "can't find opencv element"
5.使用opencv驗證影象是否存在
sourcename = "D:/source.jpg" source = cv.LoadImage(sourcename) templatename="D:/template2.jpg" template=cv.LoadImage(templatename) W,H=cv.GetSize(source) w,h=cv.GetSize(template) width=W-w+1 height=H-h+1 result=cv.CreateImage((width,height),32,1) #result是一個矩陣,用於儲存模板與源影象每一幀相比較後的相似值 cv.MatchTemplate(source,template, result,cv.CV_TM_SQDIFF) #從矩陣中找到相似值最小的點,從而定位出模板位置 (min_x,max_y,minloc,maxloc)=cv.MinMaxLoc(result) (x,y)=minloc print min_x,max_y,minloc,maxloc assert (min_x<10000000), "can't find opencv image"
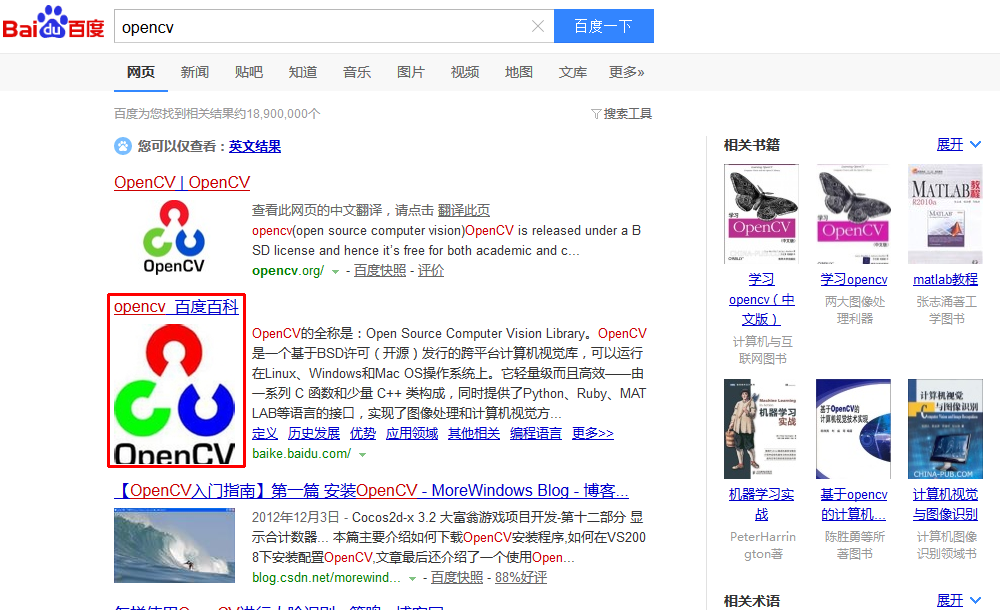
6.檢視驗證結果
在編寫指令碼過程中,由於實際的影象處理偏差,min_x的最大值需要根據具體影象進行不同的調整,校驗時,可以將影象識別的結果進行輸出,以便於檢視。
cv.Rectangle(source,(int(x),int(y)),(int(x)+w,int(y)+h),(0,0,255),2,0) #use red rectangle to notify the target cv.ShowImage("result", source) cv.WaitKey()
影象識別結果:
參考資料:
完整程式碼請參考: