
谷歌新一代WaveNet :深度學習怎麼生成語音? | 2分鐘論文
這裡是,雷鋒字幕組編譯的Two minutes paper專欄,每週帶大家用碎片時間閱覽前沿技術,瞭解AI領域的最新研究成果。
原標題 NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS | Two Minute Papers
翻譯 | 張鋒凱 整理 | 凡江 林尤添
在往期的2分鐘論文欄目中,我們有談過Google的WaveNet(一個基於學習型的文字到語音引擎),也就是說,只要我們給予已經訓練好的模型一些朗讀的素材,引擎就會盡可能生成一個較真實的聲音。而在本期視訊中,我們將介紹一個新的產品,它在原有的基礎上進行改進,讓合成語音臻於完美。
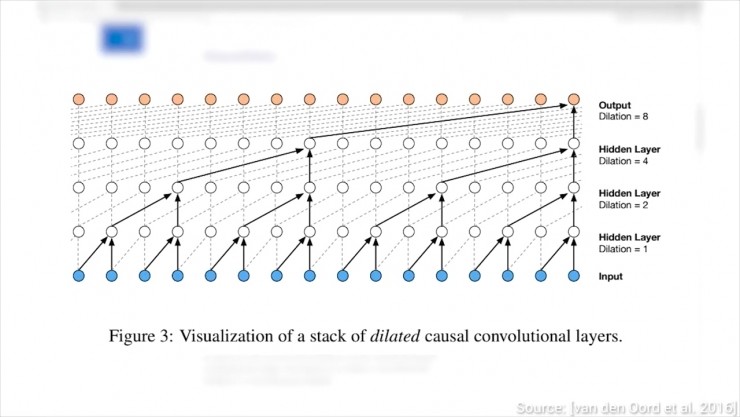
圖片來源:WaveNet: A Generative Model for Raw Audio
點開本期視訊後,你會聽到,合成的語音在韻律,重讀,和語調上都非常出色,以至於我們真假難辨。相關的音訊資訊可以在這裡找到:https://google.github.io/tacotron/publications/tacotron2/index.html
在原先Google的WaveNet論文中,我們為了解決語音合成難題,創造了擴張卷積,這個網路結構跳躍性地輸入資料,由此使我們我們有了更好的全域性視野。這有點像增加我們眼睛的感受野,讓我們能夠感受整個景觀,而不是照片中只有樹的狹窄的視角。
新框架利用梅爾聲譜作為WaveNet的輸入,這種聲譜是一種基於人類感知的中間媒介,它不僅記錄了不同的單詞如何發音,而且還記錄了預期的音量和語調。
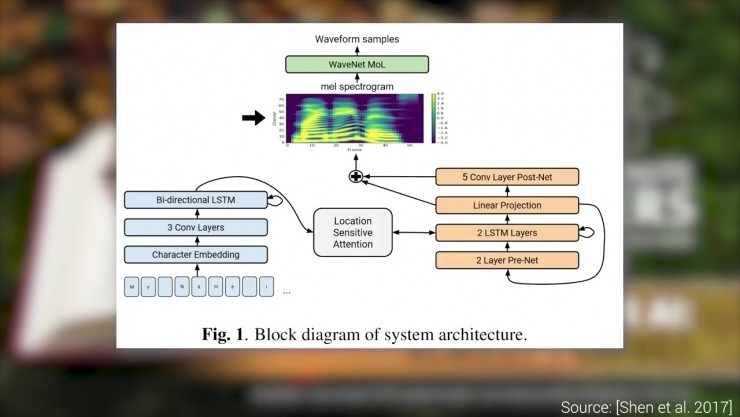
新模型接受了大約24小時的語音資料訓練,當然,模型都是要經過某種程度的檢驗才合格。
我們對其的檢驗方法是記錄以前演算法的平均意見分(用來描述聲音樣本和人類真實聲音的比分)。我們的新演算法大獲成功,之後通過使用者研究更加接地氣的檢驗,讓使用者進行盲測,猜測聽到的聲音是合成的還是真實的。

的確不可思議,因為大部分的測試結果都是——人們真假莫辨。
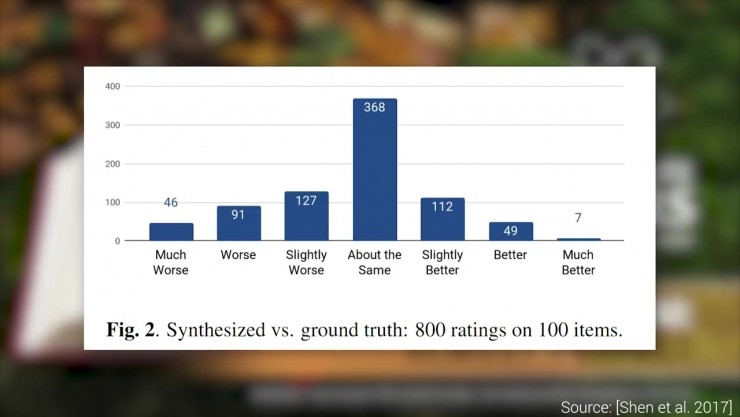
請注意,生成這些波形不是實時的,而且還需要很長時間。為了有更好的效率,DeepMind的科學家撰寫了一篇轟動的論文,把WaveNe的波形生成速度提升了上千倍。當然,新發明也會帶來新挑戰——這可能導致錄音更容易被偽造,而錄音將被削弱作為物證的可信性,除非我們找到一種新的檢驗方法,例如在錄音上加入數字簽名。
論文原址 https://arxiv.org/pdf/1712.05884.pdf
備註「我要加入」,To be a AI Volunteer !